【TransMEF】
基于transformer的多曝光融合框架TransMEF
传统多曝光融合
多曝光图像融合(MEF)技术通过将不同曝光的地动态范围LDR图像融合到单个高动态范围HDR图像中
基于空间域的融合方法
空间域方法直接从源图像的像素值计算融合图像的像素价值
常用方法:
基于像素的方法
基于补丁的方法
基于优化的方法
基于变换域的融合方法
在基于变换域的融合算法中,源图像首先转换到特定的变换域(如小波域)以获得不同的频率组件,然后使用适当的融合规则融合不同频率组件。最后,对融合后的频率分量进行逆变换,得到融合图像。
常用变换方法:
拉普拉斯金字塔
小波变换
金字塔变换
边缘保持平衡
基于深度学习的框架
在基于深度学习的算法中,两个源图像不同曝光量直接输入融合网络,网络输出融合图像通过在大型自然图像数据集上重建图像来训练网络
虽然目前的融合方法(有监督、无监督)可以进行多曝光融合,但是都需要大量多曝光的图片进行训练:但是收集了各种多重暴露数据集数量无法与大型自然图像数据集相比,导致数据不足
现有的其于深度学习的MEE方法利用卷和袖经网络(CNN)特征提取,但由于CNN的感受野较小,很难对长距离依赖进行建模------>TransMEF基于变压器的多曝光图像融合框架使用自我监督的多任务学习
TransMEF基于Transformer的多曝光图像融合
基于深度学习的MEF算法
在融合阶段,我们使用经过训练的编码器从一对源图像中提取特征地图
然后将两个特征地图融合并输入到解码器中,生成融合图像
训练流程图

训练流程
一个原图像变成三个被破坏了的图像(基于Gamma变换Fg 基于Fourier变换的Tf、基于global region shuffling变幻的Ts)输入到编码器中;
编码器由一个特征提取模块TransBlock和一个特征增强模块EnhanceBlock组成。TransBlock使用CNN模块和变压器模块进行特征提取;EnhanceBlock聚合并增强了从CNN模块和变压器模块提取的特征地图,以便编码器能够更好地集成全局和局部特征;
被破坏了的图片直接进入CNN-Module,同时,它们被分为多个补丁,讲这些补丁再输入到TransBlock。
补丁用于构造序列,序列进入变压器,从嵌入线性投影E开始编码序列特征为z0∈ 得到RM×D。然后,z0穿过L层变压器层每层的输出表示为zl(l=1…l)。
编码器获得的特征,解码器再重构
融合流程
单通道灰度图像融合

源图像I1、I2进过编码器得到各自特征图序列Fi(三组),进行融合得到F’序列,最后在解码器中重建融合图像
Transformer
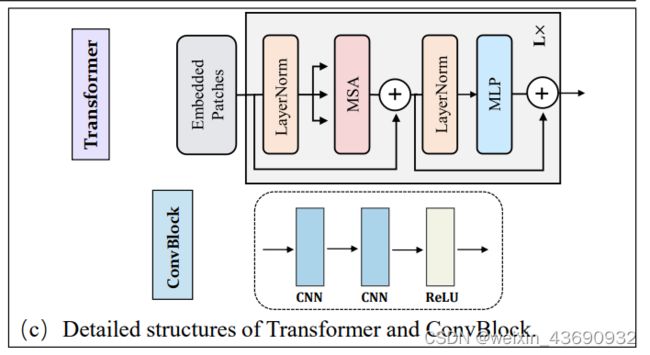
transformer层的架构:
它包括一个多头部注意机制(MSA)块和多层感知器(MLP)块,其中在每个块和在每个块后应用剩余连接,MLP块由具有GELU激活功能的两个线性层组成。
损失函数
为了实现 多任务学习同时执行三个自监督重建任务
损失函数如下:
Loss = LossTaskG + LossTaskF + LossTaskS
每一个任务的损失函数包括三部分
L=Lmse+λ1Lssim+λ2LTV
其中Lmse是均方误差(MSE)损失函数,
Lssim是结构相似性(SSIM)损失函数,
LTV是总变化损失函数。λ1和λ2是两个根据经验设置为20的超参数。
核心问题
三个自监督重建任务
基于Gamma的变换—学习场景内容和亮度信息
曝光过度的图像在黑暗区域包含足够的内容和结构信息,而曝光不足的图像在明亮区域包含足够的颜色和结构信息。
利用Gamma去改变选择子区域的亮度
基于傅里叶的变换—学习纹理和细节信息
使网络可以从频域学习纹理和细节信息,振幅决定了图像的强度,相位谱决定图像的高级语义(包含图像内容和图像位置)
基于global region shuffling的变换—学习结构和语义信息
随机挑选两个子集合中相同大小的区域进行变换,多次重复以获得破坏图像
创新点
1.根据多曝光图像的特点提出三个自监督重建任务,基于多任务学习训练出了一个自编码器,所以模型不仅能在大规模自然图像上训练,也可以学习到多曝光图像的特点;
2.为了克服CNN难以捕获长程信息的缺陷,提出来包含transformer结构的编码器结构,这样在特征提取过程中局部和全局信息都能捕获;