openCV入门学习
openCV简介
openCV安装
openCV
openCV是计算机视觉的开源库。
优势:
支持多种编程语言
支持跨平台
活跃的开发团队
丰富的API
安装教程.
在安装之前,要先安装numpy和matplotlib。
1.下载python最新版本安装以后,直接执行下方命令即可,清华镜像速度贼快;
windows系统下cmd执行命令
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
验证是否成功
等待安装结束以后cmd中进入python,然后输入下方命令;
import CV2
如果没有报错则是安装成功,建议新建一个python程序测试一下;
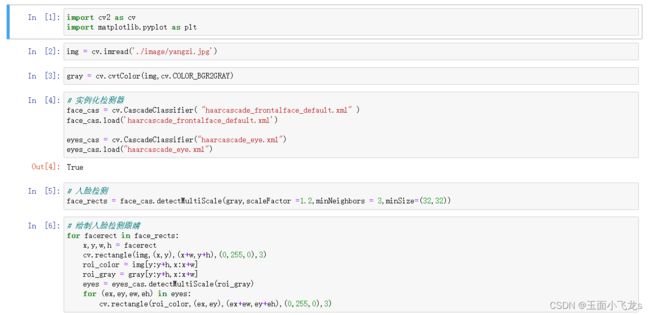
opencv案例
opencv读取默认读取图片代码:
import CV2
image = CV2.imread(“1.jpg”) # 读取一张图片存入变量中
CV2.imshow(“hello”, image) # 创建一个名字为hello的窗口,把image在窗口中展示
CV2.waitKey(0) # 等待用户按任意键
2.安装opencv-contrib-python
pip install opencv-contrib-python -i https://pypi.tuna.tsinghua.edu.cn/simple
openCV中的模块
core模块实现了最核心的数据结构及其基本运算,如绘图函数、数组操作相关函数等。
highgui模块实现了视频与图像的读取、显示、存储等接口。
imgproc模块实现了图像处理的基础方法,包括图像滤波、图像的几何变换、平滑、阈值分割、形态学处理、边缘检测、目标检测、运动分析和对象跟踪等。
features2d模块用于提取图像特征以及特征匹配,nonfree模块实现了一些专利算法,如sift特征。.
objdetect模块实现了一些目标检测的功能,经典的基于Haar、LBP特征的人脸检测,基于HOG的行人、汽车等目标检测,分类器使用Cascade Classification(级联分类)和Latent SVM等。
stitching模块实现了图像拼接功能。
FLANN模块(Fast Library for Approximate Nearest Neighbors),包含快速近似最近邻搜索FLANN和聚类Clustering算法。
ml模块机器学习模块(SVM,决策树,Boosting等等)。
photo模块包含图像修复和图像去噪两部分。
video模块针对视频处理,如背景分离,前景检测、对象跟踪等。
calib3d模块即Calibration(校准)3D,这个模块主要是相机校准和三维重建相关的内容。包含了基本的多视角几何算法,单个立体摄像头标定,物体姿态估计,立体相似性算法,3D信息的重建等等。
G-API模块包含超高效的图像处理pipeline引擎
openCV基本操作
图像的基本操作
图像的分类

彩色图的每一个通道就是一个灰度图
图像的IO操作
图像的读取
API
cv.imread()
参数:
要读取的图像路径
读取方式的标志
cv.IMREADCOLOR:以彩色模式加载图像,任何图像的透明度都将被忽略。这是默认参数。
cv.IMREADGRAYSCALE:以灰度模式加载图像
cv.IlMREAD_UNCHANGED:包括alpha通道的加载图像模式。
可以使用1、0或者-1来替代上面三个标志
注意:如果加载路径有错,不会报错,会返回一个None
图像的显示
API
cv.imshow()
参数:
显示图像的窗口名称,以字符串类型表示要加载的图像
注意:在调用显示图像的API后,要调用cv.waitKey()给图像绘制留下时间,否则窗口会出现无响应情况,并且图像无法显示出来。
另外我们也可使用matplotlib对图像进行展示。
一般image的维度是(w, h, c)就是宽,高和通道,默认显示的是rgb的顺序,但是opencv读取图像的通道是bgr的顺序读取的,所以在显示的时候要把通道调整过来,就是 bgr —> rgb
plt.imshow(img[:,:,::-1])中
第一个“:”表示x取所有
第二个“:”表示y取所有
::-1两个“x::y”其实表示的是,从x位置开始,间隔y取值,所以“::-1”表示的该维度倒着取值 其实就是所选的通道是bgr —> rgb
图像的保存
API
cv.imwrite()
参数:
文件名,要保存到哪里
要保存的图像
def show_img():
# 1读取图像
img = cv.imread("image/dili.jpg", 0)
# 2显示图像
# 2.1 openCV 显示方法
# cv.imshow("dili", img)
# cv.waitKey(0)
# cv.destroyAllWindows()
# 2.2使用matplotlib显示图像
# plt.imshow(img[:, :, ::-1])
plt.imshow(img, cmap=plt.cm.gray)
plt.show()
# 3图像的保存
cv.imwrite("image/dili2.jpg", img)
绘制几何图形
绘制直线
cv.line(img,start,end,color,thickness)
参数:
img:要绘制直线的图像
Start,end:直线的起点和终点
color:线条的颜色
Thickness:线条宽度
绘制圆形
cv.circle(img,centerpoint,r,color,thickness)
参数:
img:要绘制圆形的图像Centerpoint,
r: 圆心和半径
color:线条的颜色
Thickness:线条宽度,为-1时生成闭合图案并填充颜色
绘制矩形
cv.rectangle(img,leftupper,rightdown,color,thickness)
参数:
img:要绘制矩形的图像
Leftupper, rightdown:矩形的左上角和右下角坐标
color:线条的颜色
Thickness:线条宽度
向图像中添加文字
cv.putText(img,text,station,font,fontsize,color,thickness,cv.LINE_AA)
参数:
img:图像
text:要写入的文本数据
station:文本的放置位置
font:字体
Fontsize :字体大小
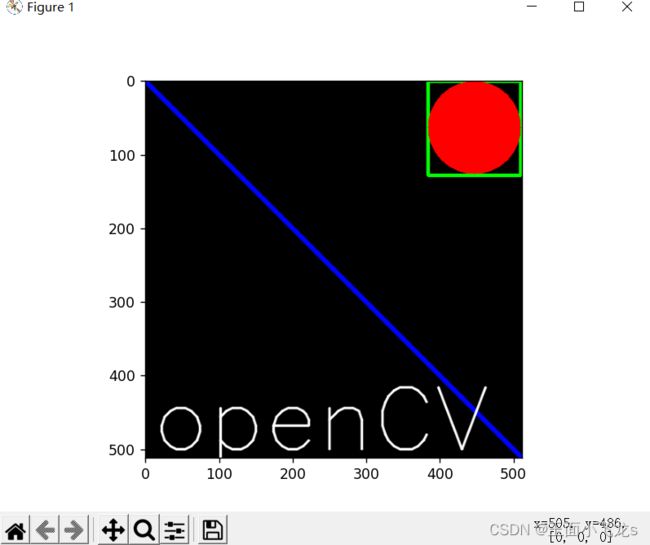
def show_jihe():
# 创建全黑的图像
img = np.zeros((512, 512, 3), np.uint8) # 512*512大小
# 绘制直线
cv.line(img, (0, 0), (511, 511), (255, 0, 0), 5) # openCV中是bgr的形式
# 绘制矩形
cv.rectangle(img, (384, 0), (510, 128), (0, 255, 0), 3)
# 绘制圆形
cv.circle(img, (447, 63), 63, (0, 0, 255), -1)
# 设置字体
font = cv.FONT_HERSHEY_SIMPLEX
# 添加文字
cv.putText(img, 'openCV', (10, 500), font, 4, (255, 255, 255), 2, cv.LINE_AA)
plt.imshow(img[:, :, ::-1])
plt.show()
获取并修改图像中的像素点

获取图像中的属性


图像通道的拆分与合并
![]()



色彩空间的改变

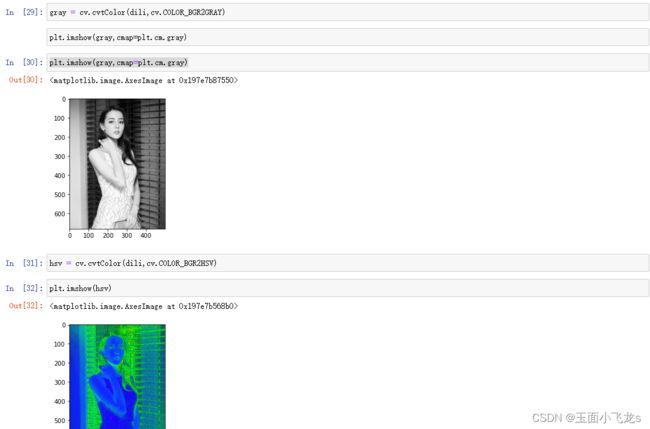
算术操作
图像的加法



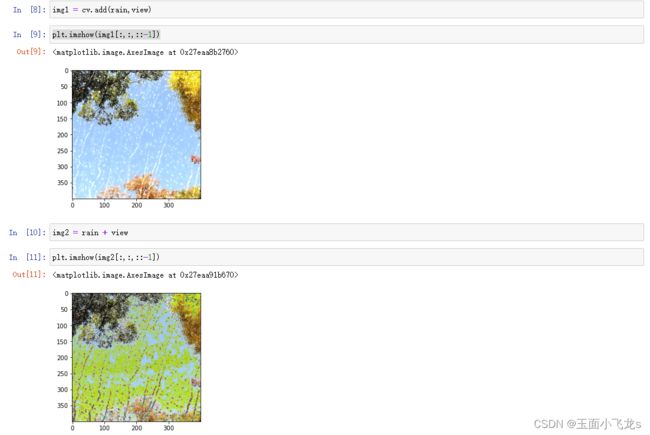
图像的混合

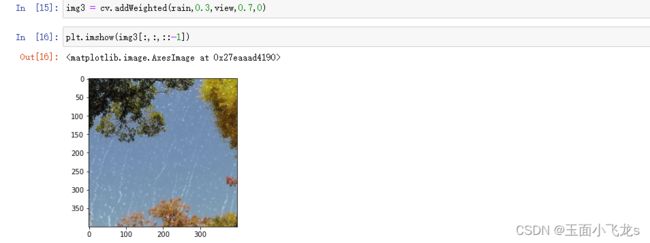
不论是图像加法还是图像混合,都要求图像大小是相同的。
openCV图像处理
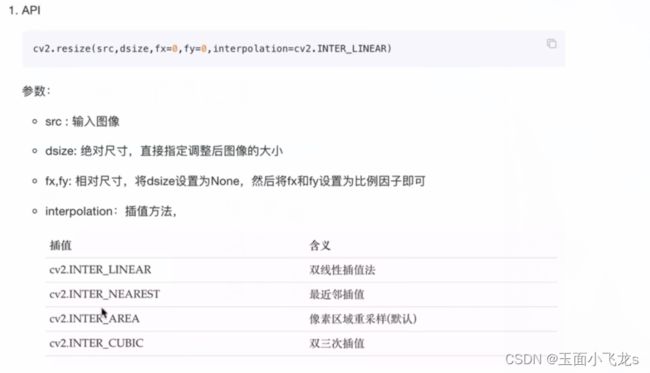
几何变换
图像的缩放
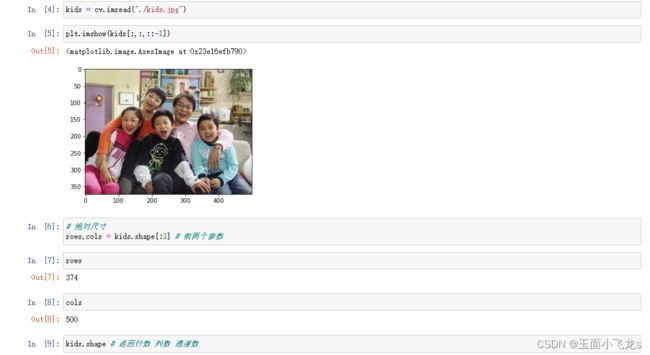


图像的平移



图像的旋转

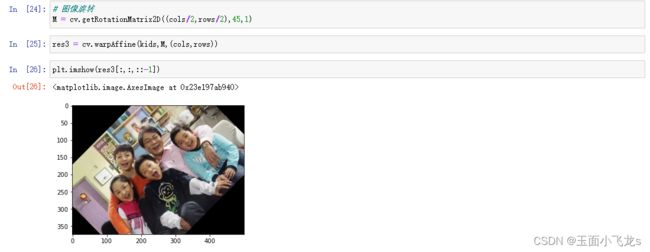
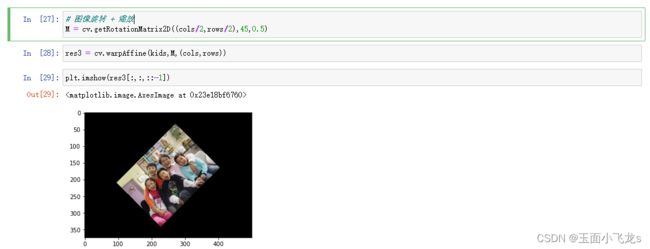
仿射变换
仿射变换:把平移和旋转结合起来的变换。


透射变换


图像金字塔



形态学操作
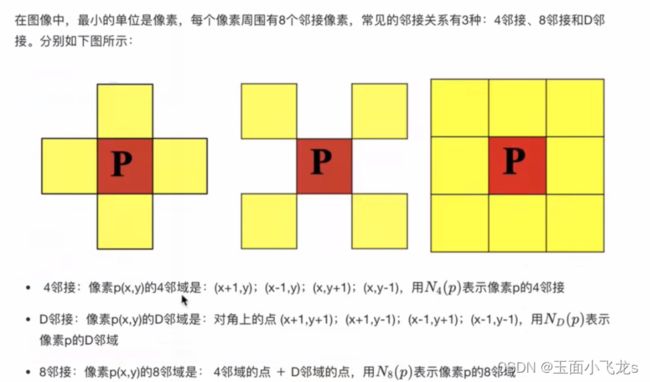
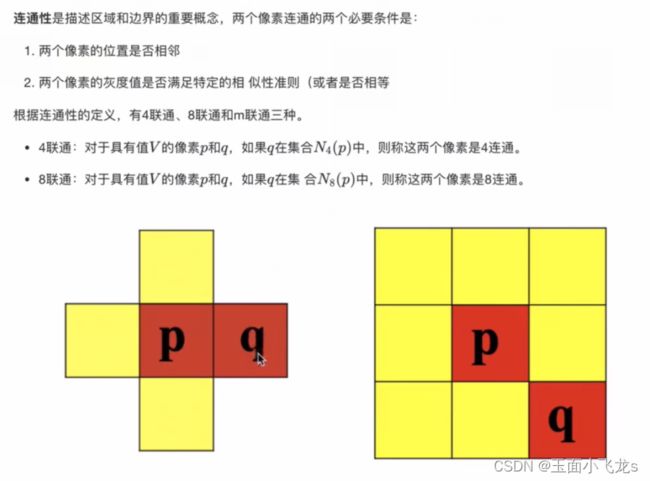
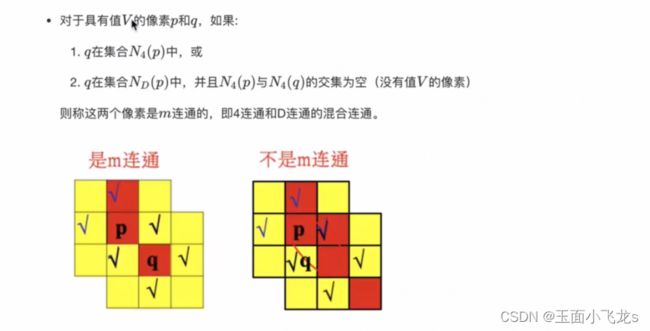
连通性
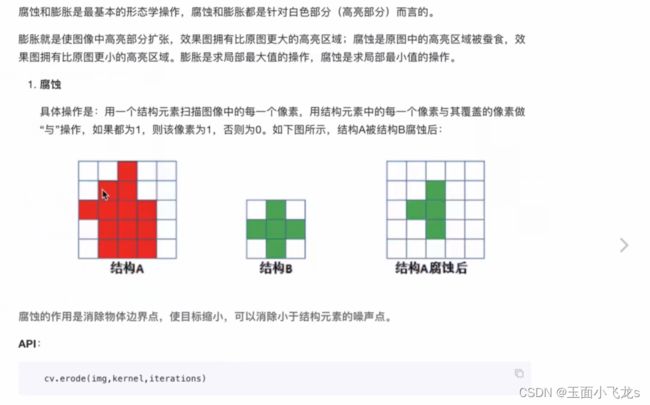
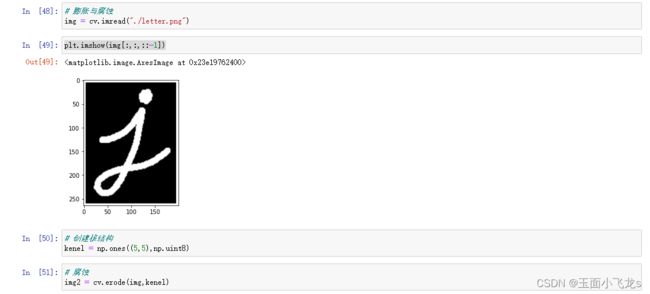
腐蚀与膨胀


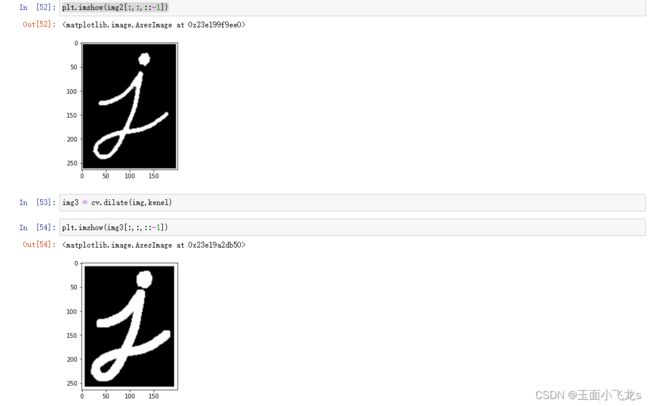
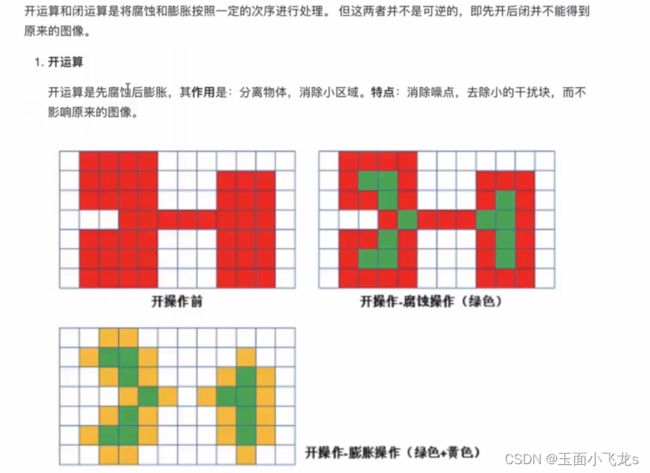
开闭运算


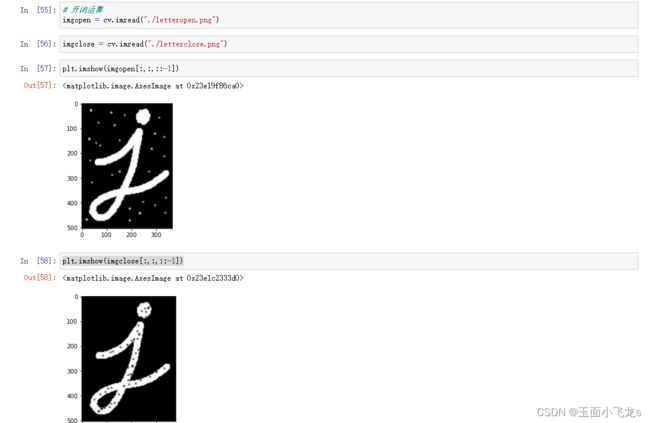
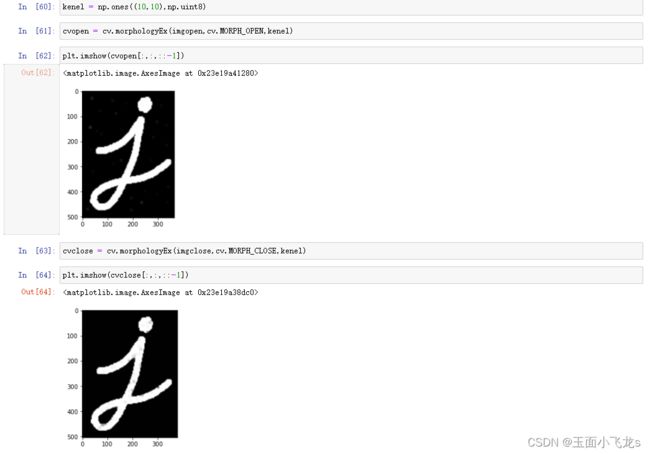
礼帽和黑帽



图像平滑
图像噪声
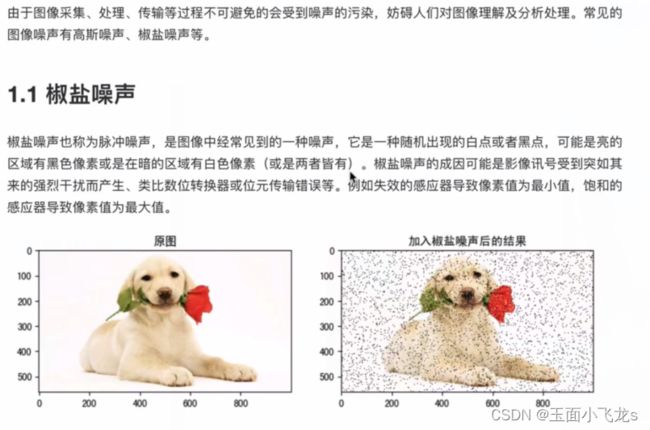
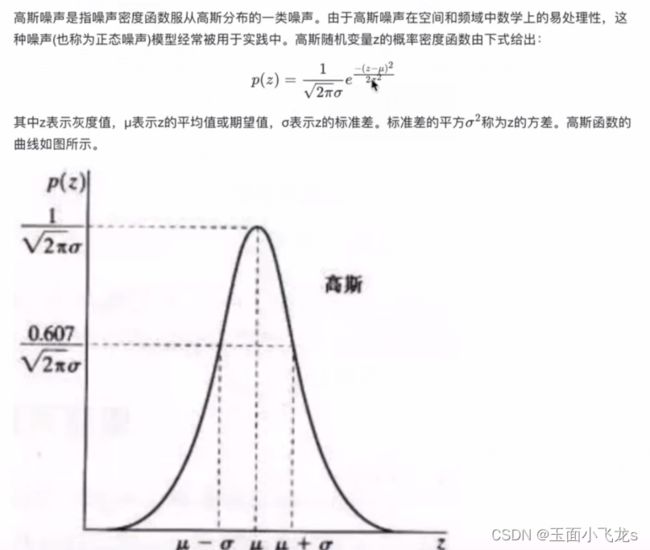
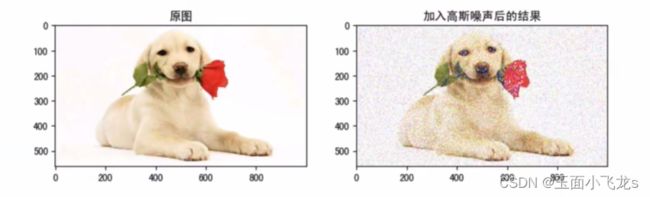
图像平滑

均值滤波

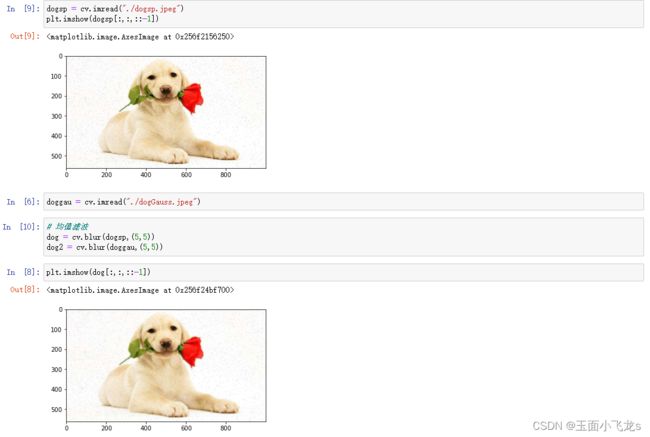
高斯滤波



中值滤波


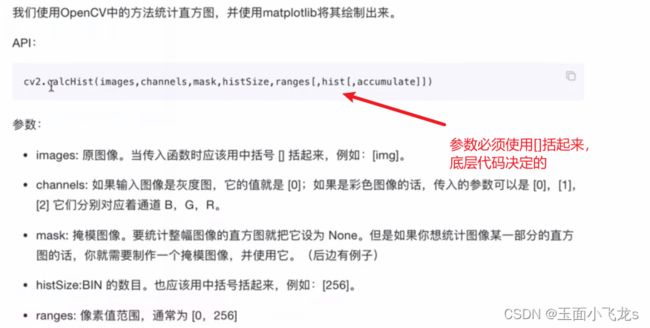
直方图
灰度直方图


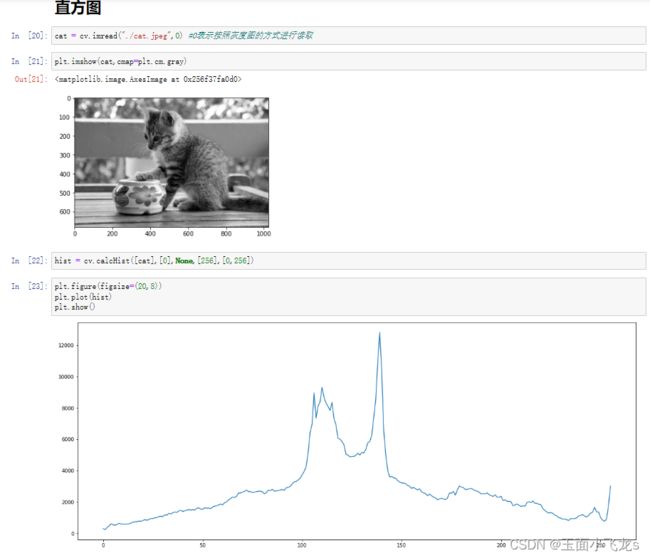
掩膜

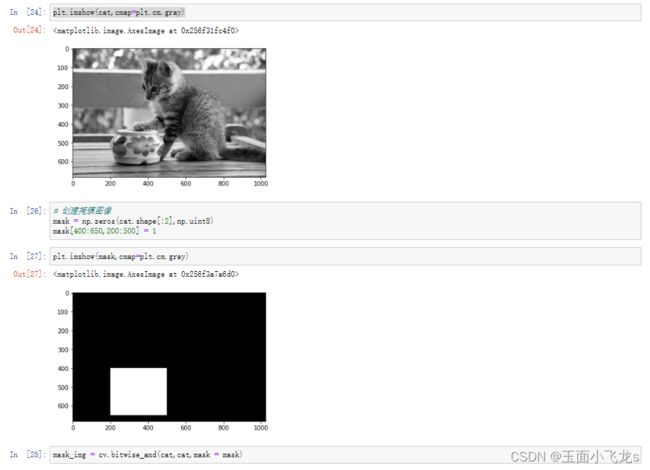
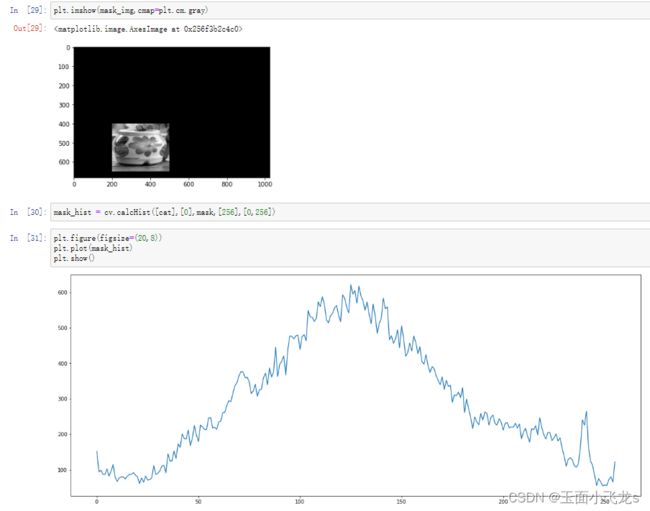
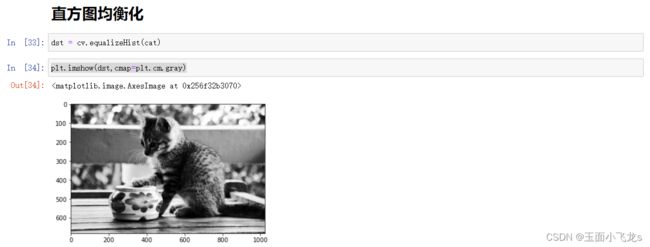
直方图均衡化



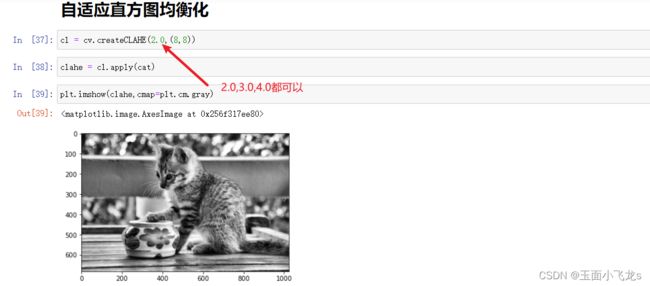
自适应直方图均衡化


边缘检测
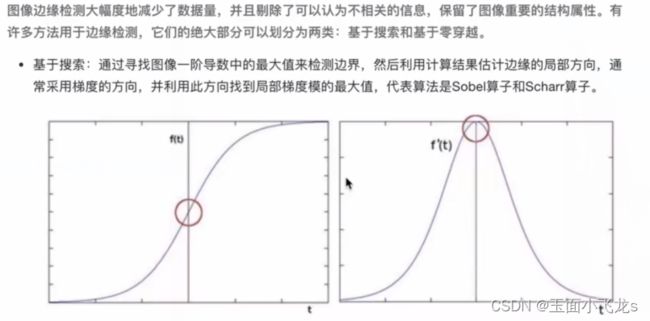
Sobel检测算子






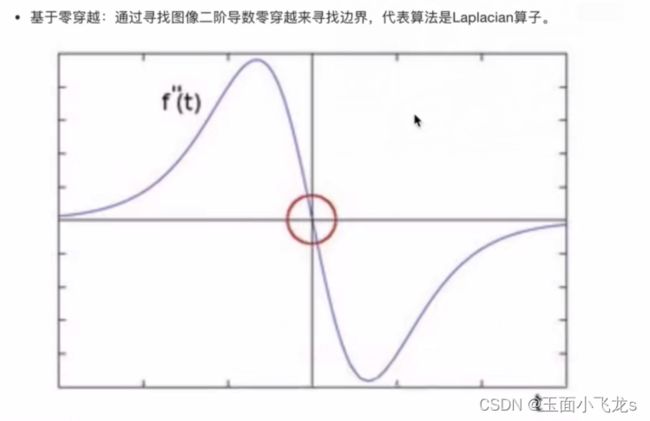
Laplacian算子


Canny检测(最优)





