十二月组队学习之——目标检测Task01:两个年轻人-目标检测基础和VOC数据集
有幸参加了DataWhale举办的目标检测组队学习。收获颇多。
每天记录一些自己之前的知识盲点,需经常温习。
一、目标检测基本概念
1、什么是目标检测
众所周知,人工智能AI在计算机视觉中的应用主要分为三大方向:图像分类、目标检测和图像分割。其中,图像分割又可以细分为语义分割和实例分割。
图像分类:只需要判断输入的图像中是否包含感兴趣物体。
目标检测:需要在识别出图片中目标类别的基础上,还要精确定位到目标的具体位置,并用外接矩形框(也叫bounding box)标出。即目标检测 = 图像分类 + 目标定位。
图像分割:输入与目标检测类似,但是要判断出每一个像素属于哪一个类别,属于像素级的分类。其中,实例分割还需要在同类别像素中,属于不同物体的像素进一步区分出来,比仅仅依照不同类别像素进行语义分割的任务更为复杂。
话不多说,上图(图1)。
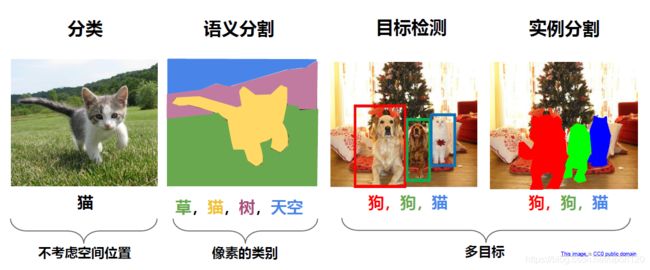
图1 三大计算机视觉任务对比
关于图像分类和目标检测的对比(见图2):
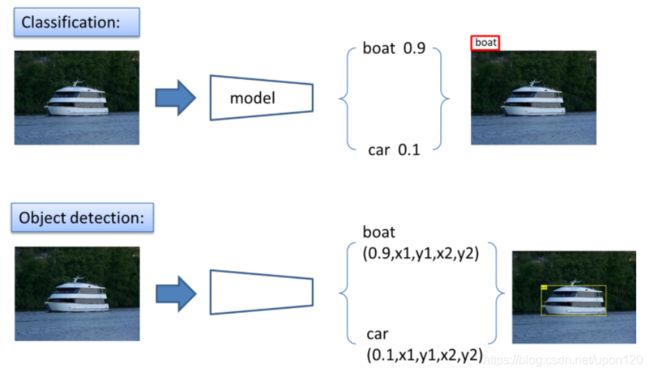
图2 图像分类和目标检测的对比
图2上半部分为图像分类,下半部分为目标检测。人工智能在计算机视觉中的应用流程可以概括为feature extraction + classification(or other algorithms)。卷积神经网络(CNN)的作用主要就是进行特征提取(feature extraction)。对于图像分类问题,最后需要一个分类器(二分类可以选择sigmoid或者softmax,多分类通常选择softmax)进行每个类别的概率的计算,选择概率最大的作为预测的类别。那么对于目标检测问题,除了得到图像分类的概率之外,还需要得到其具体的坐标位置。
2、目标检测的思路
众所周知,一张图片中包含的信息量是非常巨大的,有背景、目标物、非目标物等等。我们重点关注的是目标物,具体为目标物的类别及其坐标位置。
经研究,似乎CNN并不善于直接预测坐标信息。并且一幅图像中可能出现的物体个数也是不定的,模型如何构建也比较棘手。
因此,人们就想,如果知道了图中某个位置存在物体,再将对应的局部区域送入到分类网络中去进行判别,那我不就可以知道图像中每个物体的位置和类别了吗?
但是,怎么样才能知道每个物体的位置呢?显然我们是没办法知道的,但是我们可以去猜啊!所谓猜,其实就是通过滑窗的方式,罗列图中各种可能的区域,一个个去试,分别送入到分类网络进行分类得到其类别,同时我们会对当前的边界框进行微调,这样对于图像中每个区域都能得到(class,x1,y1,x2,y2)五个属性,汇总后最终就得到了图中物体的类别和坐标信息。
总结一下我们的这种方案思路:先确立众多候选框,再对候选框进行分类和微调。如图3所示。
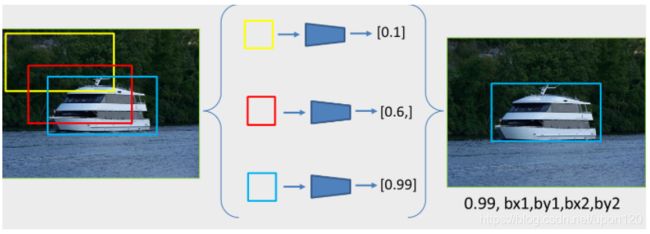
图3 从分类角度去看目标检测
图3展示了一个通过遍历各个区域,然后逐个分类去完成目标检测任务的过程示例。在待识别图上预设一个框,然后逐像素遍历,就能得到大量候选框(这里仅为示意图,图上只展示了3个框用于说明问题,具体数量由图像大小和预设框大小决定),每个框送入到分类网络分类都有一个得分(代表当前框中有一个船的置信度),那么得分最高的就代表识别的最准确的框,其位置就是最终要检测的目标的位置。
以上就是最初的基于深度学习的目标检测问题解决思路,RCNN,YOLO,SSD等众多经典网络模型都是沿着这个思路优化发展的。
最终,研究着们将目标检测算法根据计算步骤次数分为两阶段目标检测和单阶段目标检测。
两阶段目标检测算法先通过选择性搜索(Selective Search)的方法生成可能包含物体的候选区域(Region Proposal),再对候选区域做进一步分类和校准。代表作:R-CNN、SPPNet、Fast R-CNN和Faster R-CNN等;而单阶段目标检测算法直接给出最终的结果(初筛+回归),没有显式地生成候选区域的步骤。代表作:SSD和YOLO等。
3、目标框定义方式
关于目标的坐标位置,有两种表示方法(详见图4):
1)矩形框左上角的坐标点(x1, y1)和右下角的坐标点(x2, y2);
2)矩形框的中心坐标点(xc, yc)和矩形框的宽、高(width, height)。
由于在计算机视觉任务中,默认左上角坐标点为原点(0, 0),X轴的正方向是水平朝右,Y轴的正方向是垂直朝下(注意!这点与二维笛卡尔坐标系不同!)。故在第一种表示方法中,左上角的坐标点即为该矩形框所有坐标点中x分量和y分量数值同时达到最小值的点,右下角的坐标点即为该矩形框所有坐标点中x分量和y分量数值同时达到最大值的点。
故左上角的坐标点为整个矩形框的最小值点,右下角的坐标点为整个矩形框的最大值点。此二最值点可以唯一确定一个矩形框的位置。

图4 目标框定义方式
两种坐标表示的相互转换代码如下:
def xy_to_cxcy(xy):
"""
Convert bounding boxes from boundary coordinates (x_min, y_min, x_max, y_max) to center-size coordinates (c_x, c_y, w, h).
:param xy: bounding boxes in boundary coordinates, a tensor of size (n_boxes, 4)
:return: bounding boxes in center-size coordinates, a tensor of size (n_boxes, 4)
"""
return torch.cat([(xy[:, 2:] + xy[:, :2]) / 2, # c_x, c_y
xy[:, 2:] - xy[:, :2]], 1) # w, h
def cxcy_to_xy(cxcy):
"""
Convert bounding boxes from center-size coordinates (c_x, c_y, w, h) to boundary coordinates (x_min, y_min, x_max, y_max).
:param cxcy: bounding boxes in center-size coordinates, a tensor of size (n_boxes, 4)
:return: bounding boxes in boundary coordinates, a tensor of size (n_boxes, 4)
"""
return torch.cat([cxcy[:, :2] - (cxcy[:, 2:] / 2), # x_min, y_min
cxcy[:, :2] + (cxcy[:, 2:] / 2)], 1) # x_max, y_max4、交并比(IOU:Intersection Over Union)
在目标检测任务中,关于IOU的计算贯穿整个模型的训练测试和评价过程,是非常非常重要的一个概念,其目的是用来衡量两个目标框的重叠程度。
IoU的全称是交并比(Intersection Over Union),表示两个目标框的交集占其并集的比例。如图5所示。
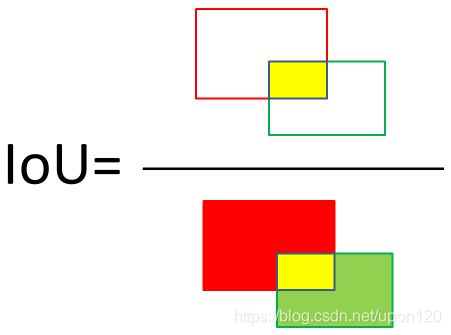
图5 IOU计算示意图
图中可以看到,分子中黄色区域为红bbox和绿bbox的交集,分母中黄+红+绿区域为红bbox和绿bbox的并集,两者之比即为IOU。
那么具体怎么去计算呢?这里给出计算流程的简述:
1)首先获取两个框的坐标,红框坐标: 左上(red_x1, red_y1), 右下(red_x2, red_y2),绿框坐标: 左上(green_x1, green_y1),右下(green_x2, green_y2) ;
2)计算两个框左上点的坐标最大值:(max(red_x1, green_x1), max(red_y1, green_y1)), 和右下点坐标最小值:(min(red_x2, green_x2), min(red_y2, green_y2)) ;
3)利用2算出的信息计算黄框面积:yellow_area ;
4)计算红绿框的面积:red_area 和 green_area ;
5)iou = yellow_area / (red_area + green_area - yellow_area)。
IOU代码如下(考虑到可读性和鲁棒性,采用了如下代码):
```
1、相交方式假设
假设两框相交方式如下:
——————————————————————————————————————————————————> x轴
|-------------------
|| |
|| bbox1 |
|| |
|| bbox2:(x1,y1) -----------
|| | | |
|| | | |
|| | | |
|| | | |
|| | | |
|| | | |
|| | | |
|| | | |
|| | | |
|| | | |
|----------bbox1:(x2,y2) |
| | |
| | |
| | |
| | bbox2 |
| | |
| -------------------
|
\|/
\/
y轴
2、目标检测评估指标IOU计算公式
两框交集部分长方形的面积
IOU = ——————————————————————————————————————————
框1面积+框2面积-两框交集部分长方形的面积
```
def get_iou(bb1, bb2):
assert bb1['x1'] < bb1['x2'] # assert : 如果bb1['x1'] < bb1['x2'],继续向下执行
assert bb1['y1'] < bb1['y2']
assert bb2['x1'] < bb2['x2']
assert bb2['y1'] < bb2['y2']
x_left = max(bb1['x1'], bb2['x1']) # 左上角x坐标(若图所示,则为bbox2的x1):如果框2左上角x坐标大于框1左上角x坐标,则选择框2的左上角x坐标
y_top = max(bb1['y1'], bb2['y1']) # 左上角y坐标(bbox2的y1),同上
x_right = min(bb1['x2'], bb2['x2']) # 右下角x坐标(bbox1的x2)
y_bottom = min(bb1['y2'], bb2['y2']) # 右下角y坐标(bbox1的y2)
if x_right < x_left or y_bottom < y_top: # 两框没有交集
return 0.0
intersection_area = (x_right - x_left) * (y_bottom - y_top)
bb1_area = (bb1['x2'] - bb1['x1']) * (bb1['y2'] - bb1['y1']) # 框1的面积
bb2_area = (bb2['x2'] - bb2['x1']) * (bb2['y2'] - bb2['y1']) # 框2的面积
iou = intersection_area / float(bb1_area + bb2_area - intersection_area) # IOU计算公式
assert iou >= 0.0
assert iou <= 1.0
return iou对于目标检测的定位任务来说,由于会涉及到不同bbox的坐标位置,故需要不停地进行判断。此时很容易出错。故需要对代码进行assert或者try...except...等关键字的封装,目的是提高代码的鲁棒性。该思想在大型目标检测工程落地过程中会经常使用。
二、VOC数据集
1、VOC数据集简介
计算机视觉领域含有众多大型的开源数据集。如ImageNet、COCO、VOC、TuSimple、CULane、KITTI等。
VOC数据集全称是PASCAL VOC,具体为Pattern Analysis, Statical Modeling and Computational Learning VOC,是目标检测领域最常用的标准数据集之一,几乎所有检测方向的论文,如faster_rcnn、yolo、SSD等都会给出其在VOC数据集上训练并评测的效果。因此我们我们的教程也基于VOC来开展实验,具体地,我们使用VOC2007和VOC2012这两个最流行的版本作为训练和测试的数据。
数据集类别
VOC数据集在类别上可以分为4大类,20小类,其类别信息如图6所示。
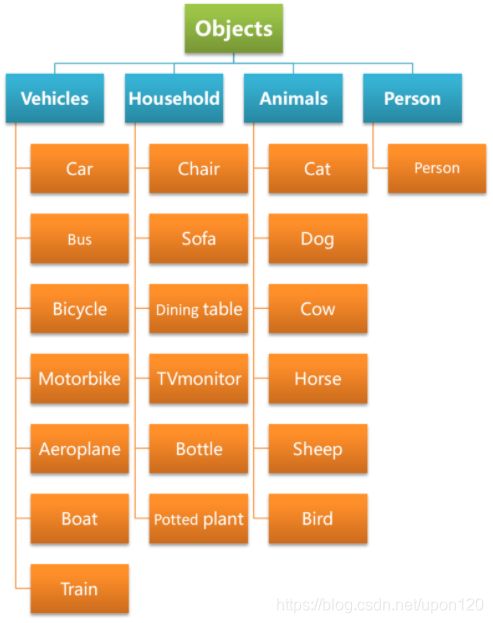
图6 VOC数据集目标类别划分
数据集量级
VOC数量集图像和目标数量的基本信息如下图7所示:

图7 VOC数据集数据量级对比
其中,Images表示图片数量,Objects表示目标数量。
数据集说明
将下载得到的压缩包解压,可以得到如图8所示的一系列文件夹,由于VOC数据集不仅被拿来做目标检测,也可以拿来做分割等任务,因此除了目标检测所需的文件之外,还包含分割任务所需的文件,比如SegmentationClass,SegmentationObject,这里,我们主要对目标检测任务涉及到的文件进行介绍。
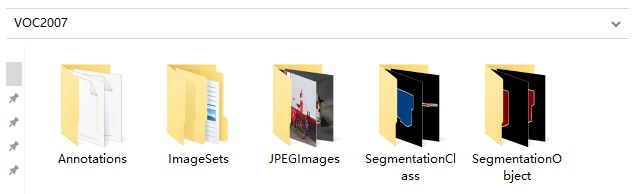
图8 VOC压缩包解压所得文件夹示例
1.JPEGImages
这个文件夹中存放所有的图片,包括训练验证测试用到的所有图片。
2.ImageSets
这个文件夹中包含三个子文件夹,Layout、Main、Segmentation
-
Layout文件夹中存放的是train,valid,test和train+valid数据集的文件名
-
Segmentation文件夹中存放的是分割所用train,valid,test和train+valid数据集的文件名
-
Main文件夹中存放的是各个类别所在图片的文件名,比如cow_val,表示valid数据集中,包含有cow类别目标的图片名称。
3.Annotations
Annotation文件夹中存放着每张图片相关的标注信息,以xml格式的文件存储,可以通过记事本或者浏览器打开,我们以000001.jpg这张图片为例说明标注文件中各个属性的含义,见图9。

图9 VOC数据集000001.jpg图片(左)和标注信息(右)
猛一看去,内容又多又复杂,其实仔细研究一下,只有红框区域内的内容是我们真正需要关注的。
1)filename:图片名称
2)size:图片宽高,
3)depth表示图片通道数
4)object:表示目标,包含下面两部分内容。
首先是目标类别name为dog。pose表示目标姿势为left,truncated表示是否是一个被截断的目标,1表示是,0表示不是,在这个例子中,只露出狗头部分,所以truncated为1。difficult为0表示此目标不是一个难以识别的目标。
然后就是目标的bbox信息,可以看到,这里是以[xmin,ymin,xmax,ymax]格式进行标注的,分别表示dog目标的左上角和右下角坐标。
5)一张图片中有多少需要识别的目标,其xml文件中就有多少个object。上面的例子中有两个object,分别对应人和狗。
2、VOC数据集DataLoader的构建
1. 数据集准备
根据上面的介绍可以看出,VOC数据集的存储格式还是比较复杂的,为了后面训练中的读取代码更加简洁,这里我们准备了一个预处理脚本create_data_lists.py。
该脚本的作用是进行一系列的数据准备工作,主要是提前将记录标注信息的xml文件(Annotations)进行解析,并将信息整理到json文件之中,这样在运行训练脚本时,只需简单的从json文件中读取已经按想要的格式存储好的标签信息即可。
注: 这样的预处理并不是必须的,和算法或数据集本身均无关系,只是取决于开发者的代码习惯,不同检测框架的处理方法也是不一致的。
可以看到,create_data_lists.py脚本仅有几行代码,其内部调用了utils.py中的create_data_lists方法:
"""python
create_data_lists
"""
from utils import create_data_lists
if __name__ == '__main__':
# voc07_path,voc12_path为我们训练测试所需要用到的数据集,output_folder为我们生成构建dataloader所需文件的路径
# 参数中涉及的路径以个人实际路径为准,建议将数据集放到dataset目录下,和教程保持一致
create_data_lists(voc07_path='../../../dataset/VOCdevkit/VOC2007',
voc12_path='../../../dataset/VOCdevkit/VOC2012',
output_folder='../../../dataset/VOCdevkit') 设置好对应路径后,我们运行数据集准备脚本:tiny_detector_demo$ python create_data_lists.py。
很快啊!dataset/VOCdevkit目录下就生成了若干json文件,这些文件会在后面训练中真正被用到。
不妨手动打开这些json文件,看下都记录了哪些信息。
下面来介绍一下parse_annotation函数内部都做了什么,json中又记录了哪些信息。这部分作为选学,不感兴趣可以跳过,只要你已经明确了json中记录的信息的含义。
"""python
xml文件解析
"""
import json
import os
import torch
import random
import xml.etree.ElementTree as ET #解析xml文件所用工具
import torchvision.transforms.functional as FT
#GPU设置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Label map
#voc_labels为VOC数据集中20类目标的类别名称
voc_labels = ('aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable',
'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor')
#创建label_map字典,用于存储类别和类别索引之间的映射关系。比如:{1:'aeroplane', 2:'bicycle',......}
label_map = {k: v + 1 for v, k in enumerate(voc_labels)}
#VOC数据集默认不含有20类目标中的其中一类的图片的类别为background,类别索引设置为0
label_map['background'] = 0
#将映射关系倒过来,{类别名称:类别索引}
rev_label_map = {v: k for k, v in label_map.items()} # Inverse mapping
#解析xml文件,最终返回这张图片中所有目标的标注框及其类别信息,以及这个目标是否是一个difficult目标
def parse_annotation(annotation_path):
#解析xml
tree = ET.parse(annotation_path)
root = tree.getroot()
boxes = list() #存储bbox
labels = list() #存储bbox对应的label
difficulties = list() #存储bbox对应的difficult信息
#遍历xml文件中所有的object,前面说了,有多少个object就有多少个目标
for object in root.iter('object'):
#提取每个object的difficult、label、bbox信息
difficult = int(object.find('difficult').text == '1')
label = object.find('name').text.lower().strip()
if label not in label_map:
continue
bbox = object.find('bndbox')
xmin = int(bbox.find('xmin').text) - 1
ymin = int(bbox.find('ymin').text) - 1
xmax = int(bbox.find('xmax').text) - 1
ymax = int(bbox.find('ymax').text) - 1
#存储
boxes.append([xmin, ymin, xmax, ymax])
labels.append(label_map[label])
difficulties.append(difficult)
#返回包含图片标注信息的字典
return {'boxes': boxes, 'labels': labels, 'difficulties': difficulties}看了上面的代码如果还不太明白,试试结合这张图理解下:
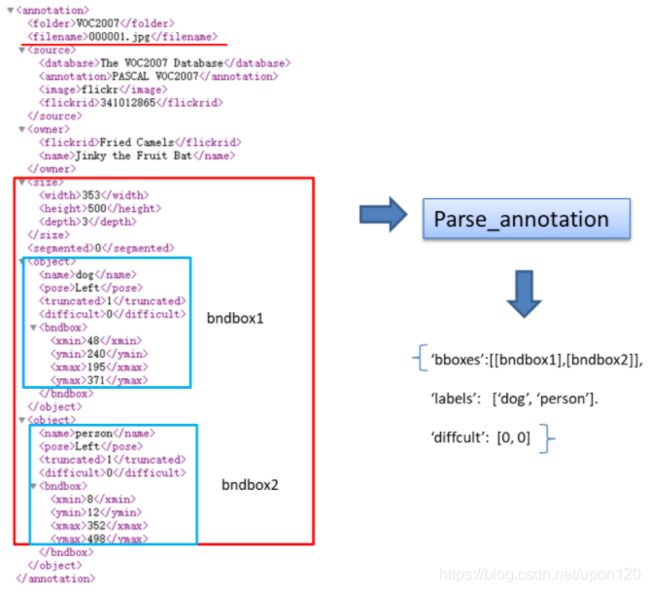
图10 xml解析流程图
接下来看一下create_data_lists函数在做什么。
"""python
分别读取train和valid的图片和xml信息,创建用于训练和测试的json文件
"""
def create_data_lists(voc07_path, voc12_path, output_folder):
"""
Create lists of images, the bounding boxes and labels of the objects in these images, and save these to file.
:param voc07_path: path to the 'VOC2007' folder
:param voc12_path: path to the 'VOC2012' folder
:param output_folder: folder where the JSONs must be saved
"""
#获取voc2007和voc2012数据集的绝对路径
voc07_path = os.path.abspath(voc07_path)
voc12_path = os.path.abspath(voc12_path)
train_images = list()
train_objects = list()
n_objects = 0
# Training data
for path in [voc07_path, voc12_path]:
# Find IDs of images in training data
#获取训练所用的train和val数据的图片id
with open(os.path.join(path, 'ImageSets/Main/trainval.txt')) as f:
ids = f.read().splitlines()
#根据图片id,解析图片的xml文件,获取标注信息
for id in ids:
# Parse annotation's XML file
objects = parse_annotation(os.path.join(path, 'Annotations', id + '.xml'))
if len(objects['boxes']) == 0: #如果没有目标则跳过
continue
n_objects += len(objects) #统计目标总数
train_objects.append(objects) #存储每张图片的标注信息到列表train_objects
train_images.append(os.path.join(path, 'JPEGImages', id + '.jpg')) #存储每张图片的路径到列表train_images,用于读取图片
assert len(train_objects) == len(train_images) #检查图片数量和标注信息量是否相等,相等才继续执行程序
# Save to file
#将训练数据的图片路径,标注信息,类别映射信息,分别保存为json文件
with open(os.path.join(output_folder, 'TRAIN_images.json'), 'w') as j:
json.dump(train_images, j)
with open(os.path.join(output_folder, 'TRAIN_objects.json'), 'w') as j:
json.dump(train_objects, j)
with open(os.path.join(output_folder, 'label_map.json'), 'w') as j:
json.dump(label_map, j) # save label map too
print('\nThere are %d training images containing a total of %d objects. Files have been saved to %s.' % (
len(train_images), n_objects, os.path.abspath(output_folder)))
#与Train data一样,目的是将测试数据的图片路径,标注信息,类别映射信息,分别保存为json文件,参考上面的注释理解
# Test data
test_images = list()
test_objects = list()
n_objects = 0
# Find IDs of images in the test data
with open(os.path.join(voc07_path, 'ImageSets/Main/test.txt')) as f:
ids = f.read().splitlines()
for id in ids:
# Parse annotation's XML file
objects = parse_annotation(os.path.join(voc07_path, 'Annotations', id + '.xml'))
if len(objects) == 0:
continue
test_objects.append(objects)
n_objects += len(objects)
test_images.append(os.path.join(voc07_path, 'JPEGImages', id + '.jpg'))
assert len(test_objects) == len(test_images)
# Save to file
with open(os.path.join(output_folder, 'TEST_images.json'), 'w') as j:
json.dump(test_images, j)
with open(os.path.join(output_folder, 'TEST_objects.json'), 'w') as j:
json.dump(test_objects, j)
print('\nThere are %d test images containing a total of %d objects. Files have been saved to %s.' % (
len(test_images), n_objects, os.path.abspath(output_folder)))同样,建议配图食用:
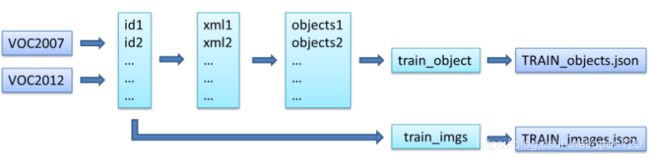
图11 数据准备流程图(以train_dataset为例)
到这里,我们的训练数据就准备好了,接下来开始一步步构建训练所需的dataloader吧!
2.构建dataloader
下面开始介绍构建dataloader的相关代码:
1)首先了解一下训练的时候在哪里定义了dataloader以及是如何定义的。
以下是train.py中的部分代码段:
#train_dataset和train_loader的实例化
train_dataset = PascalVOCDataset(data_folder,
split='train',
keep_difficult=keep_difficult)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True,
collate_fn=train_dataset.collate_fn, num_workers=workers,
pin_memory=True) # note that we're passing the collate function here可以看到,首先需要实例化PascalVOCDataset类得到train_dataset,然后将train_dataset传入torch.utils.data.DataLoader,进而得到train_loader。
2)接下来看一下PascalVOCDataset是如何定义的。
代码位于 datasets.py 脚本中,可以看到,PascalVOCDataset继承了torch.utils.data.Dataset,然后重写了__init__ , __getitem__, __len__ 和 collate_fn 四个方法,这也是我们在构建自己的dataset的时候需要经常做的工作,配合下面注释理解代码:
"""python
PascalVOCDataset具体实现过程
"""
import torch
from torch.utils.data import Dataset
import json
import os
from PIL import Image
from utils import transform
class PascalVOCDataset(Dataset):
"""
A PyTorch Dataset class to be used in a PyTorch DataLoader to create batches.
"""
#初始化相关变量
#读取images和objects标注信息
def __init__(self, data_folder, split, keep_difficult=False):
"""
:param data_folder: folder where data files are stored
:param split: split, one of 'TRAIN' or 'TEST'
:param keep_difficult: keep or discard objects that are considered difficult to detect?
"""
self.split = split.upper() #保证输入为纯大写字母,便于匹配{'TRAIN', 'TEST'}
assert self.split in {'TRAIN', 'TEST'}
self.data_folder = data_folder
self.keep_difficult = keep_difficult
# Read data files
with open(os.path.join(data_folder, self.split + '_images.json'), 'r') as j:
self.images = json.load(j)
with open(os.path.join(data_folder, self.split + '_objects.json'), 'r') as j:
self.objects = json.load(j)
assert len(self.images) == len(self.objects)
#循环读取image及对应objects
#对读取的image及objects进行tranform操作(数据增广)
#返回PIL格式图像,标注框,标注框对应的类别索引,对应的difficult标志(True or False)
def __getitem__(self, i):
# Read image
#*需要注意,在pytorch中,图像的读取要使用Image.open()读取成PIL格式,不能使用opencv
#*由于Image.open()读取的图片是四通道的(RGBA),因此需要.convert('RGB')转换为RGB通道
image = Image.open(self.images[i], mode='r')
image = image.convert('RGB')
# Read objects in this image (bounding boxes, labels, difficulties)
objects = self.objects[i]
boxes = torch.FloatTensor(objects['boxes']) # (n_objects, 4)
labels = torch.LongTensor(objects['labels']) # (n_objects)
difficulties = torch.ByteTensor(objects['difficulties']) # (n_objects)
# Discard difficult objects, if desired
#如果self.keep_difficult为False,即不保留difficult标志为True的目标
#那么这里将对应的目标删去
if not self.keep_difficult:
boxes = boxes[1 - difficulties]
labels = labels[1 - difficulties]
difficulties = difficulties[1 - difficulties]
# Apply transformations
#对读取的图片应用transform
image, boxes, labels, difficulties = transform(image, boxes, labels, difficulties, split=self.split)
return image, boxes, labels, difficulties
#获取图片的总数,用于计算batch数
def __len__(self):
return len(self.images)
#我们知道,我们输入到网络中训练的数据通常是一个batch一起输入,而通过__getitem__我们只读取了一张图片及其objects信息
#如何将读取的一张张图片及其object信息整合成batch的形式呢?
#collate_fn就是做这个事情,
#对于一个batch的images,collate_fn通过torch.stack()将其整合成4维tensor,对应的objects信息分别用一个list存储
def collate_fn(self, batch):
"""
Since each image may have a different number of objects, we need a collate function (to be passed to the DataLoader).
This describes how to combine these tensors of different sizes. We use lists.
Note: this need not be defined in this Class, can be standalone.
:param batch: an iterable of N sets from __getitem__()
:return: a tensor of images, lists of varying-size tensors of bounding boxes, labels, and difficulties
"""
images = list()
boxes = list()
labels = list()
difficulties = list()
for b in batch:
images.append(b[0])
boxes.append(b[1])
labels.append(b[2])
difficulties.append(b[3])
#(3,224,224) -> (N,3,224,224)
images = torch.stack(images, dim=0)
return images, boxes, labels, difficulties # tensor (N, 3, 224, 224), 3 lists of N tensors each3.关于数据增强
到这里为止,我们的dataset就算是构建好了,已经可以传给torch.utils.data.DataLoader来获得用于输入网络训练的数据了。
但是不急,构建dataset中有个很重要的一步我们上面只是提及了一下,那就是transform操作(数据增强)。
也就是这一行代码:
image, boxes, labels, difficulties = transform(image, boxes, labels, difficulties, split=self.split)需要注意的是,涉及位置变化的数据增强方法,同样需要对目标框进行一致的处理,因此目标检测框架的数据处理这部分的代码量通常都不小,且比较容易出bug。这里为了降低代码的难度,我们只是使用了几种比较简单的数据增强。
transform 函数的具体代码实现位于 utils.py 中,下面简单进行讲解:
"""python
transform操作是训练模型中一项非常重要的工作,其中不仅包含数据增强以提升模型性能的相关操作,也包含如数据类型转换(PIL to Tensor)、归一化(Normalize)这些必要操作。
"""
import json
import os
import torch
import random
import xml.etree.ElementTree as ET
import torchvision.transforms.functional as FT
"""
可以看到,transform分为TRAIN和TEST两种模式,以本实验为例:
在TRAIN时进行的transform有:
1.以随机顺序改变图片亮度,对比度,饱和度和色相,每种都有50%的概率被执行。photometric_distort
2.扩大目标,expand
3.随机裁剪图片,random_crop
4.0.5的概率进行图片翻转,flip
*注意:a. 第一种transform属于像素级别的图像增强,目标相对于图片的位置没有改变,因此bbox坐标不需要变化。
但是2,3,4,5都属于图片的几何变化,目标相对于图片的位置被改变,因此bbox坐标要进行相应变化。
在TRAIN和TEST时都要进行的transform有:
1.统一图像大小到(224,224),resize
2.PIL to Tensor
3.归一化,FT.normalize()
注1: resize也是一种几何变化,要知道应用数据增强策略时,哪些属于几何变化,哪些属于像素变化
注2: PIL to Tensor操作,normalize操作必须执行
"""
def transform(image, boxes, labels, difficulties, split):
"""
Apply the transformations above.
