联邦学习概述与现状
概念:
联邦机器学习(Federated machine learning/Federated Learning),又名联邦学习,联合学习,联盟学习。联邦机器学习是一个机器学习框架,能有效帮助多个机构在满足用户隐私保护、数据安全和政府法规的要求下,进行数据使用和机器学习建模。联邦学习作为分布式的机器学习范式,可以有效解决数据孤岛问题,让参与方在不共享数据的基础上联合建模,能从技术上打破数据孤岛,实现AI协作。谷歌在2016年提出了针对手机终端的联邦学习,微众银行AI团队则从金融行业实践出发,关注跨机构跨组织的大数据合作场景,首次提出“联邦迁移学习”的解决方案,将迁移学习和联邦学习结合起来。据杨强教授在“联邦学习研讨会”上介绍,联邦迁移学习让联邦学习更加通用化,可以在不同数据结构、不同机构间发挥作用,没有领域和算法限制,同时具有模型质量无损、保护隐私、确保数据安全的优势。
联邦学习定义了机器学习框架,在此框架下通过设计虚拟模型解决不同数据拥有方在不交换数据的情况下进行协作的问题。虚拟模型是各方将数据聚合在一起的最优模型,各自区域依据模型为本地目标服务。联邦学习要求此建模结果应当无限接近传统模式,即将多个数据拥有方的数据汇聚到一处进行建模的结果。在联邦机制下,各参与者的身份和地位相同,可建立共享数据策略。由于数据不发生转移,因此不会泄露用户隐私或影响数据规范。为了保护数据隐私、满足合法合规的要求。
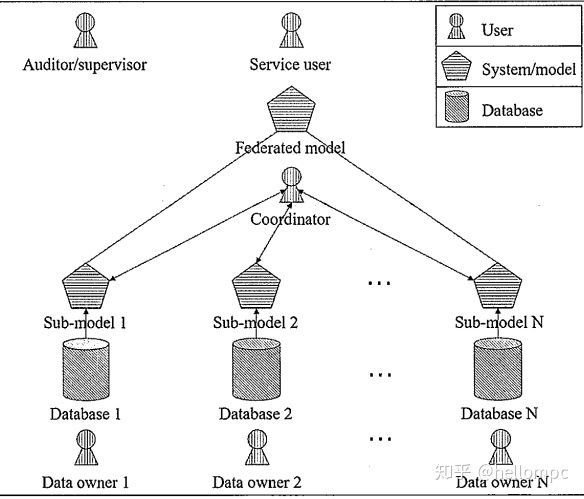
联邦学习有三大构成要素:数据源、联邦学习系统、用户。三者间关系如图所示,在联邦学习系统下,各个数据源方进行数据预处理,共同建立及其学习模型,并将输出结果反馈给用户。
分布式学习:
分布式机器学习也称为分布式学习 ,是指利用多个计算节点(也称为工作者,Worker)进行机器学习或者深度学习的算法和系统,旨在提高性能、保护隐私,并可扩展至更大规模的训练数据和更大的模型。如图所示,一个由N个工作者(即计算节点)和一个参数服务器组成的分布式机器学习系统,训练数据被分为不相交的数据分片(Shard)并被发送给各个工作者。采用一个集中的参数服务器。参数服务器的目标是负责收集来自于各个worker的梯度更新(updates),以及处理来自各个worker的参数请求(request)。分布式学习过程首先将数据集分割成n个块(shards)。每个单独的块将被分配给一个特定的worker。接下来,每个worker从其shards中采样mini-batches的数据用于训练一个local model。在一个(或多个)mini-batches之后,每个worker将与参数服务器通信,发送变量更新请求。这个更新请求一般都是梯度∇fi(x)。最后,参数服务器将所有这些参数更新的梯度收集起来,求平均(更新),并把更新之后的值发送到每个worker。图2展示上述过程。

图1 传统分布式机器学习模型
其实分布式机器学习,将开始讲了的两个问题都解决了。联邦学习其实就是一种分布式机器学习。虽然联邦群是被炒的很热,但是他跟分布式机器学习没有本质区别,如果有人吹联邦群其实多么革命性的创新,那真的是在吹牛。联邦学习是2015提出来的,联邦学习的应用很新,但是方法上没有太多新意。 一直到2017年,他们的文章才发表在AISTATS这个会议上,联邦学习带来很多有意思的问题,值得学术界来解决,但是基本是完全就是分布式机器学习。可能他的名字起的比较好,所以火了起来,联邦学习这个名字是怎么来的呢?联邦是有很多个邦或者州组成的,每个帮会都有很高的自治权,组成的联邦就是一个比较松散的政府。这很像我之前说的两个应用,手机用户或者医院,他们可以参与分布式学习,但是控制权还在用户自己手上,这就很类似于联邦联邦学习。
联邦学习跟传统的分布式学习有什么区别呢?区别肯定还是有的,否则叫他分布式学习就好了,用不着几个新的名字。有这么几点区别,首先用户对自己的设备和数据有绝对的控制权。用户可以随时让自己的设备停止参与计算和通信,这就像是联邦的组成部分,每一个帮都有很强的自治权,这跟传统的分布式机器学习所区别,map,reduce等传统分布式系统中worker受server的控制,接受server的指令。Server甚至可以送一个叫shuffle指令,让walker之间交换数据,把数据打散。传统分布式机器学习很像中国的政治体制上面有对各省的绝对控制权。 所以联邦学习跟传统分布式学习的第一个区别就是server对用户设备和数据有多大的控制权?第二个区别是,联邦学习中的worker可以是不稳定的节点,而传统的分布式的机器学习是在机房里的稳定统一的设备甚至有专人维护。并且联邦学习的worker设备可能是参差不齐的设备,计算能力各不相同。
中心服务器对数据和计算节点的控制权不同。
联邦:计算节点对数据具有绝对的控制权。中心服务器无法直接或间接操作计算节点上的数 据;计算节点可以随时停止计算和通信,退出学习过程。
分布:中心服务器对计算节点以及其中的数据具有较高的控制权,计算节点完全受中心服务器的控制,接收来自中心服务器的指令。例如,在 MapReduce 这种分布式计算模型中,中心服务器可以下发一个指令,让计算节点互相交换数据。
计算节点上数据分布类型不同。
联邦:并不能简单假设数据是独立同分布的,由于计算节点中的数据数据是独立产生的,他们往往表现出不同的分布特征(非独立同分布)。
分布:不同计算节点上的数据的划分通常是均匀、随机打乱的,它们具有独立同分布的特点,这样的特性非常适合设计高效的训练算法。
计算节点上数据量级不同。
联邦:然而在联邦学习的条件下,每个计算节点拥有的数据量与设备自身有关,很难保证不同计算节点拥有相近的数据量。
分布:分布式学习为了提高训练效率,通常都会把训练数据均匀分布在每个计算节点上,实现负载均衡。
计算节点稳定性不同。
分布式学习场景下的计算节点,通常都位于专用的机房中,用高速宽带进行互联,网络、运行环境都非常稳定。而参与联邦学习的计算节点可能是手机、平板等移动设备,这些设备因为用户的使用习惯,其所处的网络环境并不稳定,随时都可能与中心服务器断开连接。
通信代价不同。
因为分布式学习中的计算节点与中心服务器通常处于同一地理位置,而且有专用的通信条件,所以通信代价往往较小。而联邦学习中的计算节点可能分布在不同的地理位置,与中心服务器一般处于远程连接的状态,同时受不同设备网络带宽的影响,其通信代价要更高。
因此,综上所述的与传统分布式计算机器学习的不同之处也是联邦学习技术上的难点。
研究方向:
1、Communication-Efficiency
经典论文:H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. Y. Arcas, “Communication-efficient learning of deep networks from decentralized data,” in Proc. AISTATS, 2016, pp. 1273–1282.
这篇论文也被视为首次提出联邦学习的挖坑之作!解决了通信代价的问题,请看下文解析。
如下图,各个设备将每次根据Server发过来的模型参数利用本地数据计算梯度,并每次将梯度上传给Server进行求和再更新模型参数,一直反复进行这个步骤,直到Server模型收敛。该算法是分布式机器学习的并行梯度下降算法。而联邦学习中改进的算法 Federated Average Algorithm 如图3所示:

图2 传统分布式机器学习并行梯度下降
Federated Average Algorithm 使用更少的通信就能达到模型收敛,具体如下图3所示。和图2相同,第一步节点设备先请求Server拿到模型参数,然后对步骤1)、2)进行若干个epoch,使用本地数据再本地更新模型参数,这里与图2不同。图2是每次通信只进行一次梯度下降,而图3在本地进行若干个epoch对模型参数进行更新,之后再将更新好的参数传给Server而不是穿梯度给Server。这里传给Server的参数就已经更新了很多次了,而不是像图2要达到同样的收敛要进行很多次通信。之后Server接受到传回来的m个参数w,再对他们进行平均一下得到新的模型参数,然后不断进行这个操作。这样就减少了通信次数,图4所示,但是增加了本地设备(worker)的计算量,如图5所示。天下没有免费的午餐,牺牲worker计算量增加换取通信量的减少。

图3 Federated Average Algorithm

图4 传递梯度与传递参数的对比图 横轴为通信次数

图5 传递梯度与传递参数的对比图 横轴为epochs
2、Privacy
隐私保护问题也是联邦学习的重点问题,参考图1或者图3,无论是向Server发送梯度还是模型参数这都间接泄露了用户隐私。以下论文证明了梯度或者模型参数也能泄露节点设备的数据。