模板匹配和霍夫变换
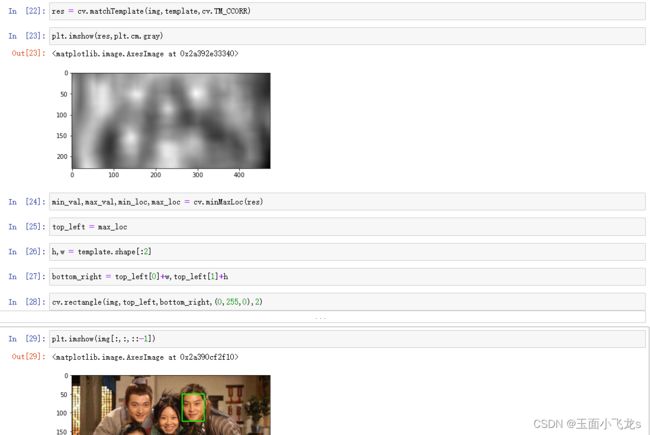
模板匹配
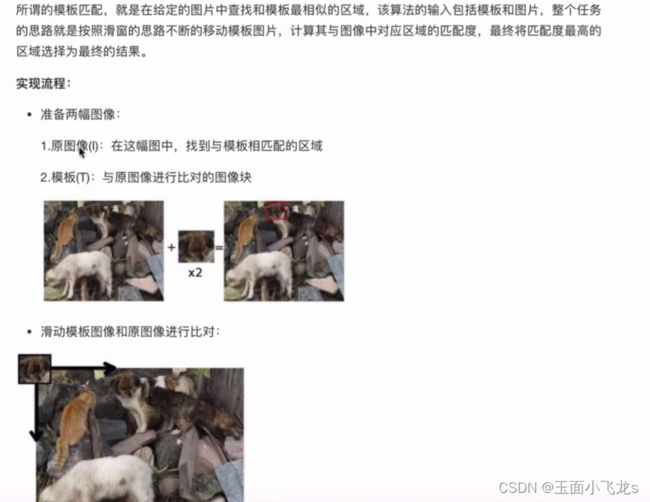


霍夫变换
霍夫线检测
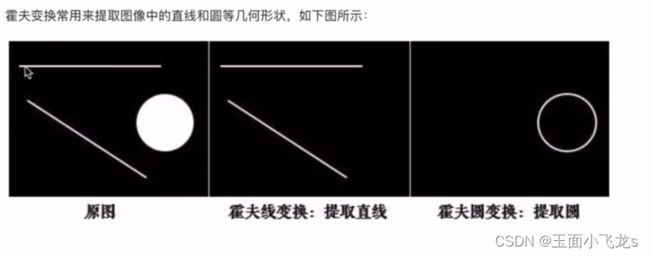

霍夫圆检测



图像特征提取与描述
角点特征
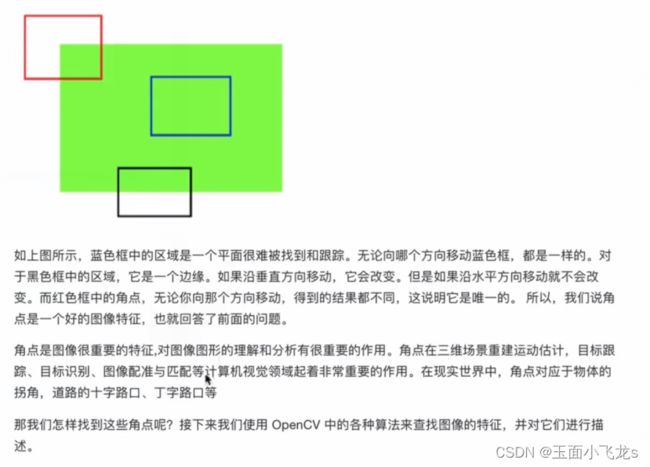
Harris和Shi-Tomas算法


Shi-Tomas是Harris的改进,可以更好的进行角点检测。


SIFT/SURF算法
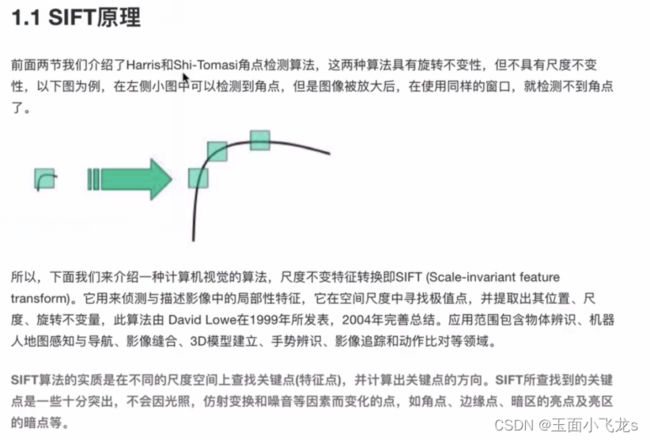


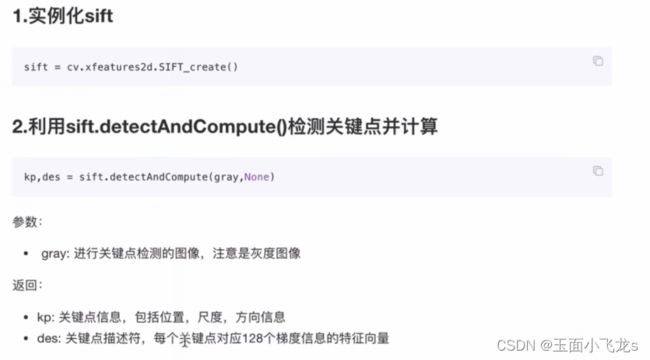


Fast和ORB算法
Fast



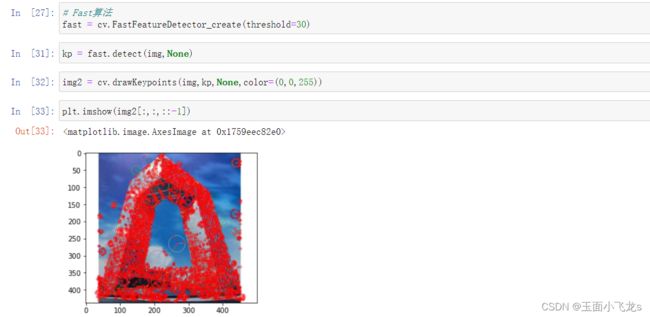
ORB



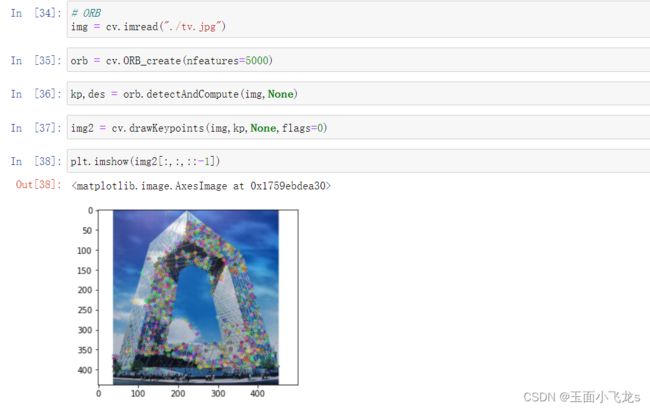
视频操作
视频读取




def video_read():
# 读取视频
cap = cv.VideoCapture("image/DOG.wmv")
# 判断是否读取成功
while (cap.isOpened()):
# 获取每一帧图像
ret, frame = cap.read()
# 是够获取成功
if ret == True:
cv.imshow("frame", frame)
if cv.waitKey(25)&0xFF == ord("q"): # 按“q”退出播放
break
cap.release()
cv.destroyAllWindows()

视频保存

def video_save():
cap = cv.VideoCapture("image/DOG.wmv")
width = int(cap.get(3))
height = int(cap.get(4))
out = cv.VideoWriter("image/out.avi", cv.VideoWriter_fourcc("M", "J", "P", "G"), 10, (width, height))
while(True):
ret, frame = cap.read()
if ret == True:
out.write(frame)
else:
break
cap.release()
out.release()
cv.destroyAllWindows()

视频追踪
meanshift算法


def video_run():
# 获取图像
cap = cv.VideoCapture("image/DOG.wmv")
# 获取第一帧图像并指定目标位置
ret, frame = cap.read()
# 目标 行列宽高
r, h, c, w = 197, 141, 0, 208
track_window = (c, r, w, h)
# 指定目标区域
roi = frame[r:r + h, c:c + w]
# 计算直方图
# 转化为彩色图片
hsv = cv.cvtColor(roi, cv.COLOR_BGR2HSV)
# 去除亮度的值
# mask=cv.inRange(hsv,np.array((0,68,32,12)),np.array(((23,432,12,54))))
# 计算直方图
hist = cv.calcHist(hsv, [0], None, [180], [0, 180])
# 进行归一化
cv.normalize(hist, hist, 0, 255, cv.NORM_MINMAX)
# 目标追踪
# 设置窗口搜索终止条件 最大迭代次数 窗口中心漂移最小值
term = (cv.TERM_CRITERIA_EPS | cv.TERM_CRITERIA_COUNT, 10, 1)
while (True):
# 获取每一帧图像
ret, frame = cap.read()
if ret == True:
# 计算直方图反向投影
realhsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)
realdst = cv.calcBackProject([realhsv], [0], hist, [0, 180], 1)
# 进行meanshift追踪
ret, track_window = cv.meanShift(realdst, track_window, term)
# 将追踪位置绘制在视频上 并进行显示
x, y, w, h = track_window
img2 = cv.rectangle(frame, (x, y), (x + w, y + h), 255, 2)
cv.imshow('frame', frame)
if cv.waitKey(60) & 0xFF == ord('q'):
break
else:
break
cap.release()
cv.destroyAllWindows()

Camshift

![]()
def video_run2():
# 获取图像
cap = cv.VideoCapture("image/DOG.wmv")
# 获取第一帧图像并指定目标位置
ret, frame = cap.read()
# 目标 行列宽高
r, h, c, w = 197, 141, 0, 208
track_window = (c, r, w, h)
# 指定目标区域
roi = frame[r:r + h, c:c + w]
# 计算直方图
# 转化为彩色图片
hsv = cv.cvtColor(roi, cv.COLOR_BGR2HSV)
# 去除亮度的值
# mask=cv.inRange(hsv,np.array((0,68,32,12)),np.array(((23,432,12,54))))
# 计算直方图
hist = cv.calcHist(hsv, [0], None, [180], [0, 180])
# 进行归一化
cv.normalize(hist, hist, 0, 255, cv.NORM_MINMAX)
# 目标追踪
# 设置窗口搜索终止条件 最大迭代次数 窗口中心漂移最小值
term = (cv.TERM_CRITERIA_EPS | cv.TERM_CRITERIA_COUNT, 10, 1)
while (True):
# 获取每一帧图像
ret, frame = cap.read()
if ret == True:
# 计算直方图反向投影
realhsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)
realdst = cv.calcBackProject([realhsv], [0], hist, [0, 180], 1)
# 进行meanshift追踪
ret, track_window = cv.CamShift(realdst, track_window, term)
# 将追踪位置绘制在视频上 并进行显示
pts = cv.boxPoints(ret)
pts = np.int0(pts)
img2 = cv.polylines(frame, [pts], True, 255, 2)
cv.imshow('frame', img2)
if cv.waitKey(60) & 0xFF == ord('q'):
break
else:
break
cap.release()
cv.destroyAllWindows()
总结:

人脸检测