实验六 卷积神经网络(3)LeNet实现MNIST
目录
1.数据
1.1数据预处理
2.模型构建
3.模型训练
4.模型评价
5.模型预测
6.总结
ref
1.数据
手写体数字识别是计算机视觉中最常用的图像分类任务,让计算机识别出给定图片中的手写体数字(0-9共10个数字)。由于手写体风格差异很大,因此手写体数字识别是具有一定难度的任务。
我们采用常用的手写数字识别数据集:MNIST数据集。MNIST数据集是计算机视觉领域的经典入门数据集,包含了60,000个训练样本和10,000个测试样本。这些数字已经过尺寸标准化并位于图像中心,图像是固定大小(28×28像素)。下图给出了部分样本的示例。

为了节省训练时间,选取MNIST数据集的一个子集进行后续实验,数据集的划分为:
- 训练集:1,000条样本
- 验证集:200条样本
- 测试集:200条样本
MNIST数据集分为train_set、dev_set和test_set三个数据集,每个数据集含两个列表分别存放了图片数据以及标签数据。比如train_set包含:
- 图片数据:[1 000, 784]的二维列表,包含1 000张图片。每张图片用一个长度为784的向量表示,内容是 28×2828×28 尺寸的像素灰度值(黑白图片)。
- 标签数据:[1 000, 1]的列表,表示这些图片对应的分类标签,即0~9之间的数字。
代码实现如下:
import json
import gzip
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
# 打印并观察数据集分布情况
train_set, dev_set, test_set = json.load(gzip.open('./mnist.json.gz'))
train_images, train_labels = train_set[0][:1000], train_set[1][:1000]
dev_images, dev_labels = dev_set[0][:200], dev_set[1][:200]
test_images, test_labels = test_set[0][:200], test_set[1][:200]
train_set, dev_set, test_set = [train_images, train_labels], [dev_images, dev_labels], [test_images, test_labels]
print('Length of train/dev/test set:{}/{}/{}'.format(len(train_set[0]), len(dev_set[0]), len(test_set[0])))Length of train/dev/test set:1000/200/200可视化观察其中的一张样本以及对应的标签
image, label = train_set[0][0], train_set[1][0]
image, label = np.array(image).astype('float32'), int(label)
# 原始图像数据为长度784的行向量,需要调整为[28,28]大小的图像
image = np.reshape(image, [28,28])
image = Image.fromarray(image.astype('uint8'), mode='L')
print("The number in the picture is {}".format(label))
plt.figure(figsize=(5, 5))
plt.imshow(image)
plt.savefig('conv-number5.pdf')
plt.show()The number in the picture is 5 
1.1数据预处理
图像分类网络对输入图片的格式、大小有一定的要求,数据输入模型前,需要对数据进行预处理操作,使图片满足网络训练以及预测的需要。本实验主要应用了如下方法:
- 调整图片大小:LeNet网络对输入图片大小的要求为 32×32 ,而MNIST数据集中的原始图片大小却是 28×28 ,这里为了符合网络的结构设计,将其调整为32×32;
- 规范化: 通过规范化手段,把输入图像的分布改变成均值为0,标准差为1的标准正态分布,使得最优解的寻优过程明显会变得平缓,训练过程更容易收敛。
代码实现如下:
import torchvision.transforms as transforms
# 数据预处理
transforms = transforms.Compose([transforms.Resize(32),transforms.ToTensor(), transforms.Normalize(mean=[0.5], std=[0.5])])import random
from torch.utils.data import Dataset,DataLoader
class MNIST_dataset(Dataset):
def __init__(self, dataset, transforms, mode='train'):
self.mode = mode
self.transforms =transforms
self.dataset = dataset
def __getitem__(self, idx):
# 获取图像和标签
image, label = self.dataset[0][idx], self.dataset[1][idx]
image, label = np.array(image).astype('float32'), int(label)
image = np.reshape(image, [28,28])
image = Image.fromarray(image.astype('uint8'), mode='L')
image = self.transforms(image)
return image, label
def __len__(self):
return len(self.dataset[0])执行结果:
# 加载 mnist 数据集
train_dataset = MNIST_dataset(dataset=train_set, transforms=transforms, mode='train')
