【20210409期AI简报】INT8加速训练方案、用树莓派打造的寄居蟹机器人
导读:本期为 AI 简报 20210409 期,将为您带来 8 条相关新闻,今日二候田鼠化驾~
本文一共 2300 字,通篇阅读结束需要 5~8 分钟
1. 只要你一句话,马斯克就得留扫把头,项目已开源丨Adobe等出品 | 量子位

项目地址:
https://github.com/orpatashnik/StyleCLIP论文地址:
https://arxiv.org/abs/2103.17249
现在,Adobe不想让你用手P图了——动动口就行。
只需要你说一句话,计算机就能P出你想要的效果。
例如,说出想要的发型,马斯克就会立刻被剃头:“Hi-top Fade(扫把头),变!
甚至还能直接改变人样,给小李子变出胡子、金发后,变成特朗普!

简直是手残P图玩家的福音。
没错,这是来自Adobe、希伯来大学、特拉维夫大学的新操作,只需要一句话,就能让计算机“修”出你想要的图片。
现在,项目已经开源。
2. 阿里达摩院提出:首个精度无损的INT8加速训练方案 | AAAI 2021 |CVer
论文:
https://arxiv.org/abs/2102.04782
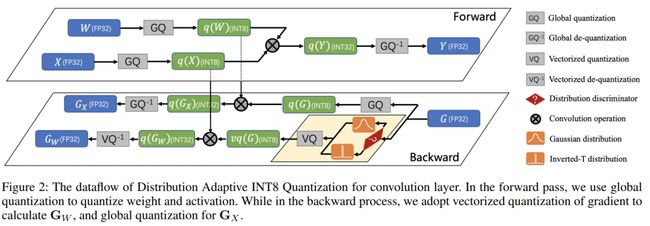
本文是阿里巴巴达摩院视觉实验室潘攀博士团队在量化加速训练方面的一次探索。
针对INT8计算快的特点,研究者尝试在卷积网络中,用INT8计算替代传统的浮点计算来加速训练过程(包括前向+反向)。
通过对反向梯度的深入分析,分别提出了
Gradient Vectorized Quantization
Magnitude-aware Clipping Strategy
两大策略来实现INT8的无损提速。
在ImageNet,CIFAR,COCO等数据集上,几乎做到了精度无损。
结合TensorCore,可以比FP16快18%,比FP32快200%。
3. 树莓派驱动,MIT打造的寄居蟹机器人「能做任何事」 | 机器之心
Image论文链接:
https://dam-prod.media.mit.edu/x/2020/10/21/HERMITS_UIST2020_ACM.pdf
视频地址:
https://v.qq.com/x/page/t3234z6bsc1.html
如何能让动作有限的机器人掌握无数种能力?
MIT 的研究者从寄居蟹这种生物中汲取了灵感,设计出了一种多功能机器人——HERMITS。这种机器人分为两个部分——能自主移动的小方块和无法自主移动的外壳。
每换一种外壳,小机器人就能切换一种任务模式.
如今,研究者已经可以借助 14 台树莓派同时控制 70 多个机器人。
使用树莓派或许不是最好的解决方案,但却可以降低 HERMITS 的成本,同时增加其易用性。
正如 MIT 的 demo 所示,这种寄居蟹机器人可以承载的想象空间是无限的。
项目未开源
4. 修图动口不动手,有人把StyleGAN和CLIP组了个CP,能听懂修图指令那种 | 机器之心

StyleGAN+CLIP=StyleCLIP论文链接:
https://arxiv.org/pdf/2103.17249.pdf
项目链接:
https://github.com/orpatashnik/StyleCLIP
有人认为,自然语言将是软件的下一代接口:你有什么需求,「告诉」它就行了,剩下的不用你管。这种「动动嘴皮子就能把事儿办了」的场景似乎也越来越多。
在最近的一篇论文中,来自希伯来大学、特拉维夫大学、Adobe 等机构的研究者提出了一种名为「StyleCLIP」的模型,几乎可以让你动动嘴皮子就把图修了。
这里用「几乎」是因为研究者给出的接口其实还是文字版的。如下图所示,如果你想让一只猫看起来可爱一点,只需要输入「cute cat」,模型就能够把猫的眼睛放大,同时改变其他影响其可爱值的特征。
利用这个界面,你还可以改变图中人物的发型、性别等特征。
但这种趋势也存在一些问题,比如眼下的 AI 能不能完全听懂人话呢?或者人类需要创造一种全新的语言用于跟 AI 沟通?
也许在未来,程序员不再敲代码,而是要输入一些类似口语却又不是口语的文字。
5. MMOCR来了!OpenMMLab 全流程的文字检测识别理解工具箱 | CVer

本文作者:OpenMMLab | 来源:知乎
https://zhuanlan.zhihu.com/p/362998190
MMOCR:
https://github.com/open-mmlab/mmocr
号外号外,OpenMMLab 有新成员加入咯~
“语言使人类别于禽兽,文字使文明别于野蛮,教育使先进别于落后”
我们在 OpenMMLab 项目中开源了 MMOCR。
这是一个专注于文字检测,识别以及下游任务如关键信息提取的工具箱,它目前包含了10多种常见的算法。
MMOCR 具有以下特点:
全流程:支持文字检测、文字识别以及其下游任务,比如关键信息提取等。
多模型:我们实现了 10 余种优秀算法。文字检测算法包括单阶段检测算法和双阶段检测算法;文字识别包含规则文字识别和非规则文字识别算法;关键信息提取包含基于图模型的关键信息提取算法。
模块设计:我们使用统一框架和模块化设计实现了各个算法模块。
公平对比:现有文字检测识别方法,往往使用不同的训练数据,预训练模型,数据增强方法,网络 backbone,优化器以及学习率策略。
快速入门:我们统一了常见的学术数据集合的标注文件格式,并提供了已经处理好的标注文件。同时我们提供了丰富的预训练模型,benchmark 和详细的文档,帮助大家快速上手。
值得强调的是,现在的 MMOCR 不仅仅是研究导向的框架,还是一个可以用于入门,教学,以及工业实际生产的框架。
我们逐步会加入更多的算法以及多语言模型,我们也欢迎大家贡献代码以及模型。
6. 新手手册:Pytorch分布式训练 | 夕小瑶的卖萌屋
文 | 花花@机器学习算法与自然语言处理
单位 | SenseTime 算法研究员
文中所有教学代码和日志见:
https://link.zhihu.com/?target=https%3A//github.com/BIGBALLON/distribuuuu/tree/master/tutorial
文中提到的框架见:
https://link.zhihu.com/?target=https%3A//github.com/BIGBALLON/distribuuuu
目录
0X01 分布式并行训练概述
0X02 Pytorch分布式数据并行
0X03 手把手渐进式实战
A. 单机单卡
B. 单机多卡DP
C. 多机多卡DDP
D. Launch / Slurm 调度方式
0X04 完整框架 Distribuuuu
0X05 Reference
7. 微信正在用的深度学习框架开源!支持稀疏张量,基于C++开发 | 量子位
项目地址:
https://github.com/Tencent/deepx_core
微信正用着的深度学习框架,现在你也可以上手试一试了。
就在最近,腾讯把这个名叫deepx_core的深度学习基础库正式对外开源。
相比于PyTorch、TensorFlow等流行深度学习框架,这位选手不仅具有通用性,还针对高维稀疏数据场景进行了深度优化。
也就是说,对于开发搜索、推荐、广告这样的深度学习应用,会更加友好易用。
简单介绍一下项目背后的开发团队。
deepx_core的开发者来自微信看一看算法平台团队。
据介绍,在正式开源之前,deepx系列机器学习项目已经在腾讯内部经过了3年多的迭代。
微信看一看、微信搜一搜、微信支付、微信表情、微信视频号、微信小程序、微信读书、QQ音乐、应用宝、腾讯新闻、腾讯课堂、腾讯黑产打击等排序/召回场景中,都已经有deepx_core及其衍生项目的落地。
8. 两万字总结《C++ Primer》要点 | Jacen的技术笔记
知乎:
https://zhuanlan.zhihu.com/p/343271809
对于想要入门C++的同学来说,
《C++ Primer》是一本不能错过的入门书籍,
它用平易近人的实例化教学激发学生的学习兴趣,
帮助学生一步步走进C++的大门。
在本文中,作者Jacen用两万多字总结了《C++ Primer 中文版(第五版)》1-16章的阅读要点,
可以作为该书的阅读参考。
注:原书更为详细,本文仅作学习交流使用。
从我开发的深度学习框架看深度学习这几年:TensorFlow, PaddlePaddle(飞桨), 无量
英特尔10nm至强CPU发布,对标AMD“米兰”EPYC,然而结果尴尬了
Keras将死于谷歌之手?reddit网友写“送葬文”,引发热议
消费级GPU、速度提升3000倍,微软FastNeRF首次实现200FPS高保真神经渲染
芯片行业110页深度报告:CPU研究框架 | 附完整报告下载
PyTorch 源码解读之即时编译篇
使用这个技术,ResNet-50最高可以获得16%的加速! | CVer
![]()
![]()
嵌入式代码质量与开发效率技术沙龙深圳、上海、北京三城巡回开始啦
RT-Thread联合鉴释科技分享双方在嵌入式软件领域多年积累的保证代码质量的一些经验和方法,助力小伙伴提升代码质量,欢迎小伙伴报名参加
议程
13:30——14:15
嵌入式软件持续集成与测试
演讲人:RT-Thread 技术工程师
14:15——15:00
嵌入式代码的典型漏洞分析和识别
演讲人:肖琳杰 鉴释资深技术工程师
15:00——15:45
提高嵌入式软件“调试”效率
演讲人:RT-Thread 技术工程师
15:45——16:30
WASM 安全性提高
演讲人:梁宇宁 鉴释联合创始人兼CEO

扫码报名
???????????? 点击阅读原文报名线下沙龙