简单介绍论文1,论文1的观点是只要有梯度向量就能推断出这张图片样本的一些信息,例如性别、种族、年龄。

得到模型参数后可以计算任意现有数据的梯度向量,然后训练一个分类器对梯度进行预测,得到一些信息。其实梯度就是一个函数对数据的变换,而训练一个分类器就可以进行逆向工程。以上论文,证明无论梯度还是模型参数都在泄露用户隐私。当然,也有很多研究学者试图解决上述这些泄露用户隐私的问题,到目前这类论文几乎没有,还没有较好的方法解决问题。下面是通过梯度进行逆向工程得到的结果可视化:

3、Adversarial Robustness
拜占庭鲁棒性问题,拜占庭问题是说士兵们商量好了一起按照一个战术攻城,但是有些士兵是叛徒,从中使坏而导致整个军队被团灭。可以将图6中的黄色识别视为我们联邦学习中的正常节点worker,而黑色士兵视为错误节点(例如本地训练数据恶意修改了标签数据,或者提供错误的梯度信息或者参数信息导致Server集成错误)。这不是联邦学习仅有的问题,传统分布式机器学习也同样存在一些节点出问题了但没有挂掉而给其他节点提供错误的信息。
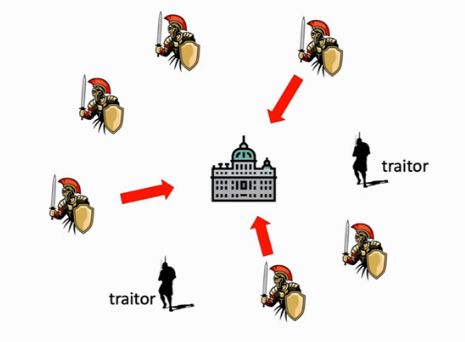
图6 拜占庭问题
下面介绍一些拜占庭攻击与防御的论文,参考问题1设计的比较巧妙,而参考文献2非常无脑属于有脑袋就能想到的,它就是直接修改某些节点的数据和标签,用正确的图片和错误的标签计算错误的梯度方向,再传给Server。有攻击就有防御,文献3 Server保留一个验证集,对每个传回来的梯度(使用这个梯度更新后的模型)或者模型参数计算一个准确率,这种防御没什么用,因为联邦学习的各个节点的数据分布不一样,Server的验证集数据分布也非常可能不一样。Server看不到worker的数据,所以对联邦学习而言作用不大。论文4是检验梯度的统计信息,检验各个节点传回来的梯度,如果某个节点梯度的信息与其他差异很大则可能是错误节点,但是依旧因为数据不是独立同分布而导致梯度差异很大,因此,此方法也是不太行。论文3,4,5都假设数据是独立同分布的,所以对联邦学习作用不大。现在真正有效的防御几乎没有!!!
不同使用场景
- 各个参与者的业务类型相似,数据特征重叠多,样本重叠少。例如:不同地区的两家银行。多家银行就都可以上传自己的模型参数,然后对参数进行更新,完成模型效果的提升。这就是 横向联邦学习 ,又被称之为特征对齐的联邦学习。
- 如果参与者的数据中,样本重叠多,特征重叠少,例如:同一地区的银行和电商,就需要先将样本对其,其中由于不能直接进行信息匹配,可以借助加密算法,让参与者在不泄露信息的情况下,找出相同的样本后联合他们进行特征,构建一个大表,进行模型训练。这被称之为: 纵向联邦学习 ,又被叫做样本对齐的联邦学习。
- 再者,如果样本重叠不多,特征重叠也不多,希望利用数据提升模型能力,就需要将参与者的模型和数据迁移到同一空间中运算,被称之为 联邦迁移学习。具体参考:联邦学习 OR 迁移学习?No,我们需要联邦迁移学习 和 联邦学习之联邦迁移学习 - 知乎
概念总结
联邦学习是一种分布式机器学习,以并行计算为基础。
联邦学习的目标:解决数据的协作和隐私保护问题。
联邦学习的分布并不是独立同分布的,因为用户与用户之间存在差异性,数据量可能也不是一个数量级的。所以不符合独立同分布的概率分布。
值得解决的问题:
1、通信效率问题,因为每个节点提交数据快慢不一致而Server要等大部分节点提交了才能进行下一步。
2、防御隐私泄露与攻击,联邦学习以保护隐私为卖点,实际上并不能完全保护用户隐私。
3、算法鲁棒性,某节点为捣乱节点,关键是数据不是独立同分布,所以非常难检测捣乱节点。
参考文献:
3. 分布式机器学习 - 知乎
https://www.bilibili.com/video/BV1YK4y1G7jwp=7&vd_source=68cf9730933898eed7ba8e6f033fe17d
https://www.jianshu.com/p/5f3c35620bb7
联邦学习 OR 迁移学习?No,我们需要联邦迁移学习
联邦学习之联邦迁移学习 - 知乎