分类------KNN模型
KNN(K-Nearest Neighbor)相关:
对于knn来说,告诉我你的邻居是哪个类别,我就知道你是哪个类别。KNN中k值就是选取邻近样本的个数,所需要判断的样本类别为其中最多的样本类别,即少数服从多数。
knn算法需要一个距离函数来判断两个样本之间的距离,常用的:欧氏距离、余弦距离、汉明距离、曼哈顿距离等,一般选欧氏距离作为距离度量,但是这是只适用于连续变量。在文本分类这种非连续变量情况下,汉明距离可以用来作为度量。通常情况下,如果运用一些特殊的算法来计算度量的话,K近邻分类精度可显著提高,如运用大边缘最近邻法或者近邻成分分析法。
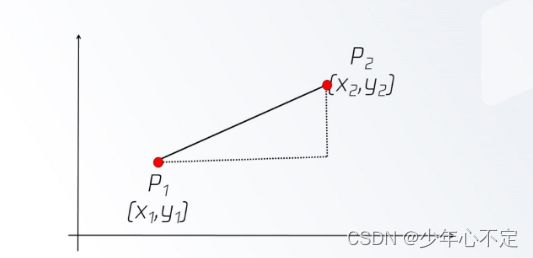
欧几里得距离: Distance(P1,P2) = (x![]() -x
-x![]() )^2+(y
)^2+(y![]() -y
-y![]() )^2
)^2
KNN的构造步骤:
步骤1:选择邻居的个数,一般选择五个邻居
步骤2:根据欧几里得距离得到距离新数据点最邻近的5个邻居
步骤3:在这5个邻居中,数出每个类别下邻居的个数
步骤4:把这个新数据点分配给邻居数量最多的哪个类别
步骤5:直至把所有的新数据点分配完成。模型结束。
下面通过一个案例来实现KNN算法思想:
案例:KNN最优模型的效果展示
读取数据:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv('bankloan.csv')
data.head(5)
划分数据集
X = data.iloc[::,0:8]
y = data.iloc[:,8]
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test= train_test_split(X,y,test_size=0.25,random_state=5)
X_train.shape,X_test.shape,y_train.shape,y_test.shape数据集处理(将训练集和测试集的数据进行标准化处理)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)模型训练
通过了循环进行超参数调参,选取出了最优的K值和P值,并在此基础上得到了最优的score准确值
from sklearn.neighbors import KNeighborsClassifier
best_score = 0
best_k = 0
best_p = 0
for a in ['uniform','distance']:
for b in range(1,11):
for c in range(1,6):
knn = KNeighborsClassifier(n_neighbors=b,weights=a,p=c)
knn.fit(X_train,y_train)
s = knn.score(X_test,y_test)
if best_score
模型评估(混淆矩阵、计算精确度和敏感度)
y_pred = knn.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,y_pred)
cm
from sklearn.metrics import classification_report
report = classification_report(y_test,y_pred)
print(report)
可视化(二维和三维)
from sklearn.preprocessing import StandardScaler
x=data
std = StandardScaler()
data_std= std.fit_transform(x)
data_std[:8]
from sklearn.manifold import TSNE
tsne = TSNE()
tsne.fit_transform(data_std) #进行数据降维
from sklearn.cluster import KMeans
model = KMeans(n_clusters = 3, n_jobs = 4, max_iter = 500) #分为k类,并发数4
model.fit(data_std) #开始聚类
df=pd.DataFrame(data=tsne.embedding_, columns=['x','y'])
df['type']=model.labels_
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
#不同类别用不同颜色和样式绘图
d = df[df.type == 0]
plt.plot(d.x, d.y, 'r.')
d = df[df.type == 1]
plt.plot(d.x, d.y, 'g.')
d = df[df.type == 2]
plt.plot(d.x, d.y, 'b.')
plt.show()二维可视化图

%matplotlib notebook
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = Axes3D(fig)
d=data_std[df.type==0]
print(d.shape)
ax.scatter(d[:,0],d[:,1],d[:,2], c='r')
d=data_std[df.type==1]
print(d.shape)
ax.scatter(d[:,0],d[:,1],d[:,2], c='g')
d=data_std[df.type==2]
print(d.shape)
ax.scatter(d[:,0],d[:,1],d[:,2], c='b')
plt.show()三维可视化图:
