用户价值分析
数据分析: 保险公司用户价值分析与用户画像
目录
一、分析目的
1,背景意义
对于保险公司来说,客户满意度和忠诚度是企业发展的重要资源之一,而以往对于客户关系管理即CRM存在些许不足,缺乏客户细分与客户定位能力,故利用客户数据库的客户数据信息,分析客户需求与偏好进行分类管理,针对性提供服务,能有效发展公司业务。
2,目标
借助保险公司客户数据,对客户进行分类,区分客户类别,判断公司主要的目标客户群体,比较不同类别客户的价值与潜在需求;
对不同客户进行属性分析,通过结合不同标签,生成客户画像,达到精细化运营;
针对不同的客户采取不同的营销手段,制定对应的营销策略,解决市场细分问题。
3,内容
综合多个特征的隐含联系,采用无监督学习的Kmeans算法及层次聚类算法对客户进行聚类,划分人群。
对划分的不同类别客户群体,进行客户价值分析,筛选出最符合目标的重要客户群体,并对不同客户群体的特征进行对比分析。
结合客户群体与数据标签,对目标客户建立用户画像,以实现数据场景变现。
二、分析结果(过程与图表详见下文)
1,客户群体划分
利用Kmean聚类与层次聚类算法,挖掘客户隐藏特征,将客户划分为低端节约型客户、中端享受型客户、中端居家型客户、中端外向型客户、高端居家型客户5种客户群体。
2,筛选目标客户
根据用户得分、企业得分综合评估不同群体客户的价值。
1)中端外向型以及高端居家型客户选择本公司较多,为公司重要客户,同时也应注重此类客户关系的维护,保证客户留存。
2)同时,最吸引本公司的客户为中端居家型客户,再者是中端外向型客户,此类客户数量与保险金额加权较高,应针对这些客户多进行宣传与拉新。
3)而低端节约型客户,中端享受型客户,对于本公司来说,具有的价值最低,可酌情降低投入程度。
3,客户属性分析
1)在各项保险增值服务中, 客户更多地考虑产品个性化因素,优于考虑一站式服务考虑程度以及网上投保考虑程度,公司可在各项服务中,投入更多精力于产品个性化设计。
2)客户选择保险公司时,更看重的因素在于服务网点多,亲朋推荐,以及信任销售人员,公司吸引新客户可更多按照这些方向,反映了保险业务的拓展更依赖于熟人社会,基于人际关系网络的社交属性明显。
3)不同类别客户的自然属性中,以年龄、城市、家庭月收入、汽车价格特征等差别较大。
4,目标客户画像
以中端外向型目标客户群体为例,基于标签含义,建立目标画像。可以刻画用户画像为:
小明,男,32岁。本科毕业,目前家庭月收入2.8W,拥有一辆20W的汽车。
性格活泼,喜爱户外运动,对生活充满激情,不喜欢一成不变的生活,勇于挑战新事物,对目前生活很满意。在保险投入上,投保金额较高,且选择本公司的意愿较高。
三、分析过程
1、数据预处理
1)导入模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
import factor_analyzer
from factor_analyzer import FactorAnalyzer
from sklearn.manifold import TSNE
import matplotlib.patheffects as PathEffects
from sklearn.cluster import KMeans
from scipy.cluster import hierarchy
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
#正常显示中文
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
#正常显示符号
from matplotlib import rcParams
rcParams['axes.unicode_minus']=False
2)数据清理
df=pd.read_csv('insurance_customer.csv',encoding='utf-8-sig')
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 712 entries, 0 to 711
Data columns (total 30 columns):
问卷编号 712 non-null int64
是否购买车险 712 non-null int64
性别 712 non-null int64
年龄 712 non-null int64
城市 712 non-null int64
学历 712 non-null int64
家庭月收入 712 non-null int64
职业 712 non-null object
汽车价格 712 non-null int64
决策时间 712 non-null int64
是否收集信息 712 non-null int64
从什么渠道收集信息 712 non-null object
投保渠道 712 non-null int64
保险公司的选择 712 non-null int64
保费金额 712 non-null float64
索赔经历 712 non-null int64
一站式服务考虑程度 712 non-null int64
网上投保考虑程度 712 non-null int64
产品个性化考虑程度 712 non-null int64
选择保险公司的考虑因素 712 non-null int64
满意度 712 non-null int64
对自己的生活很满意 712 non-null int64
为享受而产生的浪费是必要的 712 non-null int64
买房子前要先有车 712 non-null int64
不惜金钱和时间装修房子 712 non-null int64
买衣服都买便宜的 712 non-null int64
休息时经常进行户外活动 712 non-null int64
尝试生活充满变化 712 non-null int64
喜欢独自享受安静的生活 712 non-null int64
下班后尽快回家 712 non-null int64
dtypes: float64(1), int64(27), object(2)
memory usage: 167.0+ KB
df.head()
问卷编号 是否购买车险 性别 年龄 城市 学历 家庭月收入 职业 汽车价格 决策时间 是否收集信息 从什么渠道收集信息 投保渠道 \
0 1 1 1 1 6 2 1 5 1 1 1 3 4
1 2 1 2 1 7 2 1 1 1 1 1 1 1
2 3 1 1 1 6 1 2 6 1 1 2 4
3 4 1 1 3 5 2 2 6 3 1 1 2 2
4 5 1 1 3 5 2 1 2 3 3 2 2
保险公司的选择 保费金额 索赔经历 一站式服务考虑程度 网上投保考虑程度 产品个性化考虑程度 选择保险公司的考虑因素 满意度 \
0 3 870.0 2 1 1 7 4 1
1 3 1199.7 1 5 4 5 2 1
2 4 1764.0 2 4 4 4 6 2
3 4 1770.0 2 4 4 4 4 2
4 3 1377.0 2 3 4 4 3 1
对自己的生活很满意 为享受而产生的浪费是必要的 买房子前要先有车 不惜金钱和时间装修房子 买衣服都买便宜的 休息时经常进行户外活动 \
0 7 7 7 3 6 7
1 3 3 4 3 5 4
2 4 5 1 4 4 5
3 3 6 4 7 6 5
4 5 5 5 5 4 5
尝试生活充满变化 喜欢独自享受安静的生活 下班后尽快回家
0 7 7 7
1 5 4 3
2 4 5 7
3 5 5 4
4 5 4 5
#数据无缺失值。其中,‘职业’、‘从什么渠道获得信息’特征为类别数据,含有空格内容,对其进行填充。
df.从什么渠道收集信息.value_counts()
377
2 228
3 68
1 39
df.从什么渠道收集信息=df.从什么渠道收集信息.replace(' ',0). astype('int')
df.职业=df.职业.replace(' ',0). astype('int')
3)特征筛选
特征共有30个维度,排除‘问卷编号’,‘ 是否购买车险’两个无区分度的特征后,可以大致分为:
- 自然属性:性别、年龄、城市、学历、家庭月收入、职业、汽车价格;
- 保险选择因素:决策时间、 是否收集信息、 从什么渠道收集信息、 投保渠道、 保险公司的选择、 保费金额、 索赔经历、 一站式服务考虑程度、网上投保考虑程度、 产品个性化考虑程度、 选择保险公司的考虑因素、 满意度;
