【人工智能实验】卷积神经网络CNN框架的实现与应用-手写数字识别
目录
实验六 卷积神经网络CNN框架的实现与应用
一、实验目的
二、实验原理
三、实验结果
1、调整学习率、epochs以及bacth_size这三个参数,分别观察参数的变化对于实验结果的影响。
2、最终的实验结果
3、采用3折交叉验证
四、实验总结
1、CNN算法步骤
2、设计程序流程图
3、试分析mnist数据集X_train、X_test以及相对应的Y_train、Y_test。
4、交叉验证及衡量指标部分代码:
5、实验过程中建立的Lenet5模型中各个参数及卷积核的个数见下图4.4,核心代码如下,具体代码见附件。
附录
源码
推荐文章
实验六 卷积神经网络CNN框架的实现与应用
一、实验目的
1、掌握卷积神经网络CNN的基本原理
2、利用CNN实现手写数字识别
二、实验原理
利用LeNet-5 CNN框架,实现手写数字识别。其中网络层级结构概述如图2所示,共有7层神经网络。在图2.1中,各网络层参数如下表2.1所示.
表2.1 各网络层参数设置对应表
| Input layer |
输入数据为原始训练图像32*32 |
| Conv1 |
6个5*5的卷积核,步长Stride为1 |
| Pooling1 |
卷积核size为2*2,步长Stride为2 |
| Conv2 |
12个5*5的卷积核,步长Stride为1 |
| Pooling2 |
卷积核size为2*2,步长Stride为2 |
| Output layer |
输出为10维向量 |
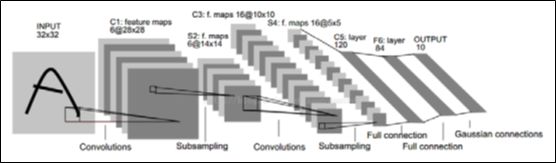
图2 CNN模型基本框架图
本次实验采用minst数据集,初始图像大小为28*28,采用下表2.2参数搭建CNN模型。
表2.2 各网络层参数设置对应表
| Input layer |
输入数据为原始训练图像28*28 |
| Conv1 |
6个5*5的卷积核,步长Stride为1 |
| Pooling1 |
卷积核size为2*2,步长Stride为2 |
| Conv2 |
16个5*5的卷积核,步长Stride为1 |
| Pooling2 |
卷积核size为2*2,步长Stride为2 |
| Flatten() |
一个重新调整为 1D 的张量。 |
| Dense(120, activation='tanh') |
全连接层 |
| Dense(84, activation='tanh') |
全连接层 |
| Dense(10, activation='softmax') |
输出为10维向量 |
三、实验结果
注:由于添加交叉验证会导致训练时间边长,这里采用先确定合适参数再进行交叉验证训练
衡量实验结果的常用指标如下:
检测率:![]()
查全率:![]()
准确率:![]()
1、调整学习率、epochs以及bacth_size这三个参数,分别观察参数的变化对于实验结果的影响。
(1)固定参数epochs = 3,batch_size = 128,观察学习率对于正确率的影响,可以发现随着学习率由0.0001逐渐增大时,准确率及其他评价指标都是先上升后下降,运行时间受学习率的影响不大,变化图见图3.1.1,具体结果见表3.1.1。
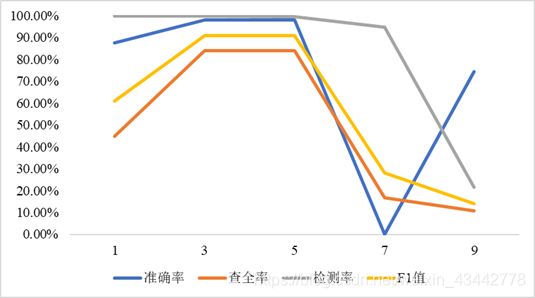
图3.1.1 学习率对于准确率的影响
表3.1.1 学习率对于准确率的影响
|
|
学习率 |
||||
| 0.0001 |
0.001 |
0.01 |
0.1 |
1 |
|
| 运行时间(s) |
24.57 |
25.63 |
25.34 |
25.39 |
25.13 |
| 准确率 |
87.67% |
98.07% |
98.06% |
51. 95% |
74.33% |
| 查全率 |
44.78% |
83.86% |
84.00% |
16.62% |
10.83% |
| 检测率 |
99.76% |
99.88% |
99.64% |
94.73% |
21.67% |
| F1值 |
0.61 |
0.91 |
0.91 |
0.28 |
0.14 |
(2)固定参数learning_rate=0.001, batch_size = 128,观察epochs对于准确率的影响。
表3.1.2 epochs对于准确率的影响
|
|
epochs |
||||
| 1 |
3 |
5 |
7 |
9 |
|
| 运行时间(s) |
10.09 |
25.51 |
42.63 |
60.47 |
75.75 |
| 准确率 |
67.21% |
91.89% |
95.96% |
97.40% |
98.28% |
| 查全率 |
23.34% |
55.24% |
71.31% |
79.43% |
95.39% |
| 检测率 |
99.78% |
99.78% |
99.87% |
99.94% |
99.95% |
| F1值 |
0.37 |
0.71 |
0.83 |
0.88 |
0.92 |
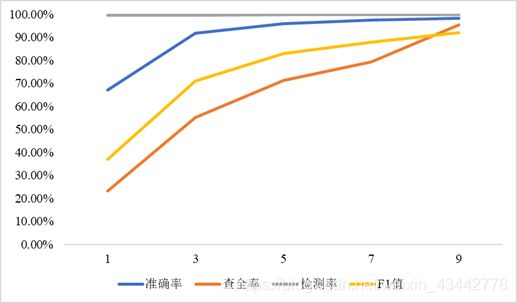
图3.1.2 epochs对于准确率的影响
(3)固定参数learning_rate=0.001,epochs=5,观察batch_size对于准确率的影响。
表3.1.3 batch_size对于准确率的影响
|
|
batch_size |
||||
| 108 |
118 |
128 |
138 |
148 |
|
| 运行时间(s) |
42.85 |
44.01 |
41.20 |
41.93 |
41.82 |
| 准确率 |
93.69% |
96.53% |
97.48% |
97.93% |
98.22% |
| 查全率 |
61.35% |
74.31% |
79.95% |
82.94% |
85.02% |
| 检测率 |
99.83% |
99.87% |
99.89% |
99.88% |
99.88% |
| F1值 |
0.76 |
0.85 |
0.88 |
0.90 |
0.91 |
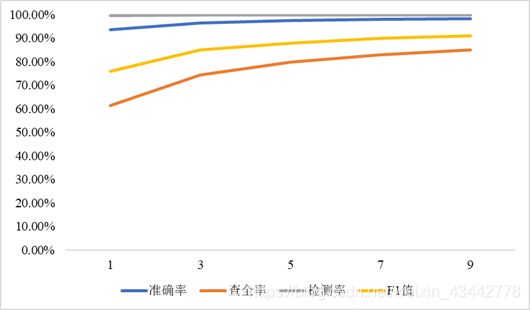
图3.1.3 batch_size对于准确率的影响
2、最终的实验结果
选取参数learning_rate=0.001, batch_size = 148,epochs=5,具体的实验结果如表3.2所示:
表3.2 最终实验结果
| 检测率 |
查全率 |
准确率 |
F1值 |
| 99.88% |
85.02% |
98.22% |
0.91 |
3、采用3折交叉验证
选取参数learning_rate=0.001, batch_size = 148,epochs=5,具体的实验结果如表3.3所示:
表3.3 最终实验结果
| 检测率 |
查全率 |
准确率 |
F1值 |
| 99.85% |
89.50% |
98.79% |
0.94 |
四、实验总结
1、CNN算法步骤
Step1 获取训练数据和测试数据;
Step2 定义网络层级结构;
Step3 初始设置网络参数(权重W,偏向b)cnnsetup(cnn, train_x, train_y)
Step4训练超参数opts定义(学习率,batchsize,epoch)
Step5网络训练之前向运算cnnff(net, batch_x)
Step6 网络训练之反向传播cnnbp(net, batch_y)
Step7 网络训练之参数更新cnnapplygrads(net, opts)
Step8 重复Step5 Step6 Step7,直至满足epoch
Step9 网络测试cnntest(cnn, test_x, test_y)
2、设计程序流程图
图4.2 程序流程图

3、试分析mnist数据集X_train、X_test以及相对应的Y_train、Y_test。
表4.3 数据集分析表
|
|
X_train |
X_test |
Y_train |
Y_test |
| 原始数据shape |
60000*28*28 |
10000*28*28 |
60000*1 |
10000*1 |
| 处理后shape |
60000*28*28*1 |
10000*28*28*1 |
60000*10 |
10000*10 |
4、交叉验证及衡量指标部分代码:
注:由于添加交叉验证会导致训练时间边长,这里采用先确定合适参数再进行交叉验证训练。
| # 合为一个数据,进行交叉验证 data = np.row_stack((x_train,x_test)) target = np.row_stack((y_train,y_test)) for train, test in kf.split(data): model.fit(data[train], target[train],batch_size=batch_size,epochs=epochs, verbose=1,validation_data=(data[test], target[test]),callbacks=[history]) #测试 y_predict = model.predict(data[test], batch_size=512, verbose=1) # y_predict = (y_predict > 0.007).astype(int) y_predict = (y_predict > 0.01).astype(int) y_true = np.reshape(target[test], [-1]) y_pred = np.reshape(y_predict, [-1]) # 评价指标 accuracy.append(accuracy_score(y_true, y_pred))#正确率,查准率,预测对的样本数占样本总数的比例 precision.append(precision_score(y_true, y_pred))#精度,查全率,预测为正的样本中实际正样本的比例 recall.append(recall_score(y_true, y_pred, average='binary'))#实际正样本中预测为正的概率 f1score.append(f1_score(y_true, y_pred, average='binary')) # Micro F1: 将n分类的评价拆成n个二分类的评价,将n个二分类评价的TP、FP、RN对应相加,计算评价准确率和召回率,由这2个准确率和召回率计算的F1 score即为Micro F1。 micro_f1 = f1_score(y_true, y_pred,average='micro') |
5、实验过程中建立的Lenet5模型中各个参数及卷积核的个数见下图4.4,核心代码如下,具体代码见附件。
| # 建立模型 model = Sequential() # lenet-5 model.add(Convolution2D(filters=6, kernel_size=(5, 5), padding='valid', input_shape=(img_rows, img_cols, 1), activation='tanh')) model.add(MaxPooling2D(pool_size=(2, 2)))#步长为2 model.add(Convolution2D(filters=16, kernel_size=(5, 5), padding='valid', activation='tanh')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(120, activation='tanh')) model.add(Dense(84, activation='tanh')) model.add(Dense(n_classes, activation='softmax')) model.summary() model.compile(optimizer=Adam(lr=learning_rate), loss='categorical_crossentropy',metrics=['accuracy']) history = LossHistory()#显示回调函数,看看到底执行了什么,我的参数如何设置的 model.fit(x_train, y_train,batch_size=batch_size,epochs=epochs, verbose=1,validation_data=(x_test, y_test),callbacks=[history]) |
图4.5 模型参数的设置

附录
-
np_utils.to_categorical使用方法:https://www.cnblogs.com/lhuser/p/90730 12.html
源码
https://download.csdn.net/download/weixin_43442778/16053604
推荐文章
- 700套个人简历模板(考研保研工作):https://blog.csdn.net/weixin_43442778/article/details/114280230
- 人工智能2019年秋季学期期末复习知识点整理:https://blog.csdn.net/weixin_43442778?spm=1003.2018.3001.5343
- Fisher线性分类器的设计与实现,感知器算法的设计实现:https://download.csdn.net/download/weixin_43442778/16017212
欢迎大家关注【小果果学长】微信公众号,获取更多资料和源码,期待你的点赞和支持!