python k-means聚类分析_3个步骤,实现电商用户聚类分析|RFM模型

点击上方「蓝字」关注我们
作者:数据小斑马 | 数据分析师 CSDN博客专家 聚类通常分为以下三个步骤: ① 找到聚类指标,有现成模型的话(如RFM),可以直接按模型的指标,如没有,先罗列出比较重要的指标 ② 从数据库用SQL取出相应的指标数据,对数据进行清洗和标准化/归一化,如果是现成的模型,直接聚类,如果是拟定的指标,则对各指标进行相关性验证,剔除掉相关性较高的指标,再聚类 ③ 评估聚类效果,针对特定业务场景,提供可行性建议 本文通过RFM模型,对某电商平台的用户消费行为数据进行聚类,附数据集和详细代码。 什么叫RFM? RFM是一种通过以用户消费行为数据进行聚类,评判用户价值常用的模型,RFM分别对应于三个指标 R(Recency) :用户最近一次消费的时间间隔,衡量用户是否存在流失可能性 F(Frequency) :用户最近一段时间内累计消费频次,衡量用户的粘性 M(Money) : 用户最近一段时间内累计消费金额,衡量用户的消费能力和忠诚度
什么叫RFM? RFM是一种通过以用户消费行为数据进行聚类,评判用户价值常用的模型,RFM分别对应于三个指标 R(Recency) :用户最近一次消费的时间间隔,衡量用户是否存在流失可能性 F(Frequency) :用户最近一段时间内累计消费频次,衡量用户的粘性 M(Money) : 用户最近一段时间内累计消费金额,衡量用户的消费能力和忠诚度  聚类代码
聚类代码
# 电商用户质量RFM聚类分析from sklearn.cluster import KMeansfrom sklearn import metricsimport matplotlib.pyplot as pltfrom sklearn import preprocessing# 导入并清洗数据data = pd.read_csv('RFM.csv')data.user_id = data.user_id.astype('str')print(data.info())print(data.describe())X = data.values[:,1:]# 数据标准化(z_score)Model = preprocessing.StandardScaler()X = Model.fit_transform(X)# 迭代,选择合适的Kch_score = []ss_score = []inertia = []for k in range(2,10): clf = KMeans(n_clusters=k,max_iter=1000) pred = clf.fit_predict(X) ch = metrics.calinski_harabaz_score(X,pred) ss = metrics.silhouette_score(X,pred) ch_score.append(ch) ss_score.append(ss) inertia.append(clf.inertia_)# 做图对比fig = plt.figure()ax1 = fig.add_subplot(131)plt.plot(list(range(2,10)),ch_score,label='ch',c='y')plt.title('CH(calinski_harabaz_score)')plt.legend()ax2 = fig.add_subplot(132)plt.plot(list(range(2,10)),ss_score,label='ss',c='b')plt.title('轮廓系数')plt.legend()ax3 = fig.add_subplot(133)plt.plot(list(range(2,10)),inertia,label='inertia',c='g')plt.title('inertia')plt.legend()plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['font.serif'] = ['SimHei'] # 设置正常显示中文plt.show()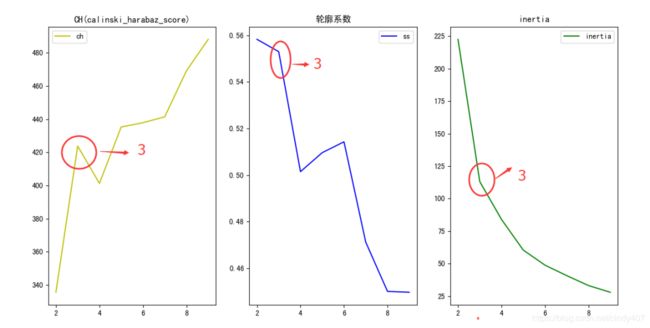 本次采用3个指标综合判定聚类质量,CH,轮廓系数和inertia分数,第1和第3均是越大越好,轮廓系数是越接近于1越好。 综合来看,聚为3类效果比较好
本次采用3个指标综合判定聚类质量,CH,轮廓系数和inertia分数,第1和第3均是越大越好,轮廓系数是越接近于1越好。 综合来看,聚为3类效果比较好
