【Pytorch基础(1)】pytorch的基本数据类型:张量
前言
PyTorch 于 2016 年首次推出。在 PyTorch 之前,深度学习框架通常专注于速度或可用性,但不能同时关注两者。PyTorch将这两者相结合,提供了一种命令式和 Python编程风格,支持将代码作为模型,使调试变得容易,支持 GPU 等硬件加速器。
PyTorch 是一个 Python 库,它通过自动微分和 GPU 加速执行动态张量计算。它的大部分核心都是用 C++ 编写的,这也是 PyTorch 与其他框架相比可以实现低得多的开销的主要原因之一。PyTorch 似乎最适合大幅缩短特定用途的新神经网络的设计、训练和测试周期。
一、pytorch的基本数据类型:张量
Pytorch里面处理的最基本的操作对象就是Tensor(张量),它表示的其实就是一个多维矩阵,并有矩阵相关的运算操作。在使用上和numpy是对应的,它和numpy唯一的不同就是,pytorch可以在GPU上运行,而numpy不可以。所以,我们也可以使用Tensor来代替numpy的使用。当然,二者也可以相互转换。
Tensor的基本数据类型有五种:
(1)32位浮点型:torch.FloatTensor (注:pytorch.Tensor()默认的就是这种类型。)
(2)64位整型:torch.LongTensor
(3)32位整型:torch.IntTensor
(4)16位整型:torch.ShortTensor
(5)64位浮点型:torch.DoubleTensor
那么如何定义Tensor张量呢?其实定义的方式和numpy一样,直接传入相应的矩阵即可。下面就定义了一个三行两列的矩阵:
import torch
a = torch.Tensor([[1, 2], [3, 4], [5, 6]])
print(a)
不过在项目之中,更多的做法是以特殊值或者随机值初始化一个矩阵,就像下面这样:
import torch
# 定义一个3行2列的全为0的矩阵
b = torch.zeros((3, 2))
# 定义一个3行2列的随机值矩阵
c = torch.randn((3, 2))
# 定义一个3行2列全为1的矩阵
d = torch.ones((3, 2))
print(b)
print(c)
print(d)
运行结果:

Tensor和numpy.ndarray之间还可以相互转换,其方式如下:
Numpy转化为Tensor:torch.from_numpy(numpy矩阵)
Tensor转化为numpy:Tensor矩阵.numpy()
范例如下:
import torch
import numpy as np
# 定义一个3行2列的全为0的矩阵
b = torch.randn((3, 2))
print(b)
# tensor转化为numpy
numpy_b = b.numpy()
print(numpy_b)
# numpy转化为tensor
numpy_e = np.array([[1, 2], [3, 4], [5, 6]])
torch_e = torch.from_numpy(numpy_e)
print(numpy_e)
print(torch_e)
运行结果:

之前说过,numpy与Tensor最大的区别就是在对GPU的支持上。Tensor只需要调用cuda()函数就可以将其转化为能在GPU上运行的类型。
我们可以通过torch.cuda.is_available()函数来判断当前的环境是否支持GPU,如果支持,则返回True。所以,为保险起见,在项目代码中一般采取“先判断,后使用”的策略来保证代码的正常运行,其基本结构如下:
import torch
# 定义一个3行2列的随机的矩阵
a = torch.randn((3, 2))
# 如果支持GPU,则定义为GPU类型
if torch.cuda.is_available():
inputs = a.cuda()
# 否则,定义为一般的Tensor类型
else:
inputs = a
此外,不同维度的张量可以涵盖不同含义的数据。如下举例:
(1)当一个张量维度为0时,等价于一个标量。在深度学习模型训练过程中常见的标量为模型的训练损失(loss)。
(2)当一个张量维度为1时,等价于一个向量。在深度学习模型训练过程中常见的向量为模型的偏置(bias),神经网络的输入输出(linear input/output)等。
(3)当一个张量维度为2时,等价于一个矩阵。在深度学习模型训练过程中常见的矩阵为带批量大小的神经网络的输入输出,即[batch, linear_input]。
(4)当一个张量维度为3时,一般表示RNN模型的输入信息,即[batch, num_world, world_embedding]
(5)当一个张量维度为4时,一般表示CNN模型的输入信息,即[batch, channel, height, weight]
(6)当然,张量的维度也可以大于5,在不同的模型和不同的问题中,张量可以通过增加维度来合并不同的信息特征。需要注意的是,我们一般会约定俗成的将概念比较大的特征放在靠前的维度,将概念比较小的特征放在靠后的维度。
二、创建张量
在第一小节中,我们展示了使用numpy数据类型创建张量的方法以及两者的互换。除此之外,我们也可以从python的List数据类型转化张量。实例如下:
# 使用函数torch.tensor()进行List到Tensor的转化
t = torch.tensor([2., 3.2])
print(t)
运行结果:

除了将numpy数据类型或python数据类型转换为张量以外,pytorch当然也提供初始化张量的方法。其中,根据初始化张量值的随机性和确定性可以对张量初始化方法做区分。
确定性的初始化方法
torch.tensor() : 将想要初始化的张量值作为参数传进函数里即可
创建实例:
import torch
t0 = torch.tensor(2)
t1 = torch.tensor(2.3)
t2 = torch.tensor([1,2,3])
print(t0 )
print(t1 )
print(t2 )
运行结果:

torch.arange():按照设定的区间进行左闭右开的整数取值方法。
方法格式如下:
torch.arange(start=0, end, step=1, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
常用参数介绍:
start (数字) - 这组点的起始值。默认值:0。
end (数字) - 这组点的结束值
step (Number) - 每对相邻点之间的间隔。默认值:1。
dtype (torch.dtype, optional) - 返回张量的理想数据类型。默认情况:如果没有,使用全局默认值(见torch.set_default_tensor_type()的输出)。如果没有给出dtype,则从其他输入参数中推断出数据类型。如果start、end或step中的任何一个是浮点型,则推断出的dtype是浮点型,否则,dtype被推断为torch.int64。
创建实例:
import torch
t = torch.arange(0, 10)
print(t)
运行结果:
![]()
torch.linspace():按照设定的取值数量在一个区间中进行左闭右闭的平均取值方法。
方法格式如下:
torch.linspace(start, end, steps, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
常用参数介绍:
start (float) - 这组点的起始值 (起始的数)
end (float) - 这组点的结束值 (结束的数)
steps (int) - 构建张量的大小(定义数据生成的个数)
dtype (torch.dpython:type, optional) - 用来进行计算的数据类型。默认情况:如果没有,当start和end都是实数时,使用全局默认的dtype(见torch.get_default_dtype()的输出)。
创建实例:
import torch
t = torch.linspace(0, 10, steps=4)
print(t)
运行结果:
![]()
torch.logspace():在给定区间内以左闭右闭的取值方式创建对数均分的一维张量
方法格式如下:
torch.logspace(start, end, steps, base=10.0, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
常用参数介绍:
start (float) - 这组点的起始值
end (float) - 这组点的结束值
steps (int) - 构造张量的大小
base (float, optional) - 对数函数的基数。默认值为10.0.
dtype (torch.dpython:type, optional) - 执行计算的数据类型。默认情况下:如果没有,当start和end都是实数时,使用全局默认的dtype(见torch.get_default_dtype())。
创建实例:
import torch
t = torch.logspace(0, 10, steps=4)
print(t)
运行结果:
![]()
ones/zeros/eye/full:按照定义好的值来创建数组
创建实例:
import torch
t0 = torch.zeros(3, 3)
t1 = torch.ones(3, 3)
t2 = torch.eye(4, 4)
t3 = torch.full([4,4], 7)
print('3X3大小的全零矩阵:', t0)
print('3X3大小的全一矩阵:', t1)
print('4X4大小的对角矩阵:', t2)
print('4X4大小的全值矩阵:', t3)
运行结果:

三、随机性的初始化方法
torch.Tensor():随机创建给定尺寸大小的张量
注意,虽然与torch.tensor()方法只有一个大写字符的区别,但是两个函数的功能相差却很大。torch.tensor()接受的参数是张量的值;而torch.Tensor()接受的参数的张量的形状或值,当接受的是张量形状时,值是随机初始化的。
创建实例如下:
import torch
# 直接传入整数时,代表要生成的张量的形状
t0 = torch.Tensor(2)
# 当传参代表生成的张量的形状时,值是随机初始化的,因此下方的输出结果可以观察到两次 torch.Tensor(2)的输出并不一样。
t1 = torch.Tensor(2)
# 当传参是列表时,列表中的元素为创建张量的值。
t2 = torch.Tensor([2])
print(t0 )
print(t1 )
print(t2 )
运行结果:
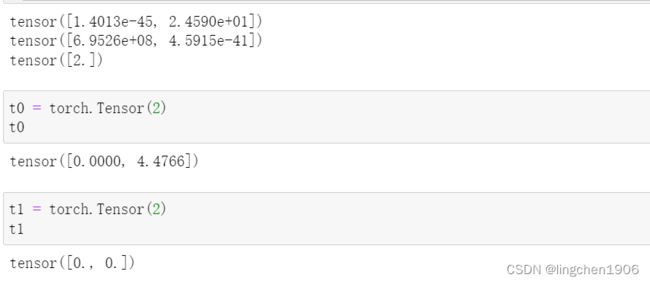
注意, torch.Tensor( ) 创建的张量数据类型是默认值,可以通过torch.set_default_tensor_type()函数进行默认数据类型的修改。此外,也可以直接通过函数torch.IntTensor(), torch.FloatTensor等方法直接创建想使用的数据类型张量。
torch.rand():返回区间 [0,1)上均匀分布的随机数填充的张量,张量的形状由可变参数大小定义
方法格式如下:
torch.rand(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
其中,常用的参数是size 。其含义是一系列整数,定义了输出张量的形状。可以是一个可变数量的参数或像列表或元组的集合。
创建实例如下:
import torch
a = torch.rand(4)
b = torch.rand(2, 3)
print(a)
print(b)
运行结果:

torch.rand_like() : 返回一个与输入相同大小的张量,该张量由区间 [0,1]上的均匀分布的随机数填充。
方法格式如下:
torch.rand_like(input, *, dtype=None, layout=None, device=None, requires_grad=False, memory_format=torch.preserve_format) → Tensor
常用的参数是input ,其含义是输入的张量,方法将输出一个与输入张量相同维度的结果。创建实例如下
import torch
a = torch.rand(3, 3)
b = torch.rand_like(a)
print(a)
print(b)
运行结果:

torch.randint() 返回一个充满随机整数的张量。
方法的格式如下:
torch.randint(low=0, high, size, \*, generator=None, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
常用的参数含义如下:
low (int, optional) - 从分布中提取的最低整数。默认值:0。
high (int) - 从分布中抽取的最高整数(不包括其本身,即左闭右开)。
size (tuple) - 定义输出张量的形状的一个元组。
创建实例如下:
import torch
a = torch.randint(3, 5, (3,))
b = torch.randint(10, (2, 2))
print(a)
print(b)
运行结果:

torch.randn():返回一个充满随机数的张量,该张量来自均值为0、方差为1的正态分布(也称为标准正态分布)。
方法格式如下:
torch.randn(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
常用参数为size, 其含义是定义了输出张量形状的一组整数,可以是一个可变数量的参数或像列表或元组的集合。
创建实例如下:
import torch
a = torch.randn(4)
b = torch.randn(2, 3)
print(a)
print(b)
运行结果:

torch.randperm(): 返回一个从0到n - 1的整数的随机排列。
方法格式如下:
torch.randperm(n, *, generator=None, out=None, dtype=torch.int64, layout=torch.strided, device=None, requires_grad=False, pin_memory=False) → Tensor
常用参数是n, 其含义是取值上限的意思。
创建实例如下:
import torch
a = torch.randperm(10)
b = torch.randperm(10)
print(a)
print(b)
运行结果:
