目标检测:YOLOV3
发表于CVPR2018。YOLOV3本身没有太多的创新点,主要是整合了当时比较主流的一些网络的优点。
1、YOLOV3的backbone改进:
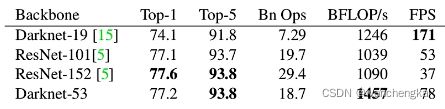
各个主干网络在imagenet上的运行效果。Darknet-53对比ResNet-152,top1和top5差不多,但速度快一倍。
Darknet-53网络结构(53个卷积层)
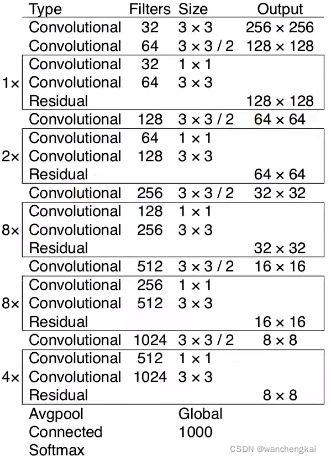
Darknet53主要也是采用残差块堆叠而成,但Darknet53没有最大池化层,降采样都是通过卷积层来实现的。有可能是这个操作使得Darknet53只有53个卷积层,却达到了ResNet152的152个卷积层的效果。
图中每个convolutional包含下图三步:Conv2d,BN,LeakyReLU。conv2d是不包bias的,如果使用BN层,bias就不起任何作用。

图中的每个框是一个残差结构如下图:

2、YOLOV3模型结构:
在 YOLO v3 更进一步采用了 3个不同尺度的特征图来进行对象检测。在训练集中所有目标bbox的位置通过k-means方法聚类得到相应的anchor,总共9个anchor,每个尺度3个。
在 COCO 数据集这 9 个先验框如下图:

分配上,在最小的 13 * 13 特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。中等的 26 * 26 特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。较大的 52 * 52 特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。
每个预测特征层的预测结果的向量维数为:N*N*[(4+1+C)*K],其中N是特征图的大小,C是类别数,COCO数据集为80,K是anchor的个数为3。

YOLOV3的总体网络模型如下图:

网络中每次特征图上采样后与原尺寸特征图的融合方式是concat,即在深度方向上拼接。而之前的FPN网络采用的是element-wise相加。
大尺寸特征图,通常可预测小尺寸目标;中尺寸特征图,通常可预测中尺寸目标;小尺寸特征图,通常可预测大尺寸目标。
注意生成预测结果的最后三层都只是Conv2d,没有BN和LeakyReLU。
3、YOLOV3中目标边界框的预测:
YOLOV3中目标边界框的预测和YOLOV2采用了相同的机制,中心点直接预测对于网格单元的相对位置(通过sigmoid函数变到0~1之间)。
YOLOv3网络预测中心点和faster rcnn及SSD有一点不一样,faster rcnn和SSD网络预测的中心点的回归参数是相对与anchor的。而YOLOv3中的中心点的回归参数是相对与网格左上角的。

上图展示了目标边界框的回归过程。图中虚线矩形框为Anchor模板(这里只用看(pw,ph))信息),实线矩形框为通过网络预测的偏移量(相对Grid Cell的左上角)计算得到的预测边界框。其中(cx,cy)为对应Grid Cell的左上角坐标,(pw,ph)为Anchor模板映射在特征层上的宽和高,网络输出(tx,ty,tw,th)分别为网络预测的边界框中心偏移量(tx,ty)以及宽高缩放因子(tw,th),(bx,by,bw,bh)为最终预测的目标边界框,从(tx,ty,tw,th)转换到(bx,by,bw,bh)的公式如图右侧所示,其中σ(x)函数是sigmoid函数其目的是将预测偏移量缩放到0到1之间(这样能够将每个Grid Cell中预测的边界框的中心坐标限制在当前cell当中,作者说这样能够加快网络收敛)。
4、YOLOV3的正负样本匹配:
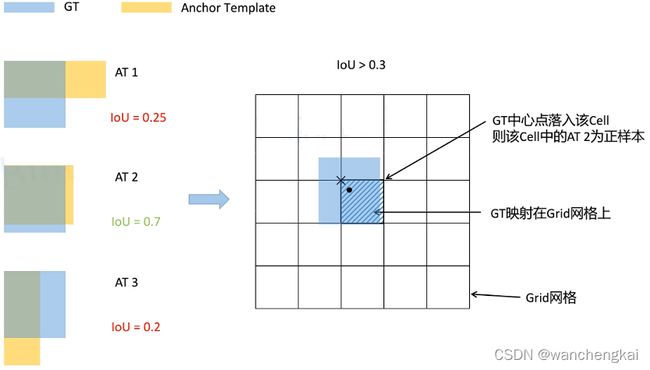
每个GT和所有的anchor template去比对。
用GT和anchor template的左上角重合,然后去计算它的IOU。之后通过设置阈值比如IOU>0.3的,都置为正样本。图中只有第二个满足条件。接下来再将GT映射到GRID网格中(或着说预测特征层上),GT的中心点再哪个grid cell中,那么这个grid cell的anchor template 2就是正样本。如果GT与多个anchor template的IOU都大于阈值,那么在当前指定grid cell中对应的多个anchor template都视为正样本。这样会扩充样本的数量。实践发现,这样效果会好一些。
5、损失计算:
YOLOv3的损失函数主要分为三个部分:目标置信度损失、目标分类损失、目标定位偏移量损失。其中λ 1 , λ 2 , λ 3是平衡系数。
![]()