pytoch加载模型最后一层(grad-cam)
一、grad-cam加载网络模型

可以通过model = models.mobilenet_v3_large(pretrained=True)直接加载网上的预训练模型,获取的模型具体信息如下:
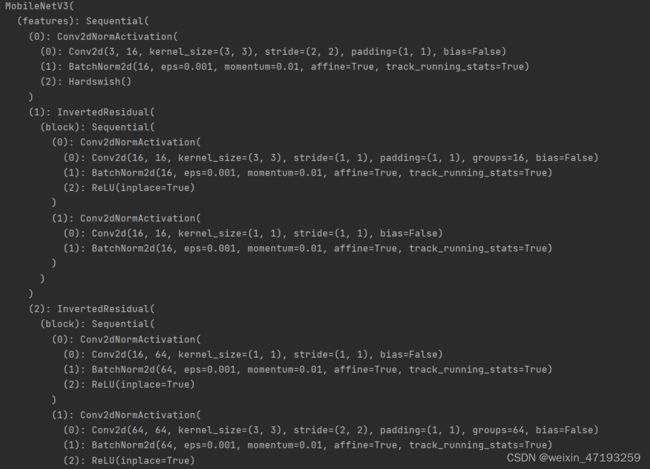
Mobilenet是继承来自nn.module类,包含了 backbone 和 classifier 两个由 Sequential 容器组成的 nn.Module 子类,backbone 和 classifier 各自又包含一些网络层,这些网络层也都属于 nn.Module 子类,所以从外到内共有三级
1、Mobilenet(nn.Module子类)
2、backbone 和 classifier(Sequential,nn.Module子类),是 Net 的子网络层
3、具体的网络层如 conv,relu,batchnorm 等(nn.Module子类),是 backbone 或 classifier 的子网络层
二、获取目标层语句
FasterRCNN: model.backbone
Resnet18 and 50: model.layer4[-1]
VGG and densenet161: model.features[-1]
mnasnet1_0: model.layers[-1]
ViT: model.blocks[-1].norm1
SwinT: model.layers[-1].blocks[-1].norm1
三、pytorch加载模型参数拓展
model的相关方法:
| 方法 | 返回类型 |
|---|---|
| modules() | generator(生成器) |
| named_modules() | generator |
| children() | generator |
| named_parameters() | generator |
| parameters() | generator |
| state_dict() | OrderedDict(有序字典) |
方法的返回值
| 方法 | 返回值 |
|---|---|
| modules() | 迭代遍历模型的 所有子层,子层是指继承了 nn.Module 类的层,遍历方式:深度优先 |
| named_modules() | 带有 layer name 的 model.modules(),也就是它在 model.modules() 的基础上,还返回这些 layer 的名字,返回的每个元素是一个 tuple,tuple 都一个元素是 layer 名称,第二个元素才是 layer 本身。除了在 model 定义时有明确命名的 backbone 和 classifier,其他 layer 都是按照 PyTorch 内部规则自动命名的。 |
| children() | 会遍历 model 的所有子层,也包括所有子层的子层。举个不严谨的例子,就是会遍历树形结构从 root 到 leaf 的所有节点。在上面的例子里,会遍历三级结构的每一个元素。 |
| name.children() | 只会获取model第二层网络结构,例如三层网络结构中只获取classifier和backbone,其中mobilenet和backbone、classifier的子层不获取。 |
| parameters() | 迭代地返回 模型所有可学习参数,有些 layer 不含有可学习参数(比如 relu、maxpool),因此 model.parameters() 不会输出这些层。 |
| named_parameters() | 带有 layer name 的 model.parameters(),每个 tuple 打包了两个元素,分别是 layer name 和 layer param。layer name 的后缀 .weight 和 .bias 用于区分权重和偏置。 |
| state_dict() | 能够获取 模型中的所有参数,包括可学习参数和不可学习参数,其返回值是一个有序字典 OrderedDict |
参考网址:https://yaoyz.blog.csdn.net/article/details/125065271?spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-5-125065271-blog-123571932.pc_relevant_multi_platform_whitelistv3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-5-125065271-blog-123571932.pc_relevant_multi_platform_whitelistv3&utm_relevant_index=6