Trends in Integration of Vision and Language Research: A Survey of Tasks, Datasets, and Methods
Tasks
Visual Description Generation
Image Description Generation
Standard Image Description Generation

Dense Image Description Generation:旨在局部目标处生成描述
Image Paragraph Generation:生成段落
Spoken Language Image Description Generation:变写为说
Stylistic Image Description Generation:添加语言风格,例如幽默,
Unseen Objects Image Description Generation:
Diverse Image Description Generation:
Controllable Image Description Generation: control and select the objects in an image to generate descriptions.
Video Description Generation
Global Video Description Generation:

Dense Video Description Generation: 类似与Dense Image Description Generation
Movie Description Generation: movie clips are used as input
Visual Storytelling
Image Storytelling:

Video Storytelling:

Visual Question Answering
Image Question Answering

Video Question Answering

Visual Dialog
Image Dialog

Video Dialog
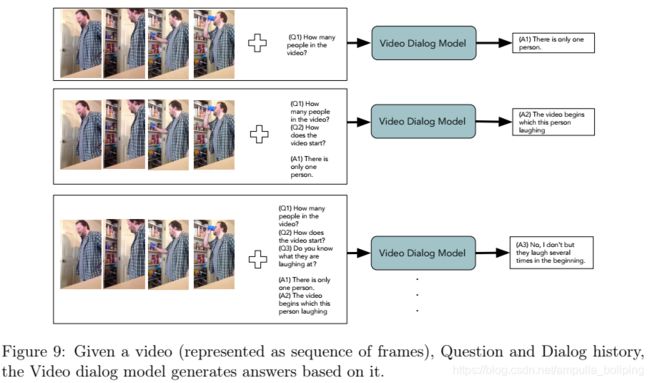
Visual Reasoning
Image Reasoning

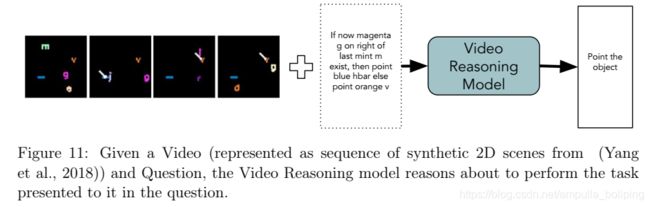
Video Reasoning
Video Referring Expression
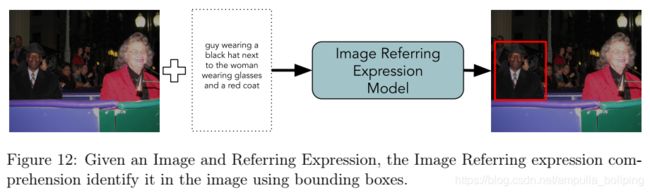
Image Referring Expression
Video Referring Expression

Visual Entailment
Image Entailment

Language-to-Vision Generation
Language-to-Image Generation
Sentence-level Language-to-Image Generation
Image Manipulation(图像编辑):生通过本文来引导图像的编辑, 同时保持其他文本不相关的区域,另一种方法是交互式的修改图像内容,还有一种是通过对话修改。
Fine-grain Image Generation(细粒度的图像生成):
Sequential Image Generation(序列图像生成):给定一段文字(多个句子),生成一系列的图像,就像故事的可视化,与image storytelling相反。
Language-to-Video Generation
需要更强的条件生成器,因为需要考虑时间维度

Vision-and-Language Navigation
Image and Language Navigation
Multimodal Machine Translation
Machine Translation with Image:将描述一副图像的源语言句子翻译成目标语言。

Multisource MMT:不同点:多种语言同时描述一副图像

Machine Translation with Video

Dataset
Image Description Generation
- Flickr8K

- Flickr30K:https://shannon.cs.illinois.edu/DenotationGraph

- Flickr30K-Entities:http://bryanplummer.com/Flickr30kEntities/


- MSCOCO:http://cocodataset.org/#home

- MSCOCO-Entities:https://github.com/aimagelab/show-control-and-tell

- STAIR(Japanese captions):http://captions.stair.center

- Multi30K-CLID(German captions)
https://www.statmt.org/wmt16/multimodal-task.html

https://www.statmt.org/wmt17/multimodal-task.html

http://www.statmt.org/wmt18/multimodal-task.html

- Conceptual Captions(large scale dataset):https://ai.google.com/research/ConceptualCaptions/download

Video Description Generation
- Microsoft Video Description (MSVD,contain Chinese, English, German etc):http://www.cs.utexas.edu/users/ml/clamp/videoDescription

- MPII Cooking(consists of 65 different cooking activities):https://www.mpi-inf.mpg.de/departments/computer-vision-and-machine-learning/research/human-activity-recognition/mpii-cooking-activities-dataset

- YouCook:http://web.eecs.umich.edu/~jjcorso/r/youcook

- YouCook II:http://youcook2.eecs.umich.edu

- Textually Annotated Cooking Scenes (TACoS):http://www.coli.uni-saarland.de/projects/smile/page.php?id=tacos

- TACoS-MultiLevel:https://www.mpi-inf.mpg.de/departments/computer-vision-and-machine-learning/research/vision-and-language/tacos-multi-level-corpus

- MPII Movie Description (MPII-MD):https://www.mpi-inf.mpg.de/departments/computer-vision-and-machine-learning/research/vision-and-language/mpii-movie-description-dataset
- Montreal Video Annotation (M-VAD):https://mila.quebec/en/publications/public-datasets/m-vad
- MSR Video to Text (MSR-VTT):http://ms-multimedia-challenge.com/2017/dataset
- Videos Titles in the Wild (VTW):http://aliensunmin.github.io/project/video-language/index.html#VTW
- ActivityNet Captions (ANetCap):http://activity-net.org/challenges/2017/captioning.html
- ActivityNet Entities (ANetEntities):https://github.com/facebookresearch/ActivityNet-Entities
Image Storytelling
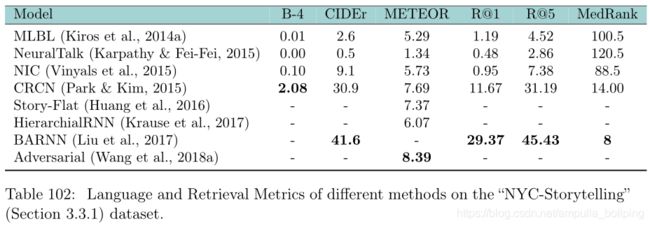
- New York City Storytelling (NYC-Storytelling):数据集被分成0.8,0.1,0.1,https://github.com/cesc-park/CRCN

- Disneyland Storytelling:数据集被分成0.8,0.1,0.1

- SIND:大规模数据集,数据集被分成0.8,0.1,0.1

- VIST:是SIND第二个版本,http://visionandlanguage.net/VIST
Video Storytelling
- VideoStory
- VideoStory-NUS
两个数据集都不是开源的
Image Question Answering
- VQA v1.0:answers也是open-ended,要么是少数单词,要么从多个给定答案中选择一个,https://visualqa.org

- VQA v2.0

- OK-VQA:https://okvqa.allenai.org

- KVQA:http://malllabiisc.github.io/resources/kvqa
Video Question Answering
- MovieQA:http://movieqa.cs.toronto.edu/home
- TVQA:http://tvqa.cs.unc.edu
- TVQA+:http://tvqa.cs.unc.edu/download_tvqa_plus.html
Image Dialog
- VisDial:https://visualdialog.org/data
- CLEVR-Dialog:https://github.com/satwikkottur/clevr-dialog
Video Dialog
- The Scene-Aware Dialog (AVSD):https://video-dialog.com
Image Reasoning
- Compositional Language and Elementary Visual Reasoning (CLEVR):https://cs.stanford.edu/people/jcjohns/clevr
- CLEVR-CoGenT:https://cs.stanford.edu/people/jcjohns/clevr
- GQA:https://cs.stanford.edu/people/dorarad/gqa
- Relational and Analogical Visual rEasoNing (RAVEN):http://wellyzhang.github.io/project/raven.html
Video Reasoning
- COG:https://github.com/google/cog#datasets
Image Referring Expression
Real Images
- RefCOCO:http://tamaraberg.com/referitgame
- RefCOCO+,
- RefCOCOg:https://github.com/lichengunc/refer
- RefClef:http://tamaraberg.com/referitgame
- GuessWhat:https://guesswhat.ai
Synthetic Images
- CLEVR-Ref+:https://cs.jhu.edu/~cxliu/2019/clevr-ref+
Video Referring Expression
- Cityscapes:https://www.cityscapes-dataset.com
- ORGaze:https://people.ee.ethz.ch/~arunv/ORGaze.html
Image Entailment
- V-SNLI
- SNLI-VE:https://github.com/necla-ml/SNLI-VE
Image Generation
- Oxford-102:http://www.robots.ox.ac.uk/~vgg/data/flowers/102
- Caltech-UCSD Birds (CUB):http://www.vision.caltech.edu/visipedia/CUB-200-2011.html
- MSCOCO-Gen:
Video Generation
没有开源的数据集
- Text2Video
Image-and-Language Navigation
- Room-2-Room (R2R):https://bringmeaspoon.org
- ASKNAV:https://github.com/debadeepta/vnla
- TOUCHDOWN:https://github.com/lil-lab/touchdown
Machine Translation with Image
- Multi30K-MMT:https://www.statmt.org/wmt18/multimodal-task.html
Machine Translation with Video
- VATEX:http://vatex.org/main/index.html
Miscellaneous
不是为了特定任务而设计的,间接有助于上述任务。
Visual Genome
- Visual Genome: comprehend interactions and relationships between objects observed in an image, https://visualgenome.org
- How2:https://srvk.github.io/how2-dataset
- Berkeley Deep Drive eXplanation (BDD-X):au-tonomous driving, https://github.com/JinkyuKimUCB/BDD-X-dataset
Representation
Vision
Image Representation
- global feature representation: 常使用AlexNet, VGG, GoogLeNet, Inception-v3, Residual Nets (ResNet) and DenseNets学习全局特征,然而,一些语言和视觉结合任务不适合使用预训练的特征。
- local feature representation: R-CNN等
Video Representation
Language
常使用RNN, LSTM, BiLSTM, GRU, BiGRU, Transformer
Vision and Language
Visual Storytelling


