锚框的实现-非极大值抑制预测边界框
大家好,我是阿林。由于各种原因,阿林的组会告吹了。所以阿林的锚框的最后一期非极大值抑制预测边界框提前发布。
我们来回顾一下前两期的内容,并和第三期做一个总结吧。
第一期 我们通过提取出整张图的高宽,利用torch.meshgrid()制作[0,0.5,1.5,2]这样的网格。
再通过使用sizes,ratios确定每个像素点的锚框数量num_sizes + num_ratios - 1。减少计算量。
然后通过使用sizes,ratios确定每个锚框离像素点的高了。然后就可以在图片上画出每个像素点的锚框了。
第二期 我们定义了交并函数并实现了。交并函数是实现真实框应该分配给那里一个锚框。正式框
和锚框组成一个矩阵。
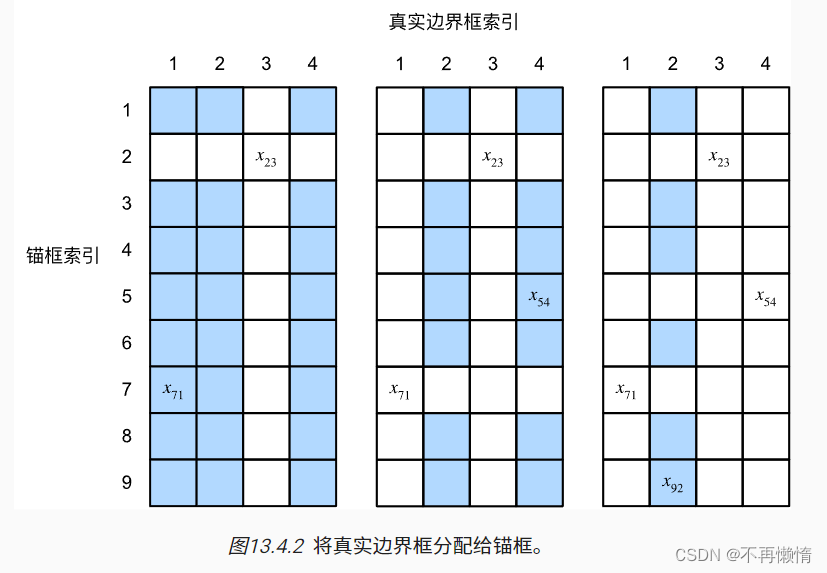
通过选出最大值然后,保存那个最大值的行数和列数相当于保存这个值。再将这个值的行和列上的数都取-1值相当与该真实框分配个了该锚框。没有分到真实框的锚框用最大的iou值与阈值相比较,如果大于阈值就会分配给真实框。
现在我们可以为每个锚框标记类别和偏移量了。 假设一个锚框A被分配了一个真实边界框B。 一方面,锚框A的类别将被标记为与B相同。 另一方面,锚框A的偏移量将根据B和A中心坐标的相对位置以及这两个框的相对大小进行标记。然后给出列子计算偏移量。
回顾了前两期的内容现在让我们学习这一期的内容吧。我们计算这一期就是将同一个类别的锚框相比较取一个iou最大的锚框。再以这个锚框为基础去除那些与这个锚框iou较大的锚框达到减少计算量的效果。
我们来看一下官方的正式描述。
当有许多锚框时,可能会输出许多相似的具有明显重叠的预测边界框,都围绕着同一目标。 为了简化输出,我们可以使用非极大值抑制(non-maximum suppression,NMS)合并属于同一目标的类似的预测边界框。
以下是非极大值抑制的工作原理。 对于一个预测边界框B,目标检测模型会计算每个类别的预测概率。 假设最大的预测概率为p,则该概率所对应的类别B即为预测的类别。 具体来说,我们将p称为预测边界框B的置信度(confidence)。 在同一张图像中,所有预测的非背景边界框都按置信度降序排序,以生成列表L。然后我们通过以下步骤操作排序列表L:
-
从L中选取置信度最高的预测边界框B1作为基准,然后将所有与B1的IoU超过预定阈值ϵ的非基准预测边界框从L中移除。这时,L保留了置信度最高的预测边界框,去除了与其太过相似的其他预测边界框。简而言之,那些具有非极大值置信度的边界框被抑制了。
-
从L中选取置信度第二高的预测边界框B2作为又一个基准,然后将所有与B2的IoU大于ϵ的非基准预测边界框从L中移除。
-
重复上述过程,直到L中的所有预测边界框都曾被用作基准。此时,L中任意一对预测边界框的IoU都小于阈值ϵ;因此,没有一对边界框过于相似。
-
输出列表L中的所有预测边界框。
以下nms函数按降序对置信度进行排序并返回其索引。
用了非极大值抑制后剩余的锚框在画出来就可以了。现在我们来介绍一下它各自的流程。
首先是通过偏移量和锚框预测出边界框的函数offset_inverse
#@save
# 该函数将锚框和偏移量预测作为输入.
def offset_inverse(anchors, offset_preds):
"""根据带有预测偏移量的锚框来预测边界框"""
# 从(左上,右下)转换到(中间点,宽度,高度)
anc = d2l.box_corner_to_center(anchors)
#这部分是通过预测偏移量去算出预测的锚框
print("anc[:, 2:]")
print(anc[:, 2:])
pred_bbox_xy = (offset_preds[:, :2] * anc[:, 2:] / 10) + anc[:, :2]
print(" pred_bbox_xy")
print( pred_bbox_xy)
pred_bbox_wh = torch.exp(offset_preds[:, 2:] / 5) * anc[:, 2:]
#
pred_bbox = torch.cat((pred_bbox_xy, pred_bbox_wh), axis=1)
# 从(中间,宽度,高度)转换到(左上,右下)
predicted_bbox = d2l.box_center_to_corner(pred_bbox)
return predicted_bbox这个是非极大值抑制函数
# 按降序对置信度进行排序并返回其索引
def nms(bboxs, scores, threshold):
# 取出分数从大到小排列的索引
order = torch.argsort(scores, dim=-1, descending=True)
print("orderargsort")
print(order)
# 这边的keep用于存放,NMS后剩余的方框(保存所有结果框的索引值)
keep = []
while order.numel() > 0:
if order.numel() == 1:
keep.append(order.item())
break
else:
# 置信度最高的索引
i = order[0].item()
# keep保留的是索引值,不是具体的分数。
keep.append(i)
# 计算最大得分的bboxs[i]与其余各框的IOU
iou = box_iou(bboxs[i, :].reshape(-1, 4),
bboxs[order[1:], :].reshape(-1, 4)).reshape(-1)
print("iou")
print(iou)
# 保留iou小于阈值的剩余bboxs,iou小表示两个box交集少,可能是另一个物体的框,故需要保留
idx = torch.nonzero((iou <= threshold)).reshape(-1) # 返回非零元素的索引
print("idx")
print(idx)
# 待处理boundingbox的个数为0时,结束循环
if idx.numel() == 0:
break
# 把留下来框在进行NMS操作
# 这边留下的框是去除当前操作的框,和当前操作的框重叠度大于thresh的框
# 每一次都会先去除当前操作框(n个框计算n-1个IOU值),所以索引的列表就会向前移动移位,要还原就+1,向后移动一位
print("order1")
print(order)
order = order[idx + 1] #iou小于阈值的框
print("order2")
print(order)
return torch.tensor(keep,device=bboxs.device)
- 将非极大值抑制应用于预测边界框
# 将非极大值抑制应用于预测边界框
def multibox_detection(cls_probs, offset_preds, anchors, nms_threshold=0.5,
pos_threshold=0.0099):
"""使用非极大值抑制来预测边界框。"""
device, batch_size = cls_probs.device, cls_probs.shape[0]
anchors = anchors.squeeze(0)
print("anchors1")
print(anchors)
# 保存最终的输出
out = []
for i in range(batch_size):
# 预测概率和预测的偏移量
cls_prob, offset_pred = cls_probs[i], offset_preds[i].reshape(-1, 4)
# 非背景的概率及其类别索引
conf, class_id = torch.max(cls_prob[1:], 0)
print("conf1")
print(conf)
print("class_id1")
print(class_id)
# 预测的边界框坐标
print("anchors2")
print(anchors)
predicted_bb = offset_inverse(anchors, offset_pred)
print("predicted_bb")
print(predicted_bb)
# 对置信度进行排序并返回其索引[0,3,1,2]
all_id_sorted = torch.argsort(conf, dim=-1, descending=True)
# 非极大值抑制结果 [0,3]
keep = nms(predicted_bb, conf, nms_threshold)
# 找到所有的 non_keep 索引,并将类设置为背景
non_keep = []
for i in range(all_id_sorted.numel()):
res = all_id_sorted[i] in keep
if not res:
non_keep.append(all_id_sorted[i].item())
# [1,2]
non_keep = torch.tensor(non_keep)
# 将类设置为背景-1
class_id[non_keep] = -1
# 对应的类别标签
class_id = class_id[all_id_sorted]
# 排序
conf, predicted_bb = conf[all_id_sorted], predicted_bb[all_id_sorted]
print("conf2")
print(conf)
print("class_id2")
print(class_id)
# `pos_threshold` 是一个用于非背景预测的阈值
below_min_idx = (conf < pos_threshold)
class_id[below_min_idx] = -1
conf[below_min_idx] = 1 - conf[below_min_idx]
pred_info = torch.cat(
(class_id.unsqueeze(1), conf.unsqueeze(1), predicted_bb), dim=1)
print("pred_info")
print(pred_info)
out.append(pred_info)
return torch.stack(out)
测试
# 构造4个锚框
anchors = torch.tensor([[0.1, 0.08, 0.52, 0.92], [0.08, 0.2, 0.56, 0.95],
[0.15, 0.3, 0.62, 0.91], [0.55, 0.2, 0.9, 0.88]])
# 假设预测的偏移量都是零
offset_preds = torch.tensor([0] * anchors.numel())
# 预测概率
cls_probs = torch.tensor([[0] * 4, # 背景的预测概率
[0.9, 0.8, 0.7, 0.1], # 狗的预测概率
[0.1, 0.2, 0.3, 0.9]]) # 猫的预测概率
# 为输入增加样本维度
output = multibox_detection(cls_probs.unsqueeze(dim=0),
offset_preds.unsqueeze(dim=0),
anchors.unsqueeze(dim=0), nms_threshold=0.5)
print(output)
这是锚框的实现的最后的一期了。下一期阿林我可能会学学习SSD物体检测算法。那我们下一期见把。