【聚类分析】谱系聚类(层次聚类)
1 简介

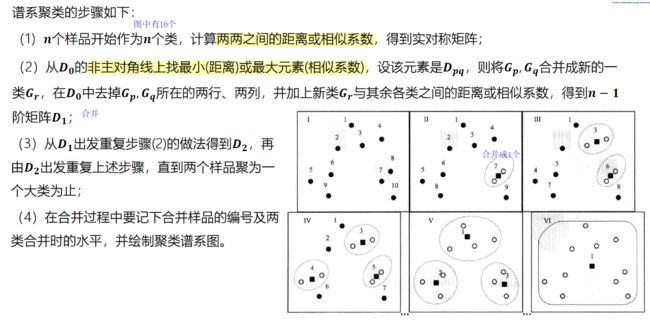
2 步骤
谱系聚类最终结果是形成一个大类
3 实现函数








4 案例1

cd C:\Users\TL\Desktop\【聚类分析】谱系聚类(层次聚类)
drink = xlsread('drink.xlsx');
d = pdist(drink); %欧式距离 step1-计算距离
z1= linkage(d); %默认最短距离 step2-距离评价方法
subplot(2,2,1)
H= dendrogram(z1); %谱系聚类图 step3-绘图
title('最短距离聚类')
subplot(2,2,2)
z2= linkage(d,'complete'); %使用最长距离
Hc= dendrogram(z2); %谱系聚类图
title('最长距离聚类')
subplot(2,2,3)
z3= linkage(d,'average'); %类平均距离
Ha= dendrogram(z3); %谱系聚类图
title('类平均距离聚类')
subplot(2,2,4)
z4= linkage(d,'ward'); %离差平方和距离
Hw= dendrogram(z4); %谱系聚类图
title('离差平方和距离聚类')

对于单独成为1类的数据,需要特别解释说明。(如第7个样本)
四种方法由于类与类之间的距离计算方法不同,所得到的结果略有出入,其中最短距离法与其余三种差别最大。以离差平方和为例,编号为12、14、 2、4、13、3、8、11的饮料归为第一大类,其余在第二类。
根据图形效果,把16种饮料细分为4类,通过函数cluster(z4,4)可以将数据分组,以序号1、2、3、4分别表示4个类别:12,14为一类;2,3,4,8,11,13为一类;1,10为一类;5,6,7,9,15,16为一类。
T=cluster(z1,4) %分类,并编号
id=1:16;
res=cell(16,2); %生成16行2列的数据
res(:,1)=num2cell(id);
res(:,2)=num2cell(T);
res=sortrows(res,2)


R=[cophenet(z1,d),cophenet(z2,d),cophenet(z3,d),cophenet(z4,d)]

5 案例2

cd C:\Users\TL\Desktop\【聚类分析】谱系聚类(层次聚类)
[sale,text] = xlsread('sale_houseprice.xlsx'); %既要文本,也要数据
sale = zscore(sale); %标准化,去除量纲影响
d = pdist(sale); %欧式距离
z= linkage(d,'average'); %类平均距离
labels = text(3:end,1); %设置标签
%绘制谱系图,参数设置
dendrogram(z,'ColorThreshold','default','Labels',labels,'Orientation','left'); %谱系聚类图
title('全国的主要省份房价聚类——(欧式,数据标准化后)类平均距离')
T=cluster(z,4); %输出4类聚类结果
CA = cell(25,2); %用元胞数组组合
CA(:,1) = labels;
CA(:,2) = num2cell(T); %类别
CA = sortrows(CA,2) %按类别扩展排序

对应核密度图
%分开类别
s1 = sale(T == 1,:);
s2 = sale(T == 2,:);
s3 = sale(T == 3,:);
s4 = sale(T == 4,:);
subplot(2,2,1)
[f,xi]=ksdensity(s1(:,6)); %第6列为房价
plot(xi,f); title('聚类1——房价指标')
subplot(2,2,2)
[f,xi]=ksdensity(s2(:,6));
plot(xi,f); title('聚类2——房价指标')
subplot(2,2,3)
[f,xi]=ksdensity(s3(:,6));
plot(xi,f); title('聚类3——房价指标')
subplot(2,2,4)
[f,xi]=ksdensity(s4(:,6));
plot(xi,f); title('聚类4——房价指标')

从4个聚类结果,分别绘制房价指标核密度估计曲线图,从曲线上仍能分析出其区别,如聚类1房价范围在[-0.8,-0.2]左右,聚类2在[0.2,0.8]左右,聚类3在[0.3,1.2]左右,聚类4存在双峰,且与其他类别区别较大。此外,由于样本较少,核密度估计可能存在不准确。
可以看出分类效果是否明显
并且根据曲线颜色可以分组

默认最大标签为30,需要设置参数0

[orig,text] = xlsread('Z0816C-2013Orig');
md = pdist(orig,'mahalanobis'); %马氏距离
Z = linkage(md,'average'); %类平均距离
labels = text(7:end,1);绘图时,标签中有数字,所以需要设置dendrogram参数
Ha=dendrogram(Z,'ColorThreshold',0.5*max(Z(:,3)),'Labels',labels,'Orientation','left'); %谱系聚类图
title('全国主要城市废气污染指标聚类——(马氏)类平均距离')
设置dendrogram参数,加个0
Ha=dendrogram(Z,0,'ColorThreshold',0.5*max(Z(:,3)),'Labels',labels,'Orientation','left'); %谱系聚类图
title('全国主要城市废气污染指标聚类——(马氏)类平均距离')
文本输出分类结果
T=cluster(Z,6); %输出4类聚类结果
CA = cell(31,2); %用元胞数组组合
CA(:,1) = labels; %城市名称
CA(:,2) = num2cell(T); %类别
CA = sortrows(CA,2) %按类别扩展排序
主成分分析+聚类
%主成分分析+聚类
[sale,text] = xlsread('sale_houseprice.xlsx');
sale = zscore(sale);
[coeff,score,latent,~,explained] = pca(sale);
% 选取前四个主成分,解释方差度为%96.6454
salepca = sale*coeff(:,1:4);
d = pdist(salepca,'mahalanobis'); %马氏距离
z= linkage(d,'average'); %类平均距离
labels = text(3:end,1);
dendrogram(z,'ColorThreshold',0.4*max(z(:,3)),'Labels',labels,'Orientation','left');
%谱系聚类图title('全国的主要省份房价聚类——(马氏 + 主成分)类平均距离距离')

与前期分析差异不大,且主成分降维后,聚类效果比较合理。
6 案例3-R型聚类

[cand,text] = xlsread('candidate.xlsx');
candcoef = corrcoef(cand);
d = pdist(candcoef,'correlation'); %相关距离
z= linkage(d,'average'); %类平均距离
labels = text(2,2:end);
dendrogram(z,'ColorThreshold',0.4*max(z(:,3)),'Labels',labels,'Orientation','left'); %谱系聚类图
title('公司招聘变量(指标)聚类——(相关距离)类平均距离距离')
12.4-2 聚类分析 - 谱系聚类案例讲解_哔哩哔哩_bilibili