Visual Dialog


Visual Reasoning

Visual Referring Expression


Visual Entailment

Language-to-Vision Generation


Vision-and-Language Navigation

Multimodal Machine Translation


Evaluation Measures
Common Measures
Language Metrics
机器生成的文本和参考文本的单词重叠程度
- Bilingual Evaluation Understudy (BLEU):是为机器翻译提出的,以比较机器生成的输出与人类的ground truth, 常用于Visual Caption Generation, Visual Storytelling, Video Dialog and Multimodal Machine Translation, https://leimao.github.io/blog/BLEU-Score/, https://en.wikipedia.org/wiki/BLEU
- Metric for Evaluation of Translation with Explicit Ordering (METEOR): 常用于Visual Caption Generation, Visual Storytelling, Video Dialog and Multimodal Machine Translation, https://en.wikipedia.org/wiki/METEOR
- Recall Oriented Understudy for Gisting Evaluation (ROUGE): 常用于Visual Caption Generation, http://www.ccs.neu.edu/home/vip/teach/DMcourse/5_topicmodel_summ/notes_slides/What-is-ROUGE.pdf
- Consensus based Image Description Evaluation (CIDEr): 常用于image caption generation evaluation, Video Caption Generation, Visual Storytelling and Video Dialog
- Semantic Propositional Image Captioning Evaluation (SPICE):
Retriev al Metrics
- Recall@k (R@k)
- Median Rank (MedRank)
- Mean Reciprocal Rank (MRR)
- Mean Rank (Mean)
- Normalized Discounted Cumulative Gain (NDCG)
Task-specific Metrics
Image Reasoning
- Querying attribute (QA)
- Compare Attribute (CA)
- Compare Numbers (CN)
- Count
-
Exist
Video Reasoning
- Pointing
- Yes/No
- Conditional (Condit)
- Attribute-related (Atts)
Language-to-Vision Generation
- Inception Score (IS)
- Fréchet Inception distance (FID)
- R-precision
Vision-and-Language Na vigation
- Path Length (PL)
- Navigation Error (NE)
- Success Rate (SR)
- Oracle Success Rate (OSR)
- Success Path Length (SPL)
Human Evaluation
State-of-the-Art Results
Visual Storytelling Results
Image Storytelling

