【PaddleSpeech-学习笔记】第二章:声音分类
【PaddleSpeech-学习笔记】第二章:声音分类
- 知识的回顾
-
- 依赖库安装:Paddlespeech & Paddleaudio
- 视觉图谱反映数字音频信号
-
- paddlespeech库中的函数功能
- 音频特征提取(重要)
-
- 离散傅里叶变换(DFT)
- LogFBank
- 声音分类方法
-
- 传统机器学习方法
- 深度学习方法
- 预训练+微调(Pretrain+Finetune)
- 实践:环境声音分类
-
- 数据集准备
-
- 数据集初始化
- 特征提取
- 模型
-
- 选取预训练模型
- 构建分类模型
- Finefune(微调)
-
- 创建DataLoader
- 定义优化器和Loss
- 启动模型训练
- 音频预测
由于第一章的内容主要是深度学习背景介绍-服务器部署命令-课程目标人群等介绍,所以直接从第二章节开始做记录
知识的回顾
想要完成一个任务,首先需要明确这个任务所需要用到的基本技巧还有底层原理。
以AS(AudiosSet)为例,最基本的内容正是我们初中物理学的知识,这里直接应用维基百科的定义:
声音总可以被分解为不同频率不同强度正弦波的叠加。这种变换(或分解)的过程,称为傅立叶变换。因此,一般的声音总是包含一定的频率范围。
其中最基本的声音特征就是:频率和音色。
声音的产生是由发声音物体的震动产生的。
声音又可以分为:基音和泛音。
基音由发声物体的主体振动时发出;泛音由其余各部分的复合振动产生。
基音可以相同的频率和振幅控制。但是泛音决定了物体的“音色”,由此可以分辨出不同的人和物发出的声音。
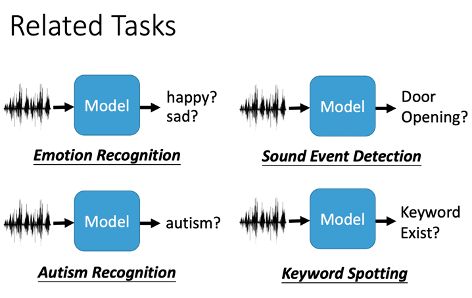
通过音色可以进一步细分为:
- 副语言识别:说话人识别,情绪识别,性别分类
- 音乐识别:音乐流派分类
- 场景识别:环境声音分类
- 声音时间检测:各个环境中的声音时间和起始时间检测
依赖库安装:Paddlespeech & Paddleaudio
#飞桨语音库安装
!pip install paddlespeech==1.2.0
!pip install paddleaudio==1.0.1
顺便记录一个小技巧,在jupyter下查看函数的方法。 开启一个新的代码框,在函数后面加上一个?,再直接运行就可以了
例如:IPython?

视觉图谱反映数字音频信号
课程在这一部分展示了下载案例,用来展示音频文件的波形,直观地了解数字音频文件所包含的内容信息。
这里我选择自己手动上传一个wav格式的文件作为音频。
之后会出现一个对话框,直接将音频拖入其中上传即可。
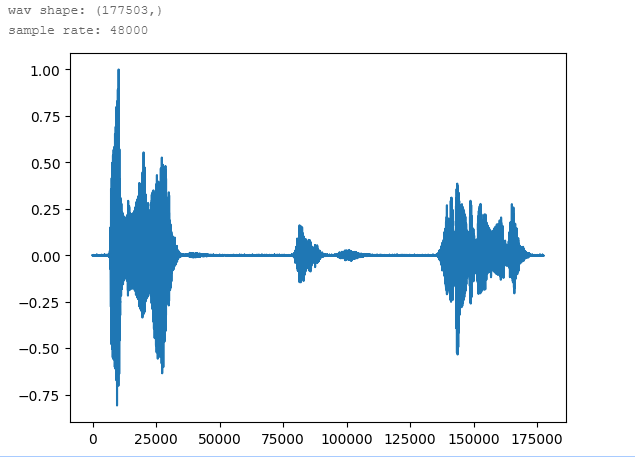
使用Ipython库对文件进行音频的解析展示,运行后可以直接测试一下是否可以使用。
#读取上传的名为'win.wav'格式的文件
Ipython.display.Audio('./win.wav')
使用paddleaudio库中的load函数
分别打印出波形和采样评率
from paddleaudio import load
data, sr = load(file='./win.wav', mono=True, dtype='float32') # 单通道,float32音频样本点
print('wav shape: {}'.format(data.shape))
print('sample rate: {}'.format(sr))
# 展示音频波形
plt.figure()
plt.plot(data)
plt.show()
paddlespeech库中的函数功能
输入!paddlespeech help并运行,查看相关命令和功能。
!paddlespeech help
输出:

可以看到cls命令的功能是将音色分类
这里使用!paddlespeech cls --input ./win.wav尝试将音色进行分类。我们原本上传的文件是一段人声的配音,分类结果显示为:
Speech 0.8599252104759216
在大分类上的结果还是不错的。
音频特征提取(重要)
这一部分是我认为比较重要的地方。
特征提取的好坏决定后面一系列任务的结果。
要提取特征,首先要了解什么是音频信号的特征。
离散傅里叶变换(DFT)
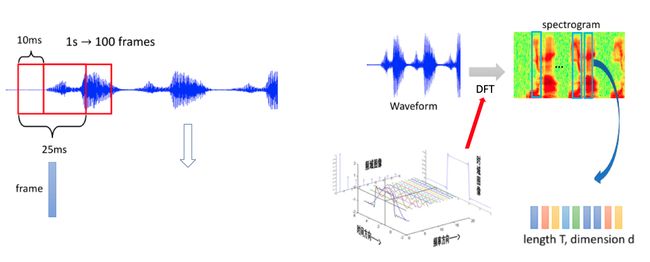
参考上面我们使用Matplotlib提取出来的音频信号频谱图,对一段音频的信号而言,有几个非常重要的名词在后面的特征提取中会十分重要。
- 分帧:每一帧含有一定长度的信号数据,一般使用25ms
- 移帧:帧与帧之间的移动距离称为移帧,一般使用10ms
- 频率特征:用傅里叶变换来分析得到。
- 语谱图(Spectrogram):每一帧频率信息拼接后得到的频率特征
使用paddle的paddle.signal.stft内置库和python的matplotlib库展示音频信号的频谱图
import paddle
import numpy as np
#file读取文件;sr加载波形的采样率;mono单声道返回波形;dtype波形的数据类型。默认为“float32”。
data, sr = load(file='./win.wav', sr = 32000, mono = True, dtype = 'float32')
#paddle.to_tensor可以将数据格式归一化为满足“paddle”的张量形式
x = paddle.to_tensor(data)
#n_fft执行傅里叶变换的输入样本个数;win_length相邻滑窗之间的步数,hop_length滑窗的大小
n_fft = 1024
win_length = 1024
hop_length = 320
#[D, T],使用短时傅里叶变换的方式对音频数据进行特征采样
spectrogram = paddle,signal.stft(x, n_fft = n_fft, win_length = win_length, hop_length = 512, onesided = True)
print('spectrogram.shape:{}'.format(spectrogram.shape))
print('spectrogram.dtype:{}'.format(spectrogram.dtype))
spec = np.log(np.abs(spectrogram.numpy())**2)
plt.figure()
plt.title("Log Power Spectrogram")
plt.imshow(spec[:100, :], origin = 'lower')
plt.show()
上面用到的两个重要函数:
load:从磁盘加载音频文件。此函数使用音频后端从磁盘加载音频。paddle.signal.stft:使用短时傅里叶变换的方法计算短重叠滑窗下的离散傅里叶变换
LogFBank
研究表明,人类对声音的感知是非线性的,随着声音频率的增加,人对更高频率的声音的区分度会不断下降。
例如同样是500Hz的频率,一般人可以轻松分辨出声音中500Hz和1000Hz之间的差异,但是很难分辨出10,000Hz和10,500Hz之间的差异。
因此,学者提出了梅尔频率,在该频率计量方式下,人耳对相同数值的频率变化的感知程度是一样的。
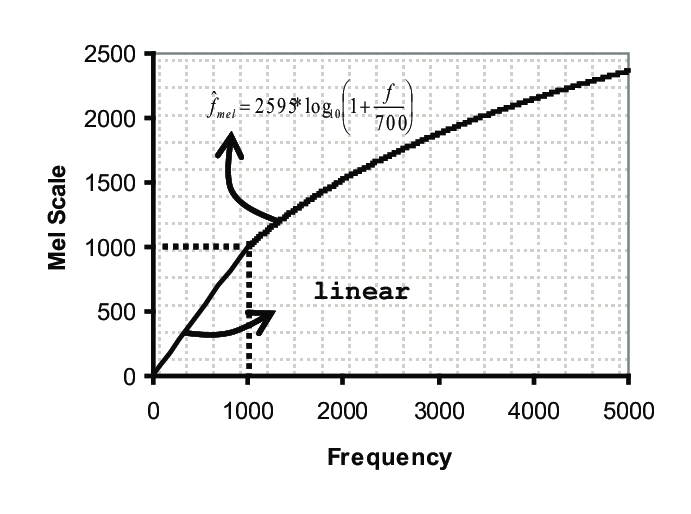
关于梅尔频率的计算,其会对原始频率的低频部分进行较多的采样,从而对应更多的频率,而对高频的声音进行较少的采样,从而对应较少的频率。使得人耳对梅尔频率的低频和高频的区分性一致。

Mel Fbank 的计算过程如下,而我们一般都是使用LogFBank作为识别特征:
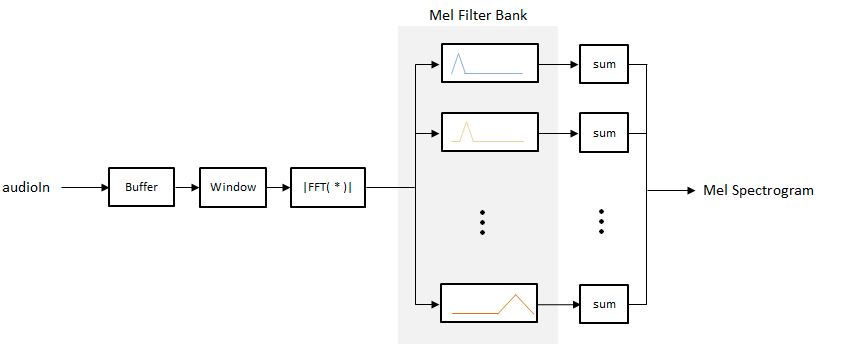
下面采用paddleaudio.features.LogMelSpectrogram演示如何提取示例音频的LogFBank:
#调库
form paddleaudio.features import LogmelSpectrogram
f_min = 50.0
f_max = 14000.0
feature_extractor = LogMelSpectrogram(
sr = sr # 音频文件采样率
n_fft = n_fft # FFT快速傅里叶变换样本点个数
hop_length = hop_length # 音频帧之间的间隔
win_length = win_length # 窗函数的长度
window = 'hann' # 窗函数种类
f_min = f_min
f_max = f_max
n_mels = 64 # 梅尔刻度数量
)
x = paddle.to_tensor(data).unsqueeze(0) #[B,L]
log_fbank = feature_extractor(x) # [B, D, T]
log_fbank = log_fbank.squeeze(0)# [D, T]
print('log_fbank.shape:{}'.format(log_fbank.shape))
plt.figure()
plt.imshow(log_fbank.numpy(), origin = 'lower')
plt.show()
声音分类方法
这里介绍了三种主要的方法:传统机器学习方法、深度学习方法、Pretrain+Finetune(预训练+微调)
传统机器学习方法
在传统的声音和信号的研究领域中,声音特征是一类包含丰富先验知识的手工特征,如频谱图、梅尔频谱和梅尔频谱倒谱系数等。
因此在一些分类的应用上,可以采用传统的机器学习方法例如决策树、SVM和随机森林方法。
一个典型的应用案例是:男声和女声的分类

深度学习方法
传统机器学习方法可以捕捉声音特征的差异(例如男声和女声的声音在高音上往往差异较大)并实现分类任务。
而深度学习方法则可以突破特征的限制,更灵活的组网方式和更深的网络层次,可以更好地提取声音的高层特征,从而获得更好的分类指标。
随着深度学习算法的快速发展和在分类任务上的优异表现,当下流行的声音分类模型无一不是采用深度学习网络搭建而成的,如AudioCLIP[1]、PANNs[2]和Audio Spectrogram Transformer[3]等
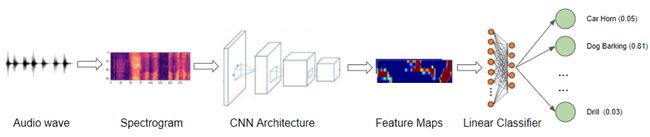
预训练+微调(Pretrain+Finetune)
在声音分类和声音检测的场景中(如环境声音分类、情绪识别和音乐流派分类等)由于可获取的数据集有限,且语音数据标注的成本高,用户可以收集到的数据量往往较小,这种数据量稀少的情况对于模型训练时非常不利的。
预训练模型能够减少领域数据的需求量,并达到较高的识别准确率。在CV和NLP领域中,有诸如MobileNet、VGG19、YOLO、BERT和ERNIE等开源的预训练模型,在图像检测、图像分类、文本分类和文本生成等各自领域内的任务中,使用预训练模型在下游任务中的数据集上进行finetune,往往可以更快更容易获得较好的效果和指标。
相较于CV领域的ImageNet数据集,谷歌在2017年开放了一个大规模的应聘数据集AudioSet[4],它是目前最大的用于音频分类任务的数据集。该数据集包含了632类的音频类别以及2084320条人工标记的每段10秒长的声音剪辑片段(包括527个标签),数据总时长为5800小时。

PANNs是基于AudioSet数据集训练的声音分类/识别的模型,其中PANNs-CNN14在测试集上取得了较好的效果:mAP为0431,AUC为0.973,d-prime为2.732,经过预训练后,该模型可以用于提取音频的embbedding,适合用于声音分类和声音检测等下游任务。本示例将使用PANNs的预训练模型Finetune完成声音分类的任务。

下面的内容选自PANNs中的预训练模型cnn14作为backbone,用于提取声音的深层特征,SoundClassifer创建下游的分类网络,实现对输入音频的分类。

实践:环境声音分类
数据集准备
此课程选取了ESC-50: Dataset for Environmental Sound Classification[5]数据集作为示例。
这是一个包含了2000个带标签的环境声音样本,音频样本采样率为44,100Hz的单通道音频文件,所有样本根据标签被划分为50个类别,每个类别有40个样本。
音频样本可分为5个主要类别
- 动物声音(Animals)
- 自然界产生的声音和水声(Natural soundscapes & water sounds)
- 人类发出的非语言声音(Human, non-speech sounds)
- 室内声音(Interior/domestic sounds)
- 室外声音和一般噪声(Exterior/urban noises)。
ESC-50数据集中所提供的CSV文件包含的部分信息如下:
filename,fold,target,category,esc10,src_file,take
1-100038-A-14.wav,1,14,chirping_birds,False,100038,A
1-100210-A-36.wav,1,36,vacuum_cleaner,False,100210,A
1-101296-A-19.wav,1,19,thunderstorm,False,101296,A
…
- filename: 音频文件名字。
- fold: 数据集自身提供的N-Fold验证信息,用于切分训练集和验证集。
- target: 标签数值。
- category: 标签文本信息。
- esc10: 文件是否为ESC-10的数据集子集。
- src_file: 原始音频文件前缀。
- take: 原始文件的截取段落信息。
在此声音分类的任务中,我们将target作为训练过程的分类标签。
数据集初始化
from paddleaudio.datasets import ESC50
train_ds = ESC50(mode='train', sample_rate = sr)
dev_ds = ESC50(mode='dev', sample_rate = sr)
特征提取
通过下列代码,用paddleaudio.features.LogMelSpectrogram初始化一个音频特征提取器,在训练过程中实时提取音频的LogFBank特征,其中主要的参数如下(参数注解同上梅尔图谱函数注解):
feature_extractor = LogMelSpectrogram(
sr=sr,
n_fft=n_fft,
hop_length=hop_length,
win_length=win_length,
window='hann',
f_min=f_min,
f_max=f_max,
n_mels=64)
模型
选取预训练模型
选取cnn14作为backbone,用于提取音频的特征
#使用paddle库函数中现有的骨架结构
from paddlespeech.cls.models import cnn14
backbone = cnn14(pretrained = True, extract_embedding = True)
构建分类模型
SoundClassifer接收cnn14作为backbone模型,并穿件下游的分类网络:
import paddle.nn as nn
class SoundClassifer(nn.Layer):
def __init__(self, backbone, num_class, dropout = 0.1):
super().__init__()
self.backbone = backbone
self.dropout = nn.Dropout(dropout)
self.fc = nn.Linear(self.backbone.emb_size, num_class)
def forward(self, x):
x = x.unsqueeze(1)
x = self.backbone(x)
x = self.dropout(x)
logits = self.fc(x)
return logits
model = SoundClassifer(backbone, num_class = len(ESC50.label_list))
Finefune(微调)
创建DataLoader
batch_size = 16
train_loader = paddle.io.DataLoader(train_ds, batch_size = batch_size, shuffle = True)
dev_loader = paddle.io.DataLoader(dev_ds, batch_size = batch_size)
定义优化器和Loss
optimizer = paddle.optimizer.Adam(learning_rate = 1e-4, parameters = model.parameters())
criterion = paddle.nn.loss.CrossEntropyLoss()
启动模型训练
#库函数调用
from paddleaudio.utils import logger
epochs = 20
steps_per_epoch = len(train_loader)
log_freq = 10
eval_freq = 10
for epoch in range(i, epochs + 1):
model.train()
avg_loss = 0
num_corrects = 0
num_samples = 0
for batch_idx, batch in enumerate(train_loader):
waveforms, labels = batch
feats = feature_extractor(waveforms)
feats = paddle.transpose(feats, [0, 2, 1]) #[B, N, T] ->[B, T, N]
logits = model(feats)
loss = criterion(logits, labels)
loss.backward()
optimizer.step()
if isinstance(optimizer._learning_rate,
paddle.optimizer.lr.LRScheduler):
optimizer._learning_rate.step()
optimizer.clear_grad()
# Calculate loss
avg_loss += loss.numpy([0])
# Calculate metrics
preds = paddle.argmax(logits, axis = 1)
num_corrects += (preds == labels).numpy().sum()
num_samples += feats.shape[0]
if (batch_idx + 1) % log_freq == 0:
lr = optimizer.get_lr()
avg_loss /= log_freq
avg_acc = num_corrects / num_samples
print_msg = 'Epoch={}/{}, Step{}/{}'.format(epoch, epochs, batch_idx + 1, step_per_epoch)
print_msg += 'loss={:.4f}'.format(avg_loss)
print_msg += 'acc={:.4f}'.format(avg_acc)
print_msg += 'lr={:.6f}'.format(lr)
logger.train(print_msg)
avg_loss = 0
num_corrects = 0
num_samples = 0
if epoch % eval_freq == 0 and batch_idx + 1 == steps_per_epoch:
model.eval()
num_corrects = 0
num_samples = 0
with logger.processing('Evaluation on validation dataset'):
for batch_idx, batch in enumerate(dev_loader):
waveforms, labels = batch
feats = feature_extractor(waveforms)
feats = paddle.transpose(feats, [0, 2, 1])
logits = model(feats)
preds = paddle.argmax(logits, axis = 1)
num_corrects += (preds == labels).numpy().sum()
num_samples += feats.shape[0]
print_msg = '[Evaluation result]'
print_msg = ' dev_acc={:.4f}'.format(num_corrects / num_samples)
logger.eval(print_msg)
训练过程与结果不做展示。
音频预测
执行预测,获取Top k分类结果:
top_k = 5 #这里只取概率最大的前五类结果概率
waveform, sr = load(wav_file, sr = sr)
feature_extractor = LogMelSpectrogram(
sr = sr,
n_ff = n_ff,
hop_length = hop_length,
win_length = win_length,
window = 'hann',
f_min = f_min,
f_max = f_max,
n_mels = 64
)
feats = feature_extractor(paddle.to_tensor(paddle.to_tensor(waveform).unsqueeze(0)))
feats = paddle.transpose(feats, [0, 2, 1]) # [B, N, T] ->[B, T, N]
logits = model(feats)
probs = nn.functional.softmax(logits, axis = 1).numpy()
sorted_indices = probs[0].argsort()
msg = f'[{wav_file}]\n'
for idx in sorted_indices[-1:-top_k-1:-1]:
msg += f'{ESC50.label_list[idx]}: {probs[0][idx]:.5f}\n'
print{msg}
结果不太准确,可能因为分类的标签主要是自然界的声音或者白噪音等等