- 生活形态:对自己的生活很满意、为享受而产生的浪费是必要的、 买房子前要先有车、 不惜金钱和时间装修房子、 买衣服都买便宜的、 休息时经常进行户外活动、尝试生活充满变化、 喜欢独自享受安静的生活、 下班后尽快回家。
自然属性与保险选择因素为更具体的特征,生活形态特征相对更为抽象。除保险金额外,其余特征均已打好标签,并转化为数值型枚举数据。
对于保险公司,更在意客户的保费金额,保费高的用户能带来更大的经济价值。
这里选择利用客户的生活形态特征以及客户的投保金额进行聚类,聚类类别作为客户的价值与个性标签。
4)特征因子分析
生活形态特征总共9个维度,是客户的习性爱好,因此各个维度之间具有一定的内在联系。进行因子分析,筛选出可以代表这9个维度的n个隐藏特征(公因子)。
#因子分析前,对样本数据进行KMO和巴特利特检验
(KMO统计量在0.7以上时效果比较好;伴随概率小于显著水平5%,说明变量可以进行因子分析)
x = df.iloc[:, -9:]
kmo=round(factor_analyzer.calculate_kmo(x)[1],5)
bartlett=round(factor_analyzer.calculate_bartlett_sphericity(x)[1], 5)
print(kmo, bartlett)
0.71648 0.0
#对初始的9个维度进行因子分析(参数选择PCA方法,不旋转因子),求解各因子的特征值,方差贡献率,方差贡献率占比, 选择合适的因子数(此处选择特征值大于1的公因子)
fa = FactorAnalyzer(rotation=None, n_factors=9, method='principal')
fa.fit(x)
fa_var = fa.get_factor_variance()
fa_var = pd.DataFrame({'特征值': fa_var[0], '方差贡献率': fa_var[1], '方差贡献率占比': fa_var[2]})
特征值 方差贡献率 方差贡献率占比
0 2.779391 0.308821 0.308821
1 1.302006 0.144667 0.453489
2 1.157716 0.128635 0.582124
3 1.034961 0.114996 0.697119
4 0.659054 0.073228 0.770348
5 0.597498 0.066389 0.836736
6 0.571816 0.063535 0.900271
7 0.486350 0.054039 0.954310
8 0.411207 0.045690 1.000000
#选定公因子数4,重新对数据拟合,参数选择PCA方法和最大方差旋转
fa = FactorAnalyzer(4, rotation='varimax',method='principal')
fa.fit(x)
#输出因子载荷系数,为了显示效果,对因子载荷系数进行可视化,观察到每一个公因子都与2~3个观测变量有关。
df_cm = pd.DataFrame(np.abs(fa.loadings_))
plt.figure(figsize = (14,14))
ax = sns.heatmap(df_cm, annot=True, cmap="BuPu")
plt.title('Factor Analysis')
plt.ylabel('初始维度')
plt.xlabel('公因子')

#将原始的数据转换为新的特征‘因子类型’,与保费金额构成分类特征
df2= pd.DataFrame(fa.fit_transform(x), columns=list('1234'))
df2['因子类型'] = df2.idxmax(axis=1)
df2= pd.concat([df.保费金额,df2],axis=1)
df2=df2.drop(list('1234'),axis=1)
2、基于聚类模型的人群生成
使用生活形态特征隐藏因子与保费金额进行聚类,聚类结果为客户群体
#数据标准化
df2=StandardScaler().fit_transform(df2)
#谱系聚类图(欧式距离)
Z2 = hierarchy.linkage(df2, method = 'ward', metric = 'euclidean')
P2 = hierarchy.dendrogram(Z2, 0)

#用KMeans分类数据集,根据谱系聚类图,分为5类较为合理
km2=KMeans(5)
km2.fit(df2)
label2m=km2.labels_
#将得到的标签合并至原始的数据集中
df['2m']=label2m
#得到不同分类的客户,分类效果一般,存在两个类别客户保费金额相差很小,这也和KMeans算法的缺点有关。
#KMeans算法初始质心的位置随机,聚类得到的是结果是局部的最优值。
df.groupby('2m').保费金额.mean()
0 1482.975000
1 2872.917021
2 4028.518033
3 1610.517209
4 2464.256643
#使用层次聚类分类,从谱系图得到高度大致在13~14时,可以分为5类,分类效果好于KMeans
label2h = hierarchy.cut_tree(Z2, height=14)
label2h = label2h.reshape(label2h.size,)
df['2h']=label2h
df.groupby('2h').保费金额.mean()
0 1481.796226
1 2098.268056
2 2779.996241
3 1708.326829
4 3780.096296
#用单因素方差分析检验分类效果。当某因素的p值<0.05,拒绝原假设,则说明此因素对目标有显著影响。
formula = '保费金额~ 2m '
anova_results = anova_lm(ols(formula,df).fit())
print(anova_results[-2:])
F PR(>F)
2m 4.160379 0.04175
#KMeans聚类结果的p值接近0.05,而层次聚类结果的p值远小于0.05,可说明层次聚类得到的客户群里之间的保费金额具有更显著的差别。
formula = '保费金额~ 2h '
anova_results = anova_lm(ols(formula,df).fit())
print(anova_results[-2:])
F PR(>F)
2h 292.849487 3.162331e-55
#因此,对层次聚类得到的客户群,进行更详细的分析。
#TSNE降维可视化
ts=TSNE(2,random_state=1).fit_transform(df1) #降至二维的数据
#定义散点图
def scatter(x, y, n):
palette = np.array(sns.color_palette("hls", n)) #调色板颜色
f = plt.figure(figsize=(8, 8))
ax = plt.subplot(aspect='equal')
sc = ax.scatter(x[:,0], x[:,1], lw=0, s=40, c=palette[y])
plt.xlim(-25, 25)
plt.ylim(-25, 25)
ax.axis('off')
ax.axis('tight')
#给簇点加文字说明
txts = []
for i in range(n):
xtext, ytext = np.median(x[y == i, :], axis=0) #中心点
txt = ax.text(xtext, ytext, str(i), fontsize=24)
txt.set_path_effects([PathEffects.Stroke(linewidth=5, foreground="w"),PathEffects.Normal()]) #线条效果
txts.append(txt)
return f, ax, sc, txts
scatter(ts,df.1m,4)
TSNE可视化聚类,可看出层次聚类结果较好,各客户类别间的交叉重叠少。
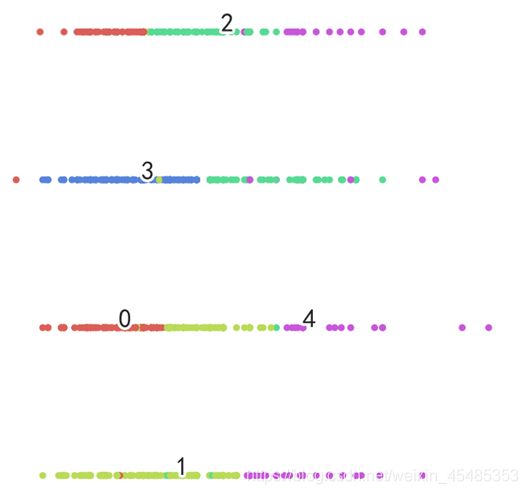
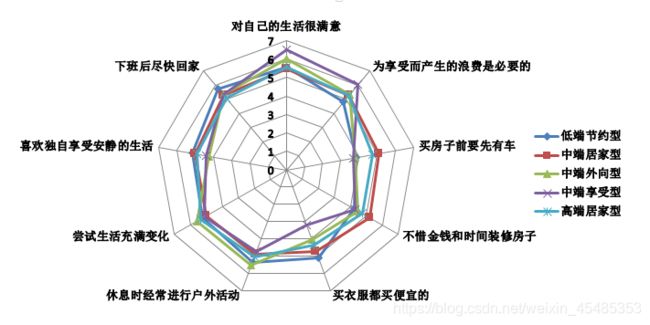
#结合雷达图,根据客户个性特征与保费金额的值,可分为以下五类
df['客户类型'] = df['2h'].map({0: '低端节约型客户', 1: '中端居家型客户', 2: '中端外向型客户', 3: '中端享受型客户', 4: '高端居家型客户'})
#数据保存为新文件,可用于可视化软件进一步分析
df.to_csv('new_insurance_customers.csv',encoding='utf-8-sig')
3、客户价值分析
根据综上的数据,对客户的价值进行分析。
3.1 目标客户选择,筛选出重要客户群体
这里目标客户选择看两点:
1、客户吸引公司之处在于此客户群体的数量,以及其此群体对应的保费金额。
2、公司吸引客户的程度体现在各类客户选择甲公司的比重。
#客户得分:客户数量、保费金额标准化值加权
a1=df.groupby('客户类型').保费金额.mean()
a2=df.groupby('客户类型').保费金额.count()/len(df.index)
a=pd.concat([a1,a2],axis=1)
a.columns=['保费金额','客户数量']
a['保费金额']=(a['保费金额']-a['保费金额'].mean())/a['保费金额'].std()
a['保费金额']=(a['保费金额']-a['保费金额'].mean())/a['保费金额'].std()
a=pd.DataFrame(a,columns=['保费金额','客户数量'],index=['低端节约型客户' ,'中端居家型客户' , '中端外向型客户' ,'中端享受型客户' , '高端居家型客户'])
a['加权得分']=0.4*a.保费金额+0.6*a.客户数量
保费金额 客户数量 加权得分
客户类型
中端享受型客户 -0.711415 -0.389420 -0.518218
中端外向型客户 0.441347 -0.188688 0.063326
中端居家型客户 -0.291968 1.477388 0.769645
低端节约型客户 -0.955087 0.333215 -0.182106
高端居家型客户 1.517124 -1.232494 -0.132647
#企业得分:各类别客户群在所有保险公司中选择甲公司的概率
b1=pd.crosstab(df.客户类型,df.保险公司的选择,normalize=0)
b1.columns=['甲','乙','丙','丁']
甲 乙 丙 丁
客户类型
中端享受型客户 0.162602 0.333333 0.268293 0.235772
中端外向型客户 0.458647 0.142857 0.187970 0.210526
中端居家型客户 0.240741 0.254630 0.259259 0.245370
低端节约型客户 0.119497 0.283019 0.358491 0.238994
高端居家型客户 0.320988 0.209877 0.098765 0.370370
#利用企业得分与客户得分,得到分布图,两种得分均较高的客户对于甲保险公司来说为最重要客户。
plt.scatter(x=b1.甲,y=a.加权得分)
plt.hlines(y=0, xmin=0, xmax=0.5)
plt.vlines(x=0.25, ymin=-1.2, ymax=1.2)
plt.xlabel('企业竞争力')
plt.ylabel('客户吸引力')
for x,y,z in zip(b1.甲,a.加权得分, a.index):
plt.text(x,y,z, ha='center', va='bottom')
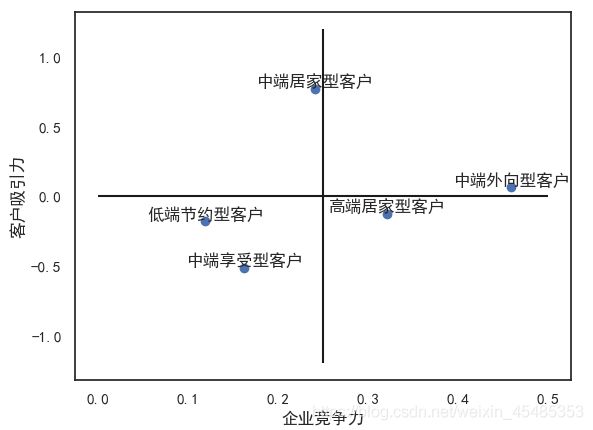
由分布图得:
中端外向型以及高端居家型客户选择甲公司较多,应注重此类客户关系的维护,保证客户留存。
同时,最吸引保险公司的客户为中端居家型客户,再者是中端外向型客户,此类客户数量与保险金额较高,应针对这些客户多进行宣传与拉新。
而低端节约型客户,中端享受型客户,对于保险公司来说,具有的价值最低,可酌情降低投入程度。
3.2 客户特征分析
1)客户对其他多样性服务的考虑程度
从客户给分平均值来看,目标客户对于产品的个性化考虑程度最高
ct2=df.groupby('客户类型')['一站式服务考虑程度', '网上投保考虑程度', '产品个性化考虑程度'].mean()