Video Storytelling

Visual Dialog Results
Image Dialog
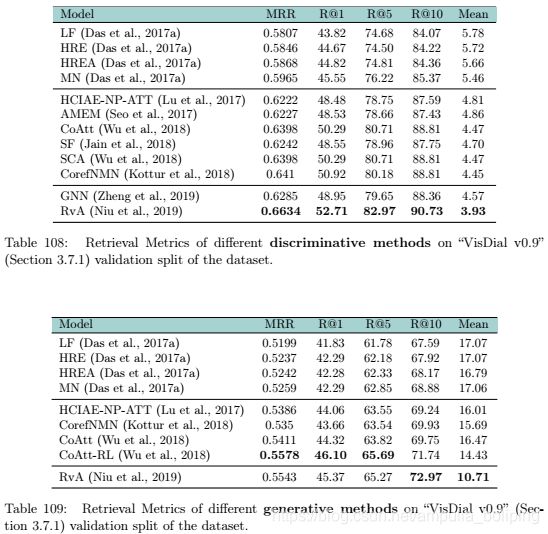

Video Dialog

Visual Reasoning Results
Image Reasoning
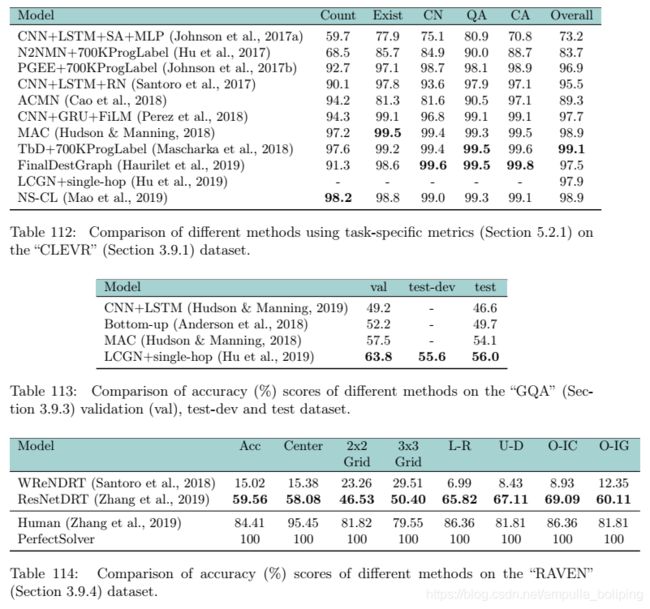
Video Reasoning
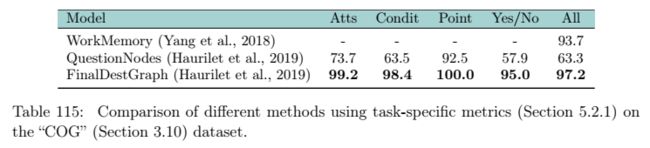
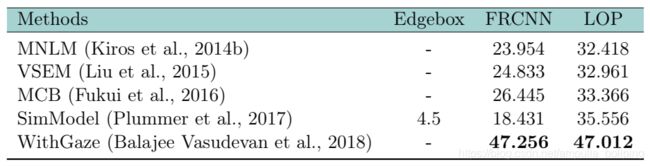
Image Referring Expression
Image Referring Expression

Video Referring Expression
Visual Entailment Results
Image Entailment

Language-to-Vision Generation Results
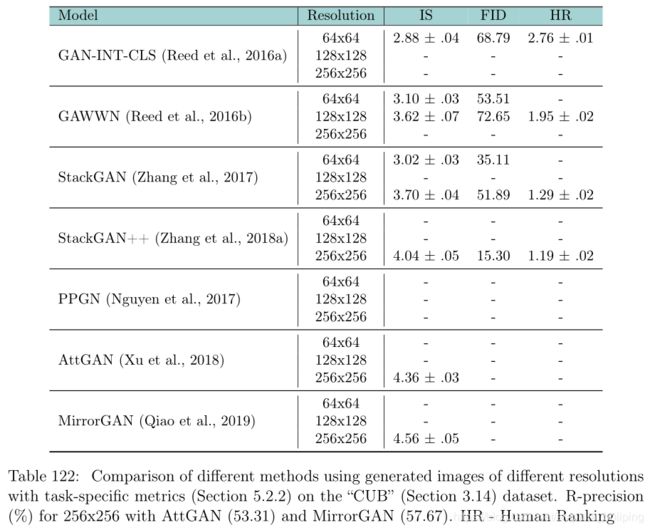
Language-to-Image Generation


Language-to-Video Generation

Vision-and-Language Navigation Results
Image-and-Language Navigation

Multimodal Machine Translation Results
Machine Translation with Image


Machine Translation with Video

Future Directions
- Leveraging External Knowledge
- Addressing Large-scale Data Limitations
- Combining Multiple Tasks
- Novel Neural Architectures for Representation: transformer
- Image vs Video:需要更多的关注video与language的结合
- Automatic Evaluation Measures: