python Pandas庫的學習
Pandas
Series對象
Series 對象用於表示一維的數據結構,其主數組的每個元素都會有一個與之相關聯的標簽。(大致如下圖所示)
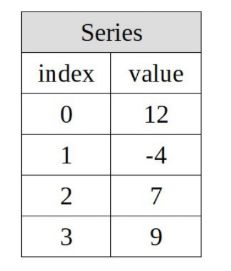
對象的聲明
通過 pd.Series() 進行聲明,在未指定標簽的情況下,默認使用從0開始一次遞增的數值作爲標簽。
s = pd.Series([12, -4, 7, 9])
print(s)
------------------------------------
0 12
1 -4
2 7
3 9
dtype: int64
s = pd.Series([12, -4, 7, 9], index=["A", "B", "C", "D"])
print(s)
-------------------------------
A 12
B -4
C 7
D 9
dtype: int64
當然,也可以通過其他的形式來聲明對象(操作如下:
注意,在這種情況下,如果原有對象的值改變,則 Series 對象中的元素也會發生改變。
arr = np.array([1, 2, 3, 4])
s = pd.Series(arr)
print(s)
--------------------------------
0 1
1 2
2 3
3 4
dtype: int32
Series 亦可使用字典來進行初始化(其格式其實與字典相差無几)。
my_dict = {"red":100, "blue":200,"green":300}
s = pd.Series(my_dict)
print(s)
-----------------------------------
red 100
blue 200
green 300
dtype: int64
屬性的獲取
毫無疑問,可以獲取 Seris 的兩個屬性,Index 和 Values。
s = pd.Series([12, -4, 7, 9], index = ["A", "B", "C", "D"])
print(s)
print("values:",s.values)
print("index:",s.index)
----------------------------------
A 12
B -4
C 7
D 9
dtype: int64
values: [12 -4 7 9]
index: Index(['A', 'B', 'C', 'D'], dtype='object')
對象操作
元素賦值
通過下標或索引對元素進行賦值。
s = pd.Series([12, -4, 7, 9], index=["A", "B", "C", "D"])
print(s)
s[0] = 0
print("0:",s[0])
s["B"] = 0
print("B",s["B"])
-----------------------------------
A 12
B -4
C 7
D 9
dtype: int64
0: 0
B 0
元素篩選
s[s > x],用於篩選 Series數組中元素值大於 x 的元素。
s = pd.Series([10, 5, -5, 12], index=["A", "B", "C", "D"])
print(s)
print()
print(s[s > 8])
--------------------------
A 10
B 5
C -5
D 12
dtype: int64
A 10
D 12
dtype: int64
元素運算
由於可將 Series 看作 np.narray的升級版,故在對象運算和數學函數時,兩者的表現均一樣。(加減乘除、取對數等等,不再進行過多演示
import pandas as pd
s = pd.Series([12, 5, 4, 9])
print(s)
s = s - 2
print(s)
-------------------------
0 12
1 5
2 4
3 9
dtype: int64
0 10
1 3
2 2
3 7
dtype: int64
元素去重
若要對 Series 對象進行去重,則需調用函數 unique(),注意,去重后順序可能發生變化。
import pandas as pd
s = pd.Series([12, 5, 9, 4, 4, 5, 5])
print("去重前:",s.values)
s = s.unique()
print("去重后",s)
--------------------------------------
去重前: [12 5 9 4 4 5 5]
去重后 [12 5 9 4]
元素出現頻度
使用函數 $Series.value_counts() 即可計算其中元素的頻度。
s = pd.Series([12, 5, 5, 5, 1, 1, 2])
print(s.value_counts())
---------------------------------
5 3
1 2
12 1
2 1
dtype: int64
所屬關係判斷
使用函數 Series.isin()即可進行判斷,另外,其也可以作爲一個篩選條件哦。
s = pd.Series([1, 5, 8, 10, 15])
print(s.isin([5,10]))
print()
print(s[s.isin([5, 10])])
--------------------------------------
0 False
1 True
2 False
3 True
4 False
dtype: bool
1 5
3 10
dtype: int64
NaN
NaN,即 Not a Number,儅進行數據處理時而其中某項屬性丟失時(或未收集到時)可以使用。另外,可配合 isnull() 和 notnull()進行食用。(不是
另外請注意,雖然在 Pandas裏介紹NaN,但其聲明是:np.NaN。
isnull() 是函數, isnull 可將其看作一種屬性,可以用於在元素篩選。
s = pd.Series([12, 5, np.NaN, 10])
print(s[pd.isnull])
print()
print(s.isnull())
print()
print(s.notnull())
-----------------------------------
2 NaN
dtype: float64
0 False
1 False
2 True
3 False
dtype: bool
0 True
1 True
2 False
3 True
dtype: bool
對象閒的運算
考慮到 Series 對象之間的運算,其實類似于 narray 裏的廣播機制,但不同的是,此處僅會有共同標簽(index)的屬性才會有結果,否則為 NaN(非數)。
s1 = pd.Series([10, 5, 2],index=["R", "G", "B"])
s2 = pd.Series([5, 2, 1],index=["G", "B", "F"])
print(s1 + s2)
----------------------------------
B 4.0
F NaN
G 10.0
R NaN
dtype: float64
DataFrame對象
DateFrame 實際上就是多維的 Series(也可以考慮為多個 Series 的組合)。其有兩個索引,行索引,和列索引(可把 DataFrame 中的列索引想作單個 Series 中的行索引)。
也可將 DataFrame 看作由 Series 組成的字典。
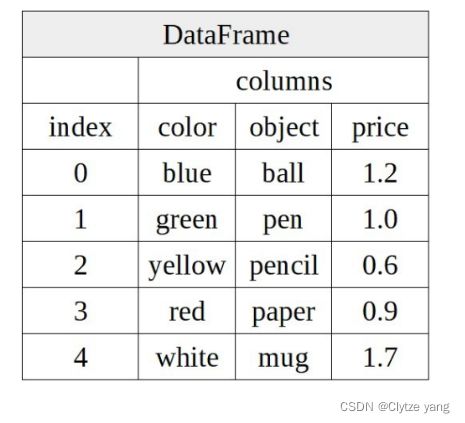
對象的聲明
可以通過一個字典 + 列表進行初始化。
my_dict = {"color":["R", "G", "B"],
"object":["you", "me", "him"],
"value":[1, 3, 5]}
frame = pd.DataFrame(my_dict,index=["A", "B", "C"])
print(frame)
-------------------------------------
color object value
A R you 1
B G me 3
C B him 5
DataFrame 中存在屬性 clolumns,即可以達到對列表進行提純的作用,也可以在對 DataFrame 進行初始化時使用。
my_dict = {"color":["R", "G", "B"],
"object":["you", "me", "him"],
"value":[1, 3, 5]}
frame = pd.DataFrame(my_dict, columns=["color","value"])
print(frame)
-------------------------------------
color value
0 R 1
1 G 3
2 B 5
frame = pd.DataFrame(np.arange(25).reshape(5, 5), columns=["A", "B", "C", "D", "E"],
index=["1", "2", "3", "4", "5"])
print(frame)
------------------------------------
A B C D E
1 0 1 2 3 4
2 5 6 7 8 9
3 10 11 12 13 14
4 15 16 17 18 19
5 20 21 22 23 24
對象操作
元素選取
考慮到 DataFrames 存在著許多屬性,因此有許多方法可以對元素進行選取。
DataFrame.columns: 獲取所有列的名稱(其實就是最上面那一排)
dict_data = {"color":["R", "G", "B"],
"object":["pen","pan","pencil"],
"value":[100, 200, 300]}
frame = pd.DataFrame(dict_data)
print(frame.columns)
--------------------------------
Index(['color', 'object', 'value'], dtype='object')
DataFrame.values:獲取其中的每個元素,以列表存儲。([列名1_1,列名1_2,…],[],…)
dict_data = {"color":["R", "G", "B"],
"object":["pen","pan","pencil"],
"value":[100, 200, 300]}
frame = pd.DataFrame(dict_data)
print(frame.values)
------------------------------------------
[['R' 'pen' 100]
['G' 'pan' 200]
['B' 'pencil' 300]]
DataFrame.index:獲取行索引(其實就是最左邊竪著的那一排啦~)
dict_data = {"color":["R", "G", "B"],
"object":["pen","pan","pencil"],
"value":[100, 200, 300]}
frame = pd.DataFrame(dict_data)
print(frame.index)
-------------------------------------
RangeIndex(start=0, stop=3, step=1)
直接通過索引進行獲取(既然是[],肯定能通過這種方式獲取拉~)
dict_data = {"color":["R", "G", "B"],
"object":["pen","pan","pencil"],
"value":[100, 200, 300]}
frame = pd.DataFrame(dict_data)
print(frame["value"])
print()
print(frame.loc[1])
print()
print(frame["object"][1])
----------------------------
0 100
1 200
2 300
Name: value, dtype: int64
color G
object pan
value 200
Name: 1, dtype: object
pan
多行選取(即數組的切片操作)
此處需注意,frame[0:2]為正確操作,而frame[0]則為錯誤操作哦!
