论文拜读-Deep Sliding Shapes for Amodal 3D Object Detection in RGB-D Image
论文拜读-Deep Sliding Shapes for Amodal 3D Object Detection in RGB-D Image
- Deep Sliding Shapes for Amodal 3D Object Detection in RGB-D Image
-
- Abstract
- 贡献
- 流程
-
- 1、3D编码表示
- 2、多尺度3D区域选择网络
- 3、联合无模态目标识别网络
- 实验
- 总结
Deep Sliding Shapes for Amodal 3D Object Detection in RGB-D Image
前两天看到这篇文章,拜读后,想整理一下思路。
这篇文章的作者来自普林斯顿,文章发表在CVPR16,原文在此。
Abstract
我们专注于在RGB-D图像中进行无模态(amodal)3D对象检测的任务,其目的是在最大范围内以公制形式生成对象的3D边界框。我们介绍了Deep Sliding Shapes,一种3D ConvNet公式,它以RGB-D图像中的3D立体场景作为输入并输出3D对象边界框。在我们的方法中,我们提出了第一个从几何形状中学习物体性的3D区域提议网络(RPN),以及第一个联合的对象识别网络(ORN)以提取3D的几何特征和2D的颜色特征。特别是,我们通过训练两种不同比例的无模态RPN和ORN回归3D边界框来处理各种大小的对象。实验表明,我们的算法在mAP方面比最新技术好13.8,并且比原始“滑动形状”快200倍。提供了源代码和预先训练的模型。
在本文中,作者将重点放在对RGB-D图像的无模态3D目标检测(amodal object detection)任务上,旨在得到对象的3D边界框,可以得到目标在3D世界中完整的边界框,不受截断或遮挡的影响。
在当时,以2d为中心的深度RCNN网络优于以3d为中心的网络,但其原因可能是在于ImageNet数据库的强大以及网络设计的成熟,因此作者提出疑问,是否在3d中的深度学习可以提供更为强大的检测方法?
贡献
1、首次提出3D Region Proposal Network(RPN);

2、首次提出联合目标识别网络(joint ORN)-----2D ConvNet提取图像特征,3D ConvNet提供深度几何特征;
3、首次直接使用3D框,并做了实验表明3D ConvNet可以更好的编码几何特征。

其次,作者还论述了算法好的5个原因:
我们的设计充分利用了3D的优势。因此,我们的算法自然会从以下五个方面受益:
首先,我们可以预测3D边界框,而无需从额外的CAD数据中拟合模型的额外步骤。由于网络可以直接针对最终目标进行优化,因此可以极大地简化流水线,加快速度并提高性能。
其次,由于遮挡,有限的视场以及投影导致的尺寸变化很大,因此在2D模式下很难生成和识别模态提案。但是在3D中,由于同一类别的对象通常具有相似的物理尺寸,而遮挡物的干扰又落在了窗外,因此我们的3D滑动窗口建议生成可以自然地支持无模式检测。
第三,通过以3D形式表示形状,我们的ConvNet可以在更好的对齐空间中学习有意义的3D形状特征。
第四,在RPN中,自然界中的接收域自然地代表了尺寸,这指导了我们的建筑设计。
最后,我们可以通过使用“曼哈顿世界”假设来定义边界框方向,从而利用简单的3D上下文先验条件。
流程
1、3D编码表示
本文采用Truncated Signed Distance Function(TSDF)来进行3D编码表示,将3D空间转化为等距的3D体素网格,使用方向性的TSDF,每个体素中存放[dx,dy,dz],记录三个方向最接近表面的距离,然后还使用了投影TSDF来加快计算速度。
2、多尺度3D区域选择网络
1、输入
任何给定的3D场景,我们将其旋转以与重力方向对齐,作为我们的相机坐标系。根据规格。对于大多数RGB-D相机,我们将3D空间的有效范围定为水平[-2.6,2.6]米,垂直[-1.5,1]米,深度[0.4,5.6]米。在此范围内,我们通过体积为TS25的体积TSDF对3D场景进行了编码,网格大小为208×208×100,这是3D RPN的输入。
2、选取方向
作者在Manhanttan世界假设下,使用RANSAC平面拟合,将结果作为提出box的方向,在大多数情况该方法可提供相当准确的box方向。
3、选取锚点
对于每个Sliding window(既卷积)的位置,预测N个不同大小和尺寸的box,本文使用的 N = 19 \N = 19 N=19
4、多尺度RPN
Anchor box的屋里尺寸差异较大,我们使用多尺度RPN,将大尺寸的物体通过一个池化层来增加感受野,通过Anchor的物理大小与感受野的接近程度将anchor分为两个级别,通过不同的感受野来预测
5、完整的3D卷积结构
即fig1中所示。2x2x2的filter应用于lv1的anchors,其感受野为0.4m3,5x5x5的filter应用于lv2的anchors,其感受野为1m3。
6、去除空box
在给定1中所述的range,resolution和网络结构后,每张图片的anchors为1,387,646个(19x53x53x26),其中绝大部分都是空的,点的密度应该是很低的(小于0.005 points/cm3),因此使用3D积分图像来去除这些空点,平均留下107,674个点。这里对于测试集和训练集数据均处理。
7、训练采样?
对于剩余anchors,若其真实IOU得分大于0.35,标记为正,小于0.15标记为负。在实现中,每个小批量包含两个图像。在每个图像中以正比和负比1:1随机采样256个anchors。如果少于128个正样本,我们用来自同一图像的负样本填充小批量生产。我们通过指定最终卷积层中每个锚点的权重来选择它们。这里我不太能理解
8、3D框回归
我们用其中心[cx,cy,cz]和该框的大小[s1,s2,s3]在该框的三个主要方向上表示每个3D框(anchors的锚定方向,以及人类注解基本事实)。为了训练3D框回归器,我们将预测锚点框与其地面真实框之间的中心和大小差异。为简单起见,我们不对方向进行回归。对于每个正向锚点及其对应的地面真实情况,我们用它们在相机坐标系中的差异[∆cx,∆cy,∆cz]表示框中心的偏移。对于大小差异,我们首先找到两个盒子之间最接近的主方向匹配,然后计算每个匹配方向上盒子尺寸的偏移量[∆s1,∆s2,∆s3]。与[17]类似,我们通过锚点大小对大小差异进行归一化。对于每个正锚t = [∆cx,∆cy,∆cz,∆s1,∆s2,∆s3],我们的3D框回归目标是6元向量。
9、多任务损失函数
多任务损失函数为 L ( p , p ∗ , t , t ∗ ) = L c l s ( p , p ∗ ) + λ p ∗ L r e g ( t , t ∗ ) L(p,p^*,t,t^*)=L_{cls}(p,p^*)+\lambda p^*L_{reg}(t,t^*) L(p,p∗,t,t∗)=Lcls(p,p∗)+λp∗Lreg(t,t∗),其中右式前者表示目标得分,后者表示目标框得分。
10、3D NMS
RPN网络为所有的剩余anchors产生目标得分,我们在IOU阈值在0.35以上的框应用3D非最大抑制(3D NMS)仅选择前2000个box作为输出到识别网络中。这也是该算法比原始的3D滑动算法快的关键原因。
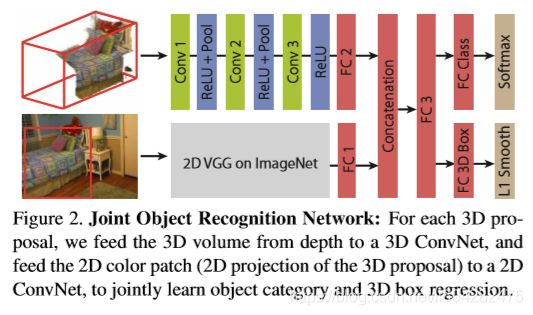
3、联合无模态目标识别网络
在我们得到3D提案框后,我们将每个框中的3D空间输入到对象识别网络(ORN)中,这样ORN提供的最终建议则为目标的最终边界框。作者建议使用amodal box(此处并未理解清楚,还需进一步了解)来得到目标的完整空间。
1、 3D目标识别网络:对每个提议框按尺寸12.5%padding,以编码一些上下文关系,然后将空间划分为30x30x30的体素网格,并用TSDF对几何进行编码形状。具体网络参数在此不作详细说明。
2、2D目标识别网络:直接使用在ImageNet上面训练好的VGG模型。
3、联合网络:
Pipeline即如贡献2图中所示,构造了联合了2D和3D的识别网络,将3D VGG网络和我们的ORN网络合并到一个特征向量中,传入全连接层,作为输入来预测目标标签和box。
4、多任务损失:
损失函数由分类损失和3Dbox回归损失构成,损失函数如下:
L ( p , p ∗ , t , t ∗ ) = L c l s ( p , p ∗ ) + λ ′ [ p ∗ > 0 ] L r e g ( t , t ∗ ) L(p,p^*,t,t^*)=L_{cls}(p,p^*)+\lambda '[p^*>0]L_{reg}(t,t^*) L(p,p∗,t,t∗)=Lcls(p,p∗)+λ′[p∗>0]Lreg(t,t∗)
p为对20个对象类别的预测概率,负的、non-object的对象被分为0类。对每个mini-batch,从不同图像中采样384个examples,positive:negative 为3:1。而对box回归来说,每个目标的偏移量作为loss function。
5、SVM & 3D NMS
我们从全连接层中提取出特征,在根据对象类别训练SVM,根据其得分再应用到3D NMS中来预测目标标签,对于目标框的回归,我们直接使用神经网络输出的结果。
6、修建边界框大小
当使用amodal边界框时,边界框的大小会提供有利于目标识别的有用信息。因此作者检查了每个方向的box sizes,每对box边缘的横纵比,与训练集中收集的分布对比,若不在分布的1%-99%范围内,说明其框有异常,降低2点其得分。
实验
RPN训练时长10h,ORN训练时长17h,测试耗时PRN-5.62s/image,ORN-13.93s/image,这比深度RCNN和Sliding的方法要快得多。


总结
个人感觉本文的思路很大一部分来自于Sliding Shapes for 3D Object Detection in Depth Images一文。重点在于使用了滑动窗口来产生amodal的box以至于可以达到更好的检测效果,具体的原理,我目前也还未了解清楚。