test_dataset = MNIST_dataset(dataset=test_set, transforms=transforms, mode='test')
dev_dataset = MNIST_dataset(dataset=dev_set, transforms=transforms, mode='dev')2.模型构建
LeNet-5虽然提出的时间比较早,但它是一个非常成功的神经网络模型。基于LeNet-5的手写数字识别系统在20世纪90年代被美国很多银行使用,用来识别支票上面的手写数字。LeNet-5的网络结构如下图所示。

LeNet-5和原始版本有4点不同:
- C3层没有使用连接表来减少卷积数量。
- 汇聚层使用了简单的平均汇聚,没有引入权重和偏置参数以及非线性激活函数。
- 卷积层的激活函数使用ReLU函数。
- 最后的输出层为一个全连接线性层。
网络共有7层,包含3个卷积层、2个汇聚层以及2个全连接层的简单卷积神经网络接,受输入图像大小为32×32=1024,输出对应10个类别的得分。具体实现如下:
import torch.nn.functional as F
import torch.nn as nn
class Model_LeNet(nn.Module):
def __init__(self, in_channels, num_classes=10):
super(Model_LeNet, self).__init__()
# 卷积层:输出通道数为6,卷积核大小为5×5
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=6, kernel_size=5)
# 汇聚层:汇聚窗口为2×2,步长为2
self.pool2 = nn.MaxPool2d(kernel_size=(2, 2), stride=2)
# 卷积层:输入通道数为6,输出通道数为16,卷积核大小为5×5,步长为1
self.conv3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)
# 汇聚层:汇聚窗口为2×2,步长为2
self.pool4 = nn.AvgPool2d(kernel_size=(2, 2), stride=2)
# 卷积层:输入通道数为16,输出通道数为120,卷积核大小为5×5
self.conv5 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5, stride=1)
# 全连接层:输入神经元为120,输出神经元为84
self.linear6 = nn.Linear(120, 84)
# 全连接层:输入神经元为84,输出神经元为类别数
self.linear7 = nn.Linear(84, num_classes)
def forward(self, x):
# C1:卷积层+激活函数
output = F.relu(self.conv1(x))
# S2:汇聚层
output = self.pool2(output)
# C3:卷积层+激活函数
output = F.relu(self.conv3(output))
# S4:汇聚层
output = self.pool4(output)
# C5:卷积层+激活函数
output = F.relu(self.conv5(output))
# 输入层将数据拉平[B,C,H,W] -> [B,CxHxW]
output = torch.squeeze(output, dim=3)
output = torch.squeeze(output, dim=2)
# F6:全连接层
output = F.relu(self.linear6(output))
# F7:全连接层
output = self.linear7(output)
return output使用自定义算子测试LeNet-5模型,构造一个形状为 [1,1,32,32]的输入数据送入网络,观察每一层特征图的形状变化:
# 这里用np.random创建一个随机数组作为输入数据
inputs = np.random.randn(*[1, 1, 32, 32])
inputs = inputs.astype('float32')
# 创建Model_LeNet类的实例,指定模型名称和分类的类别数目
model = Model_LeNet(in_channels=1, num_classes=10)
print(model)
# 通过调用LeNet从基类继承的sublayers()函数,查看LeNet中所包含的子层
print(model.named_parameters())
x = torch.tensor(inputs)
print(x)
for item in model.children():
# item是LeNet类中的一个子层
# 查看经过子层之后的输出数据形状
item_shapex = 0
names = []
parameter = []
for name in item.named_parameters():
names.append(name[0])
parameter.append(name[1])
item_shapex += 1
try:
x = item(x)
except:
# 如果是最后一个卷积层输出,需要展平后才可以送入全连接层
x = x.reshape([x.shape[0], -1])
x = item(x)
if item_shapex == 2:
# 查看卷积和全连接层的数据和参数的形状,
# 其中item.parameters()[0]是权重参数w,item.parameters()[1]是偏置参数b
print(item, x.shape, parameter[0].shape, parameter[1].shape)
else:
# 汇聚层没有参数
print(item, x.shape)执行结果:
Model_LeNet(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(pool2): MaxPool2d(kernel_size=(2, 2), stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(pool4): AvgPool2d(kernel_size=(2, 2), stride=2, padding=0)
(conv5): Conv2d(16, 120, kernel_size=(5, 5), stride=(1, 1))
(linear6): Linear(in_features=120, out_features=84, bias=True)
(linear7): Linear(in_features=84, out_features=10, bias=True))从输出结果看,
- 对于大小为32×3232×32的单通道图像,先用6个大小为5×55×5的卷积核对其进行卷积运算,输出为6个28×2828×28大小的特征图;
- 6个28×2828×28大小的特征图经过大小为2×22×2,步长为2的汇聚层后,输出特征图的大小变为14×1414×14;
- 6个14×1414×14大小的特征图再经过16个大小为5×55×5的卷积核对其进行卷积运算,得到16个10×1010×10大小的输出特征图;
- 16个10×1010×10大小的特征图经过大小为2×22×2,步长为2的汇聚层后,输出特征图的大小变为5×55×5;
- 16个5×55×5大小的特征图再经过120个大小为5×55×5的卷积核对其进行卷积运算,得到120个1×11×1大小的输出特征图;
- 此时,将特征图展平成1维,则有120个像素点,经过输入神经元个数为120,输出神经元个数为84的全连接层后,输出的长度变为84。
- 再经过一个全连接层的计算,最终得到了长度为类别数的输出结果。
使用pytorch中的相应算子torch.nn.Conv2d();torch.nn.MaxPool2d();torch.nn.avg_pool2d()构建模型:
class Torch_LeNet(nn.Module):
def __init__(self, in_channels, num_classes=10):
super(Torch_LeNet, self).__init__()
# 卷积层:输出通道数为6,卷积核大小为5*5
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=6, kernel_size=5)
# 汇聚层:汇聚窗口为2*2,步长为2
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 卷积层:输入通道数为6,输出通道数为16,卷积核大小为5*5
self.conv3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
# 汇聚层:汇聚窗口为2*2,步长为2
self.pool4 = nn.AvgPool2d(kernel_size=2, stride=2)
# 卷积层:输入通道数为16,输出通道数为120,卷积核大小为5*5
self.conv5 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)
# 全连接层:输入神经元为120,输出神经元为84
self.linear6 = nn.Linear(in_features=120, out_features=84)
# 全连接层:输入神经元为84,输出神经元为类别数
self.linear7 = nn.Linear(in_features=84, out_features=num_classes)
def forward(self, x):
# C1:卷积层+激活函数
output = F.relu(self.conv1(x))
# S2:汇聚层
output = self.pool2(output)
# C3:卷积层+激活函数
output = F.relu(self.conv3(output))
# S4:汇聚层
output = self.pool4(output)
# C5:卷积层+激活函数
output = F.relu(self.conv5(output))
# 输入层将数据拉平[B,C,H,W] -> [B,CxHxW]
output = torch.squeeze(output, dim=3)
output = torch.squeeze(output, dim=2)
# F6:全连接层
output = F.relu(self.linear6(output))
# F7:全连接层
output = self.linear7(output)
return output测试两个网络的运算速度
import time
# 这里用np.random创建一个随机数组作为测试数据
inputs = np.random.randn(*[1,1,32,32])
inputs = inputs.astype('float32')
x = torch.tensor(inputs)
# 创建Model_LeNet类的实例,指定模型名称和分类的类别数目
model = Model_LeNet(in_channels=1, num_classes=10)
# 创建Torch_LeNet类的实例,指定模型名称和分类的类别数目
torch_model = Torch_LeNet(in_channels=1, num_classes=10)
# 计算Model_LeNet类的运算速度
model_time = 0
for i in range(60):
strat_time = time.time()
out = model(x)
end_time = time.time()
# 预热10次运算,不计入最终速度统计
if i < 10:
continue
model_time += (end_time - strat_time)
avg_model_time = model_time / 50
print('Model_LeNet speed:', avg_model_time, 's')
# 计算Torch_LeNet类的运算速度
torch_model_time = 0
for i in range(60):
strat_time = time.time()
torch_out = torch_model(x)
end_time = time.time()
# 预热10次运算,不计入最终速度统计
if i < 10:
continue
torch_model_time += (end_time - strat_time)
avg_torch_model_time = torch_model_time / 50
print('Torch_LeNet speed:', avg_torch_model_time, 's')令两个网络加载同样的权重,测试一下两个网络的输出结果是否一致。
# 这里用np.random创建一个随机数组作为测试数据
inputs = np.random.randn(*[1,1,32,32])
inputs = inputs.astype('float32')
x = torch.tensor(inputs)
# 创建Model_LeNet类的实例,指定模型名称和分类的类别数目
model = Model_LeNet(in_channels=1, num_classes=10)
# 获取网络的权重
params = model.state_dict()
# 自定义Conv2D算子的bias参数形状为[out_channels, 1]
# torch API中Conv2D算子的bias参数形状为[out_channels]
# 需要进行调整后才可以赋值
for key in params:
if 'bias' in key:
params[key] = params[key].squeeze()
# 创建Torch_LeNet类的实例,指定模型名称和分类的类别数目
torch_model = Torch_LeNet(in_channels=1, num_classes=10)
# 将Model_LeNet的权重参数赋予给Torch_LeNet模型,保持两者一致
torch_model.load_state_dict(params)
# 打印结果保留小数点后6位
torch.set_printoptions(6)
# 计算Model_LeNet的结果
output = model(x)
print('Model_LeNet output: ', output)
# 计算Torch_LeNet的结果
torch_output = torch_model(x)
print('Torch_LeNet output: ', torch_output)执行结果:
Model_LeNet speed: 0.0004591846466064453 s
Torch_LeNet speed: 0.00040879726409912107 s统计LeNet-5模型的参数量和计算量。
参数量:
- 第一个卷积层的参数量为:6×1×5×5+6=1566×1×5×5+6=156;
- 第二个卷积层的参数量为:16×6×5×5+16=241616×6×5×5+16=2416;
- 第三个卷积层的参数量为:120×16×5×5+120=48120120×16×5×5+120=48120;
- 第一个全连接层的参数量为:120×84+84=10164120×84+84=10164;
- 第二个全连接层的参数量为:84×10+10=85084×10+10=850;
所以,LeNet-5总的参数量为6170661706。
from torchsummary import summary
model = Torch_LeNet(in_channels=1, num_classes=10)
params_info = summary(model, (1, 32, 32))
print(params_info)计算量:
- 第一个卷积层的计算量为:28×28×5×5×6×1+28×28×6=12230428×28×5×5×6×1+28×28×6=122304;
- 第二个卷积层的计算量为:10×10×5×5×16×6+10×10×16=24160010×10×5×5×16×6+10×10×16=241600;
- 第三个卷积层的计算量为:1×1×5×5×120×16+1×1×120=481201×1×5×5×120×16+1×1×120=48120;
- 平均汇聚层的计算量为:16×5×5=40016×5×5=400
- 第一个全连接层的计算量为:120×84=10080120×84=10080;
- 第二个全连接层的计算量为:84×10=84084×10=840;
所以,LeNet-5总的计算量为423344423344。
3.模型训练
使用交叉熵损失函数,并用随机梯度下降法作为优化器来训练LeNet-5网络。
用RunnerV3在训练集上训练5个epoch,并保存准确率最高的模型作为最佳模型。
代码实现如下:
import torch.optim as opti
# 学习率大小
lr = 0.1
# 批次大小
batch_size = 64
# 加载数据
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
# 定义LeNet网络
# 自定义算子实现的LeNet-5
model = Model_LeNet(in_channels=1, num_classes=10)
# 飞桨API实现的LeNet-5
# model = Paddle_LeNet(in_channels=1, num_classes=10)
# 定义优化器
optimizer = opti.SGD(model.parameters(), 0.2)
# 定义损失函数
loss_fn = F.cross_entropy
# 定义评价指标
metric = Accuracy()
# 实例化 RunnerV3 类,并传入训练配置。
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 启动训练
log_steps = 15
eval_steps = 15
runner.train(train_loader, dev_loader, num_epochs=6, log_steps=log_steps,
eval_steps=eval_steps, save_path="best_model.pdparams")执行结果:
[Train] epoch: 0/6, step: 0/282, loss: 2.29905
[Train] epoch: 0/6, step: 15/282, loss: 2.23999
[Evaluate] dev score: 0.31500, dev loss: 2.21313
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.31500
[Train] epoch: 0/6, step: 30/282, loss: 2.58734
[Evaluate] dev score: 0.19500, dev loss: 2.11329
[Train] epoch: 0/6, step: 45/282, loss: 1.34715
[Evaluate] dev score: 0.54000, dev loss: 1.30158
[Evaluate] best accuracy performence has been updated: 0.31500 --> 0.54000
[Train] epoch: 1/6, step: 60/282, loss: 0.55707
[Evaluate] dev score: 0.66500, dev loss: 0.79478
[Evaluate] best accuracy performence has been updated: 0.54000 --> 0.66500
[Train] epoch: 1/6, step: 75/282, loss: 0.48563
[Evaluate] dev score: 0.75500, dev loss: 0.65858
[Evaluate] best accuracy performence has been updated: 0.66500 --> 0.75500
[Train] epoch: 1/6, step: 90/282, loss: 0.49290
[Evaluate] dev score: 0.88500, dev loss: 0.32061
[Evaluate] best accuracy performence has been updated: 0.75500 --> 0.88500
[Train] epoch: 2/6, step: 105/282, loss: 0.48224
[Evaluate] dev score: 0.88500, dev loss: 0.34361
[Train] epoch: 2/6, step: 120/282, loss: 0.19128
[Evaluate] dev score: 0.90000, dev loss: 0.25008
[Evaluate] best accuracy performence has been updated: 0.88500 --> 0.90000
[Train] epoch: 2/6, step: 135/282, loss: 0.17086
[Evaluate] dev score: 0.89000, dev loss: 0.26294
[Train] epoch: 3/6, step: 150/282, loss: 0.19276
[Evaluate] dev score: 0.92500, dev loss: 0.20595
[Evaluate] best accuracy performence has been updated: 0.90000 --> 0.92500
[Train] epoch: 3/6, step: 165/282, loss: 0.06706
[Evaluate] dev score: 0.94000, dev loss: 0.15123
[Evaluate] best accuracy performence has been updated: 0.92500 --> 0.94000
[Train] epoch: 3/6, step: 180/282, loss: 0.14544
[Evaluate] dev score: 0.91500, dev loss: 0.16170
[Train] epoch: 4/6, step: 195/282, loss: 0.11370
[Evaluate] dev score: 0.92500, dev loss: 0.19576
[Train] epoch: 4/6, step: 210/282, loss: 0.05933
[Evaluate] dev score: 0.95000, dev loss: 0.12437
[Evaluate] best accuracy performence has been updated: 0.94000 --> 0.95000
[Train] epoch: 4/6, step: 225/282, loss: 0.10014
[Evaluate] dev score: 0.96000, dev loss: 0.11082
[Evaluate] best accuracy performence has been updated: 0.95000 --> 0.96000
[Train] epoch: 5/6, step: 240/282, loss: 0.12507
[Evaluate] dev score: 0.96000, dev loss: 0.10781
[Train] epoch: 5/6, step: 255/282, loss: 0.07938
[Evaluate] dev score: 0.97000, dev loss: 0.11359
[Evaluate] best accuracy performence has been updated: 0.96000 --> 0.97000
[Train] epoch: 5/6, step: 270/282, loss: 0.13051
[Evaluate] dev score: 0.96000, dev loss: 0.09845
[Evaluate] dev score: 0.94500, dev loss: 0.14964
[Train] Training done!
4.模型评价
使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及损失变化情况。
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))执行结果:
[Test] accuracy/loss: 0.8620/0.42435.模型预测
可以使用保存好的模型,对测试集中的某一个数据进行模型预测,观察模型效果。
# 获取测试集中第一条数据
X, label = next(test_loader())
logits = runner.predict(X)
# 多分类,使用softmax计算预测概率
pred = F.softmax(logits)
# 获取概率最大的类别
pred_class = paddle.argmax(pred[1]).numpy()
label = label[1][0].numpy()
# 输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label[0], pred_class[0]))
# 可视化图片
plt.figure(figsize=(2, 2))
image, label = test_set[0][1], test_set[1][1]
image= np.array(image).astype('float32')
image = np.reshape(image, [28,28])
image = Image.fromarray(image.astype('uint8'), mode='L')
plt.imshow(image)
plt.savefig('cnn-number2.pdf')The true category is 2 and the predicted category is 26.总结
从上述的结果可以看出LeNet对于手写数字识别这方面已经是相当完善了,老师也说到LeNet的重要,作为卷积神经网络的“Hello World”,那就简单总结以下LeNet到底有什么。
LeNet是卷积神经网络最早的领头者LeCun在1998年提出,用于解决手写数字识别的视觉任务。当年美国大多数银行就是用它来识别支票上面的手写数字的,它是早期卷积神经网络中最有代表性的实验系统之一。自那时起,CNN的最基本的架构就定下来了:卷积层、池化层、全连接层。
之后有了LenNet-5,共有7层(不包括输入层),每层都包含不同数量的训练参数。
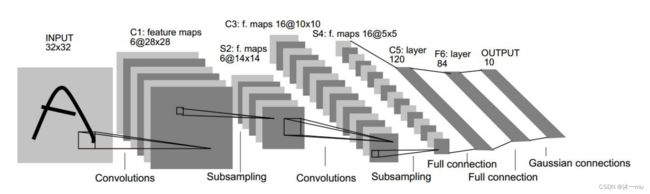
LeNet-5第一层:卷积层C1
C1层是卷积层,形成6个特征图谱。卷积的输入区域大小是5x5,每个特征图谱内参数共享,即每个特征图谱内只使用一个共同卷积核,卷积核有5x5个连接参数加上1个偏置共26个参数。卷积区域每次滑动一个像素,这样卷积层形成的每个特征图谱大小是(32-5)/1+1=28x28。C1层共有26x6=156个训练参数,有(5x5+1)x28x28x6=122304个连接。
LeNet-5第二层:池化层S2
S2层是一个下采样层(为什么是下采样?利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息)。C1层的6个28x28的特征图谱分别进行以2x2为单位的下抽样得到6个14x14((28-2)/2+1)的图。每个特征图谱使用一个下抽样核。5x14x14x6=5880个连接。
LeNet-5第三层:卷积层C3
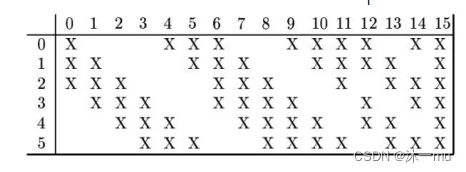
C3层是一个卷积层,卷积和和C1相同,不同的是C3的每个节点与S2中的多个图相连。C3层有16个10x10(14-5+1)的图,每个图与S2层的连接的方式如下表所示:
LeNet-5第四层:池化层S4
S4是一个下采样层。C3层的16个10x10的图分别进行以2x2为单位的下抽样得到16个5x5的图。5x5x5x16=2000个连接。连接的方式与S2层类似。
LeNet-5第五层:全连接层C5
C5层是一个全连接层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。
LeNet-5第六层:全连接层F6
F6层是全连接层。F6层有84个节点,对应于一个7x12的比特图,该层的训练参数和连接数都是(120 + 1)x84=10164。
LeNet-5第七层:全连接层Output
Output层也是全连接层,共有10个节点,分别代表数字0到9,如果节点i的输出值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:
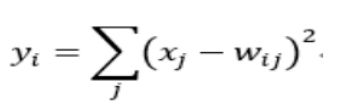
LeNet5特征能够总结为如下几点:
1)卷积神经网络使用三个层作为一个系列: 卷积,池化,非线性;
2)使用卷积提取空间特征;
3)使用映射到空间均值下采样(subsample);
4)双曲线(tanh)或S型(sigmoid)形式的非线性;
5)多层神经网络(MLP)作为最后的分类器;
6)层与层之间的稀疏连接矩阵避免大的计算成本。
最后也是如果想起来LeNet就可以方便打开看一看。
ref
NNDL 实验5(上) - HBU_DAVID - 博客园
NNDL 实验5(下) - HBU_DAVID - 博客园
CNN发展简史——LeNet(一)_Y.Z.Y.的博客-CSDN博客_lenet什么时候