一站式服务考虑程度 网上投保考虑程度 产品个性化考虑程度
客户类型
中端享受型客户 4.121951 4.373984 4.926829
中端外向型客户 4.548872 4.729323 5.436090
中端居家型客户 4.712963 4.717593 5.356481
低端节约型客户 4.459119 4.572327 5.226415
高端居家型客户 4.950617 5.000000 5.382716

2)客户选择保险公司的因素
客户选择保险公司的因素,最重要的因素是服务网点多,亲朋推荐,以及信任销售人员
ct3=pd.crosstab(df.客户类型, df['选择保险公司的考虑因素'], normalize=0)
ct3.columns = ['服务态度好', '公司知名度高', '产品价格便宜', '服务网点多', '亲朋推荐', '信任销售人员', '理赔服务效率高']
服务态度好 公司知名度高 产品价格便宜 服务网点多 亲朋推荐 信任销售人员 理赔服务效率高
客户类型
中端享受型客户 0.081301 0.024390 0.146341 0.260163 0.178862 0.252033 0.056911
中端外向型客户 0.052632 0.022556 0.112782 0.248120 0.323308 0.180451 0.060150
中端居家型客户 0.013889 0.041667 0.125000 0.231481 0.273148 0.254630 0.060185
低端节约型客户 0.056604 0.044025 0.163522 0.308176 0.238994 0.150943 0.037736
高端居家型客户 0.024691 0.037037 0.061728 0.209877 0.296296 0.246914 0.123457

3)客户自然属性的差别
主要目标客户群体(中端居家型、中端外向型、高端居家型)的年龄相对较高,更多地居住于三线城市以内,家庭月收入与汽车价格处于较高的水平。
#可以看出,不同类别的客户自然属性中,学历与职业非常接近。其他维度上有差别。
d=df.groupby('2h')['性别','年龄','城市','学历','家庭月收入','职业','汽车价格'].mean()
性别 年龄 城市 学历 家庭月收入 职业 汽车价格
低端节约型 1.767296 1.069182 6.194969 1.679245 1.496855 4.081761 1.157233
中端居家型 1.217593 2.800926 4.810185 1.671296 2.449074 4.449074 2.819444
中端外向型 1.240602 2.263158 1.218045 1.62406 3.300752 4.218045 3.165414
中端享受型 1.186992 2.813008 5.788618 1.658537 1.902439 4.585366 2.170732
高端居家型 1.160494 2.246914 1.728395 1.555556 4.345679 4.790123 3.802469
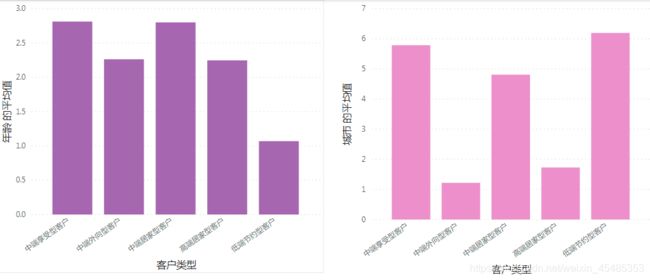
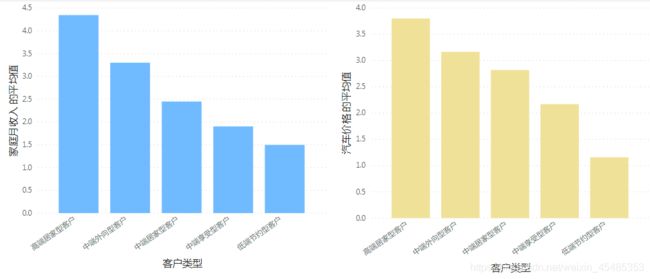
3.3 目标客户画像
以中端外向型目标客户群体为例,基于标签含义,建立目标画像。
中端外向型客户群体中以男性客户居多。
年龄分布以25-40岁的客户为主,占比约73%,大部分为本科学历。
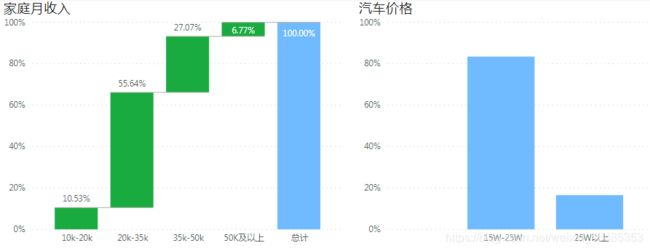
家庭月收入大多在20k-35k间,属于较高收入人群,使用的汽车多在15W-25W的价格区间内。
性格上最大特点为:对自己生活很满意,喜欢生活充满变化,休闲时常进行户外活动。
可以刻画用户画像为:
小明,男,32岁。本科毕业,目前家庭月收入2.8W,拥有一辆20W的汽车。
性格活泼,喜爱户外运动,对生活充满激情,不喜欢一成不变的生活,勇于挑战新事物,对目前生活很满意。在保险投入上,投保金额较高,且选择本公司的意愿较高。