# 根据最佳的K值,聚类得到结果model = KMeans(n_clusters=3,max_iter=1000)model.fit_predict(X)labels = pd.Series(model.labels_)centers = pd.DataFrame(model.cluster_centers_)result1 = pd.concat([centers,labels.value_counts().sort_index(ascending=True)],axis=1) # 将聚类中心和聚类个数拼接在一起result1.columns = list(data.columns[1:]) + ['counts']print(result1)result = pd.concat([data,labels],axis=1) # 将原始数据和聚类结果拼接在一起result.columns = list(data.columns)+['label'] # 修改列名pd.options.display.max_columns = None # 设定展示所有的列print(result.groupby(['label']).agg('mean')) # 分组计算各指标的均值# 对聚类结果做图fig = plt.figure()ax1= fig.add_subplot(131)ax1.plot(list(range(1,4)),s.R_days,c='y',label='R')plt.title('R指标')plt.legend()ax2= fig.add_subplot(132)ax2.plot(list(range(1,4)),s.F_times,c='b',label='F')plt.title('F指标')plt.legend()ax3= fig.add_subplot(133)ax3.plot(list(range(1,4)),s.M_money,c='g',label='M')plt.title('M指标')plt.legend()plt.show()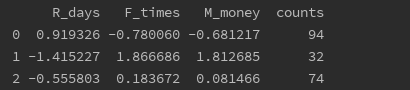
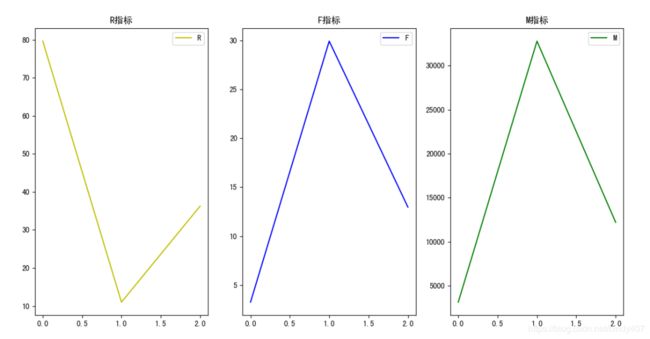
 聚类结果分析 从上图可知,用户共聚为3类: 第一类 :R最大,F和M均最低,说明离上次消费已经很久了,且19年上半年消费频次和消费金额基本为0,属于已流失或已沉默用户,建议通过短信或Email或其它方式召回或唤醒 第二类 :R最小,F和M最大,说明最近刚消费过,且近半年消费频次和消费金额都非常高,属于高忠诚度,高活跃和高付费能力的用户,是最需要重点呵护的用户,建议安排专员一对一服务 第三类 : R,F,M均一般,活跃度一般,消费能力一般,属于仍在活跃,但不够忠诚极易被竞品抢走的用户,建议对这批用户多进行一些品牌上的宣传,同时通过活动刺激他们多活跃,多消费,提升忠诚度。 总结: 1、聚类的指标选取,如果有现有的可适用模型最好,如果没有,则需要自己进行特征分析; 2、聚类前要进行数据清洗和标准化或归一化,不然不同的指标会存在量级和量纲的差异,导致结果有很大的误差 3、聚类评判标准有3个,CH,轮廓系数和inertia分数,第1和第3均是越大越好,轮廓系数是越接近于1越好 关注公众号,回复"RFM"就可以领取文中数据集 推荐 : python全球疫情分析,告诉你海外疫情到底有多严峻 原创不易,点个 在看 再走呗
聚类结果分析 从上图可知,用户共聚为3类: 第一类 :R最大,F和M均最低,说明离上次消费已经很久了,且19年上半年消费频次和消费金额基本为0,属于已流失或已沉默用户,建议通过短信或Email或其它方式召回或唤醒 第二类 :R最小,F和M最大,说明最近刚消费过,且近半年消费频次和消费金额都非常高,属于高忠诚度,高活跃和高付费能力的用户,是最需要重点呵护的用户,建议安排专员一对一服务 第三类 : R,F,M均一般,活跃度一般,消费能力一般,属于仍在活跃,但不够忠诚极易被竞品抢走的用户,建议对这批用户多进行一些品牌上的宣传,同时通过活动刺激他们多活跃,多消费,提升忠诚度。 总结: 1、聚类的指标选取,如果有现有的可适用模型最好,如果没有,则需要自己进行特征分析; 2、聚类前要进行数据清洗和标准化或归一化,不然不同的指标会存在量级和量纲的差异,导致结果有很大的误差 3、聚类评判标准有3个,CH,轮廓系数和inertia分数,第1和第3均是越大越好,轮廓系数是越接近于1越好 关注公众号,回复"RFM"就可以领取文中数据集 推荐 : python全球疫情分析,告诉你海外疫情到底有多严峻 原创不易,点个 在看 再走呗