dict_data = {"color":["R", "G", "B"],
"object":["pen","pan","pencil"],
"value":[100, 200, 300]}
frame = pd.DataFrame(dict_data)
print(frame[0:2])
---------------------------------
color object value
0 R pen 100
1 G pan 200
元素賦值
部分值的賦值如同 Series 對象,但在 DataFrame 這裏還有添加列的操作哦~
ps:不能理解爲什麽此處 A 在前面┭┮﹏┭┮
frame = pd.DataFrame(np.arange(25).reshape(5, 5),
columns=["A", "B", "C", "D", "E"],
index=["a", "b", "c", "d", "e"])
frame["A"]["a"] = 100
print(frame)
-------------------------------
A B C D E
a 100 1 2 3 4
b 5 6 7 8 9
c 10 11 12 13 14
d 15 16 17 18 19
e 20 21 22 23 24
添加新的列。簡單的使用 frame[] = [],即可,類似於字典的添加操作。
不過請注意保持元素的個數一致哦~
frame = pd.DataFrame(np.arange(25).reshape(5, 5),
columns=["A", "B", "C", "D", "E"],
index=["a", "b", "c", "d", "e"])
frame["hahaha!"] = [1, 2, 3, 4, 5]
print(frame)
---------------------------
A B C D E hahaha!
a 0 1 2 3 4 1
b 5 6 7 8 9 2
c 10 11 12 13 14 3
d 15 16 17 18 19 4
e 20 21 22 23 24 5
所屬關係
大致與 Series 中的相同,不在過多闡釋。
(ps:可以看上下的結果對比一下哦
frame = pd.DataFrame(np.arange(25).reshape(5, 5),
columns=["A", "B", "C", "D", "E"],
index=["a", "b", "c", "d", "e"])
print(frame.isin([4, 1]))
------------------------------------
A B C D E hahaha!
a False True False False True True
b False False False False False False
c False False False False False False
d False False False False False True
e False False False False False False
元素篩選
同上。(看看代碼即可
frame = pd.DataFrame(np.arange(25).reshape(5, 5),
columns=["A", "B", "C", "D", "E"],
index=["a", "b", "c", "d", "e"])
print(frame[frame >= 20])
#此處可能數組名亦可代表每個元素的變量名(不是很懂
-------------------------------------
A B C D E hahaha!
a NaN NaN NaN NaN NaN NaN
b NaN NaN NaN NaN NaN NaN
c NaN NaN NaN NaN NaN NaN
d NaN NaN NaN NaN NaN NaN
e 20.0 21.0 22.0 23.0 24.0 NaN
刪除列
调用 del DataFrame[列名] 即可。(应用广泛,但也说明一下)
frame = pd.DataFrame(np.arange(25).reshape(5, 5),
columns=["A", "B", "C", "D", "E"],
index=["a", "b", "c", "d", "e"])
del frame["A"]
print(frame)
-----------------------------
B C D E
a 1 2 3 4
b 6 7 8 9
c 11 12 13 14
d 16 17 18 19
e 21 22 23 24
转置
调用 DataFrame 中的属性 T即可进行轉置。
frame = pd.DataFrame(np.arange(25).reshape(5, 5),
columns=["A", "B", "C", "D", "E"],
index=["a", "b", "c", "d", "e"])
print(frame.T)
---------------------------
a b c d e
B 1 6 11 16 21
C 2 7 12 17 22
D 3 8 13 18 23
E 4 9 14 19 24
Index對象
Index對象即是上文所使用的數組的軸(橫、竪)。
方法使用
獲取索引的最小值, XXX.idxmin()。
s = pd.Series([5, 10, 15, 20],index=["a1", "b2", "c3", "d4"])
print(s.index)
print(s.idxmin())
---------------------------
Index(['a1', 'b2', 'c3', 'd4'], dtype='object')
a1
獲取索引的最大值, XXX.idxmax()。
ps:比較方法即對各個字符串進行比較,字符串之間的比較方法不再進行過多的闡釋。
s = pd.Series([5, 10, 15, 20],index=["a1", "b2", "c3", "d4"])
print(s.index)
print(s.idxmax())
----------------------------------------
Index(['a1', 'b2', 'c3', 'd4'], dtype='object')
d4
索引更換
當你對數組中當前的索引不滿意時,可以用 reindex() 函數來更換對象的索引。
另外,若增加了新的索引,會添加NaN作爲新索引的數值。
(再另外,爲什麽不開始就初始化令您滿意的索引呢(不是
s = pd.Series([5, 10, 15, 20],index=["a1", "b2", "c3", "d4"])
print(s)
s = s.reindex(["a1", "B", "c3", "D","d4"])
print(s)
-----------------------------
a1 5
b2 10
c3 15
d4 20
dtype: int64
a1 5.0
B NaN
c3 15.0
D NaN
d4 20.0
dtype: float64
reindex() 具有參數 method,即是參數的填補方法。
若 method = “ffill”,即 front fill,用前一個下標來對當前的 NaN 的值進行填充。
method = “bfill”,即back fill,于上描述相反。
frame = pd.DataFrame(np.arange(9).reshape(3, 3),columns=["A", "B", "C"],
index=["a", "b", "c"])
print(frame)
frame = frame.reindex(["a", "d", "daa!", "b"],method="ffill")
print(frame)
------------------------------------------
A B C
a 0 1 2
b 3 4 5
c 6 7 8
A B C
a 0 1 2
d 6 7 8
daa! 6 7 8
b 3 4 5
或,可直接使用 fill_value = 0,即將默認的NaN 填充為 0。
(這個就不再進行演示了≡(▔﹏▔)≡
刪除索引
同 del Array[] 相同,不過這裏是換了另外一個函數 .drop() 進行處理。
ps:Series(DataFrame亦是)似乎為不可變對象,因此要使用s = s.drop(“A”),而非單單的 s.drop(“A”)。請謹記。
s = pd.Series(np.arange(4), index=["A", "B", "C", "d"])
print(s)
print()
s = s.drop("A")
print(s)
--------------------------
A 0
B 1
C 2
d 3
dtype: int32
B 1
C 2
d 3
dtype: int32
數據對齊
與 Series 之間進行相加一樣,礙於篇幅過長,不再進行闡釋。
數據結構之間的運算
數據結構之間可直接通過算數運算符進行運算,當然也可以通過下列的方法達到相同的目的。
add()
sub()
div ()
sub()
字如其人,不再解釋。
運算
通過加法來對運算的原理進行演示。
注意,這裏的 Series 對齊的是 DataFrame 裏的列名稱(columns) 而非 index。
frame = pd.DataFrame(np.arange(9).reshape(3, 3),
index = ["A", "B", "C"],
columns=["a", "b", "c"])
ser = pd.Series(np.arange(3), index=["a", "b", "c"])
print(frame + ser)
-------------------------------
a b c
A 0 2 4
B 3 5 7
C 6 8 10
其餘運算也與上述的演示同理。
函數應用和映射
通用函數
平方根
np.sqrt() 可以求序列中每個元素的平方根。
frame = pd.DataFrame(np.arange(9).reshape(3, 3),
columns=["A", "B", "C"],
index=["a", "B", "c"])
print(np.sqrt(frame))
--------------------------------------------
A B C
a 0.000000 1.000000 1.414214
B 1.732051 2.000000 2.236068
c 2.449490 2.645751 2.828427
求和與平均值
np.sum() 用於求序列的元素之和, np.mean() 用於求序列的平均值。其中,更牛逼的要數 .describe()。
frame = pd.DataFrame(np.arange(9).reshape(3, 3),
columns=["A", "B", "C"],
index=["a", "B", "c"])
print(np.sum(frame))
print()
print(np.mean(frame))
print()
print(frame.describe())
------------------------------
A 9
B 12
C 15
dtype: int64
A 3.0
B 4.0
C 5.0
dtype: float64
A B C
count 3.0 3.0 3.0
mean 3.0 4.0 5.0
std 3.0 3.0 3.0
min 0.0 1.0 2.0
25% 1.5 2.5 3.5
50% 3.0 4.0 5.0
75% 4.5 5.5 6.5
max 6.0 7.0 8.0
相關性
通過DataFrame.corr() 即可實現。
frame = pd.DataFrame(np.arange(25).reshape(5, 5),
columns = ["B", "C", "A", "D", "E"],
index=["a", "c", "b", "d", "e"])
print(frame.corr())
----------------------------
B C A D E
B 1.0 1.0 1.0 1.0 1.0
C 1.0 1.0 1.0 1.0 1.0
A 1.0 1.0 1.0 1.0 1.0
D 1.0 1.0 1.0 1.0 1.0
E 1.0 1.0 1.0 1.0 1.0
協方差
簡單的通過 .cov() 即可實現。(請不要再自己手寫函數了!
frame = pd.DataFrame(np.arange(25).reshape(5, 5),
columns = ["B", "C", "A", "D", "E"],
index=["a", "c", "b", "d", "e"])
print(frame.cov())
-------------------------------
B C A D E
B 62.5 62.5 62.5 62.5 62.5
C 62.5 62.5 62.5 62.5 62.5
A 62.5 62.5 62.5 62.5 62.5
D 62.5 62.5 62.5 62.5 62.5
E 62.5 62.5 62.5 62.5 62.5
排序和排次
通過函數 DataFrame.sort_index() 進行排序,其有兩個參數, ascending,用於指定按照降序(False),還是按照升序(True 且為默認值)排列; $axis,axis = 0時按照列進行排列(且爲默認值), axis = 1時按照行進行排列。
注意,這裏説的排列均是針對 Index 而非其中的 Value。
frame = pd.DataFrame(np.arange(25).reshape(5, 5),
columns = ["B", "C", "A", "D", "E"],
index=["a", "c", "b", "d", "e"])
print(frame)
print()
print(frame.sort_index(ascending=False))
print()
print(frame.sort_index(axis=1))
----------------------------------------------
B C A D E
a 0 1 2 3 4
c 5 6 7 8 9
b 10 11 12 13 14
d 15 16 17 18 19
e 20 21 22 23 24
B C A D E
e 20 21 22 23 24
d 15 16 17 18 19
c 5 6 7 8 9
b 10 11 12 13 14
a 0 1 2 3 4
A B C D E
a 2 0 1 3 4
c 7 5 6 8 9
b 12 10 11 13 14
d 17 15 16 18 19
e 22 20 21 23 24
當然,也可以基於你給定的列進行排序,如:sort_values(by = [“A”, “B”]),結果就不再進行演示了。
排位次操作
通過 DataFrame.rank() 以達到安排位次的目的(不過實際意義鄙人尚且不能理解。
frame = pd.DataFrame(np.arange(25).reshape(5, 5),
columns = ["B", "C", "A", "D", "E"],
index=["a", "c", "b", "d", "e"])
print(frame.rank())
--------------------------------------
B C A D E
a 1.0 1.0 1.0 1.0 1.0
c 2.0 2.0 2.0 2.0 2.0
b 3.0 3.0 3.0 3.0 3.0
d 4.0 4.0 4.0 4.0 4.0
e 5.0 5.0 5.0 5.0 5.0
NaN數據
NaN過濾
.dropna() 和 notnull() 篩選 即可以實現過濾掉 NaN 元素的目的。
在使用 dropna() 時需注意,可能會存在整行或整列均爲 NaN 的情況,則需要對 how 參數變量進行設置。 若 how = “any”,則只要有缺省值出現,就會刪除行或列,若 how = “all”,則只有所有值為 NaN時,才刪除。
frame = pd.DataFrame([[1, 2, 3], [np.nan, np.nan, np.nan], [4, 5, 6]]
,columns=["A", "B", "C"],
index=["a", "b", "c"])
print(frame)
print()
print(frame.dropna(how="all"))
--------------------------------------
A B C
a 1.0 2.0 3.0
b NaN NaN NaN
c 4.0 5.0 6.0
A B C
a 1.0 2.0 3.0
c 4.0 5.0 6.0
填充NaN
使用 .fillna(x)即可將序列裏的 NaN 變換為 x 值哦~
frame = pd.DataFrame([[1, 2, 3], [np.nan, np.nan, np.nan], [4, 5, 6]]
,columns=["A", "B", "C"],
index=["a", "b", "c"])
print(frame)
print()
print(frame.fillna(0))
------------------------------------
A B C
a 1.0 2.0 3.0
b NaN NaN NaN
c 4.0 5.0 6.0
A B C
a 1.0 2.0 3.0
b 0.0 0.0 0.0
c 4.0 5.0 6.0
層級順序的調整
(太複雜且不常用,略了吧。。。。