:param image: image, a PIL Image
:param boxes: bounding boxes in boundary coordinates, a tensor of dimensions (n_objects, 4)
:param labels: labels of objects, a tensor of dimensions (n_objects)
:param difficulties: difficulties of detection of these objects, a tensor of dimensions (n_objects)
:param split: one of 'TRAIN' or 'TEST', since different sets of transformations are applied
:return: transformed image, transformed bounding box coordinates, transformed labels, transformed difficulties
"""
#在训练和测试时使用的transform策略往往不完全相同,所以需要split变量指明是TRAIN还是TEST时的transform方法
assert split in {'TRAIN', 'TEST'}
# Mean and standard deviation of ImageNet data that our base VGG from torchvision was trained on
# see: https://pytorch.org/docs/stable/torchvision/models.html
#为了防止由于图片之间像素差异过大而导致的训练不稳定问题,图片在送入网络训练之间需要进行归一化
#对所有图片各通道求mean和std来获得
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
new_image = image
new_boxes = boxes
new_labels = labels
new_difficulties = difficulties
# Skip the following operations for evaluation/testing
if split == 'TRAIN':
# A series of photometric distortions in random order, each with 50% chance of occurrence, as in Caffe repo
new_image = photometric_distort(new_image)
# Convert PIL image to Torch tensor
new_image = FT.to_tensor(new_image)
# Expand image (zoom out) with a 50% chance - helpful for training detection of small objects
# Fill surrounding space with the mean of ImageNet data that our base VGG was trained on
if random.random() < 0.5:
new_image, new_boxes = expand(new_image, boxes, filler=mean)
# Randomly crop image (zoom in)
new_image, new_boxes, new_labels, new_difficulties = random_crop(new_image, new_boxes, new_labels,
new_difficulties)
# Convert Torch tensor to PIL image
new_image = FT.to_pil_image(new_image)
# Flip image with a 50% chance
if random.random() < 0.5:
new_image, new_boxes = flip(new_image, new_boxes)
# Resize image to (224, 224) - this also converts absolute boundary coordinates to their fractional form
new_image, new_boxes = resize(new_image, new_boxes, dims=(224, 224))
# Convert PIL image to Torch tensor
new_image = FT.to_tensor(new_image)
# Normalize by mean and standard deviation of ImageNet data that our base VGG was trained on
new_image = FT.normalize(new_image, mean=mean, std=std)
return new_image, new_boxes, new_labels, new_difficulties4.最后,构建DataLoader
至此,我们已经将VOC数据转换成了dataset,接下来可以用来创建dataloader,这部分pytorch已经帮我们实现好了,我们只需将创建好的dataset送入即可,注意理解相关参数。
"""python
DataLoader
"""
#参数说明:
#在train时一般设置shufle=True打乱数据顺序,增强模型的鲁棒性
#num_worker表示读取数据时的线程数,一般根据自己设备配置确定(如果是windows系统,建议设默认值0,防止出错)
#pin_memory,在计算机内存充足的时候设置为True可以加快内存中的tensor转换到GPU的速度,具体原因可以百度哈~
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True,
collate_fn=train_dataset.collate_fn, num_workers=workers,
pin_memory=True) # note that we're passing the collate function here学习真快乐啊~