视觉注意力机制在Non-local模块中的应用与表现

视觉注意力机制在Non-local模块中的应用与表现
- 写在文章开头
- 核心速览
- 可供拓展学习的一些相关工作
- 到底什么是Non-local
-
- 具体形式
- 模块化
- 后记
- 写在文章最后
写在文章开头
语义分割作为计算机视觉的典型任务,自然会与视觉注意力机制产生关系。我想通过Non-local模块来深入了解视觉注意力的前因后果,后续我也会学习记录一些相关的网络。今天就先沉下心来学习Non-local Neural Network吧,原论文在这里。另外,这篇文章也仅仅作为我的学习笔记,一些我已经明白的知识就不会过分纠结详述,因此文章知识体系可能显得不够系统。
核心速览
文中提出的Non-local模块是一种可用于各种计算机视觉任务的模块,它可以捕捉图像像素间的长距离依赖。此外,对于某一位置的响应,文中提出的Non-local是通过计算图像各个位置特征的加权和 所得到的,对于这一点,可参看Figure 1如下:

Non-local模块具备以下三种优势:
- 可计算表示任意(不受距离限制)两个位置之间的交互关系,从而直接捕获像素间的长距离依赖。
- Non-local在浅度网络(论文中称 甚至可以只有5层)中仍然有效。
- 可接受输入尺寸的变化,很容易与其他模块组件进行结合。
可供拓展学习的一些相关工作
- Non-local图像预处理模块。
- 图模型。包括了概率图模型(CRF)、图神经网络(GNN)等。
- 对语句、序列进行建模的Feedforward。
- 自注意力机制。作者的工作与机器翻译中的自注意力机制有一定关系。并且作者称,自注意力机制与可以看作Non-local操作的某种特殊形式,因此,作者的工作之一便是对自注意力机制进行泛化,将其从机器翻译拓展到更多应用领域。
- 交互网络。
- 视频分类。
到底什么是Non-local
作者首先给出了Non-local操作在深度神经网络中的广义定义,如下:
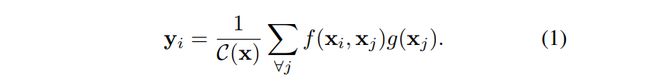
对于上式的符号定义如下:

需要注意的是,Non-local操作不像卷积操作和循环操作仅对输入的局部域进行相关计算,相反,它的计算是基于 “ all positions ( ∀ j ∀j ∀j) are considered in the operation. ” 这样一个事实。还有一点,则是与全连接层的不同。尽管全连接层的输出数据也带有权重,但是这些权重是经过训练后自带的,也就是说神经元对应的 x i x_i xi与 x j x_j xj之间的关系并不是全连接层对应的输入的某种函数,这一点在Non-local操作中是相反的。并且全连接层只接受固定尺寸的输入,而Non-local则可以接受任意大小的输入。
具体形式
式 ( 1 ) (1) (1)并没有具体给出函数 f f f和 g g g的表现形式,它们将在本节给出具体说明。 **有一点是Non-local极为强大的特性,那就是Non-local操作对函数 f f f和 g g g的选取其敏感度并不高,这一点在论文的实验部分给出了说明。
对于函数 g g g的选取,作者这样写明:

对于函数 f f f,则有许多形式,为了节省时间,我将全部以原论文的形式给出:



注意,在Embedded Gaussian的讨论中,作者说明了为什么自注意力机制是Non-local的某种特殊形式。此外,作者称,注意行为在他们的研究中显得并不是那么关键,为了说明这一点,作者又给出了Non-local的两种可选版本如下:


模块化
为了适应各种网络,Non-local被封装成一个模块。


到这里我们先缓一缓,Figure 2给出了Non-local模块的具体形式,对此我想说说自己对其的理解(不一定是正确的,仅供参考),顺带加深印象。我们首先来重新回顾函数 g g g的形式
g ( x j ) = W g x j g(x_j)=W_gx_j g(xj)=Wgxj其中的 W g W_g Wg是一个可以通过网络学习得到的权重矩阵,而下标 j j j代表(以图像为例)像素可能的空间位置,那么 x j x_j xj则表示输入图像 x x x在位置 j j j上对应的像素值。按原文来讲,整个 g g g函数的作用就是 “ computes a representation of the input signal at the position j j j ”。其实我不太理解 “ representation ” 的含义,我认为要理解这一点的话需要先全面地认识整个 g g g函数。要知道, x j x_j xj并不是一个完整的输入图像,相反,它只是一个像素点。那么我们为一个像素点施加一个矩阵有什么作用呢?按照 W g x j W_gx_j Wgxj的计算,我们将得到一个新的矩阵 Γ \Gamma Γ(即 g ( x j ) g(x_j) g(xj)),而矩阵 Γ \Gamma Γ中的每一个元素都是先前矩阵 W g W_g Wg的 x j x_j xj倍。这一操作就像我们把像素 x j x_j xj进行了展开平铺,或者叫放大,放大到多大呢?放大到矩阵 W g W_g Wg的大小。而放大后的像素,我们便用矩阵 Γ \Gamma Γ来表示。这样做有什么意义呢?我个人认为是这样的,我们知道像素点是一个零维的事物,我们可以说它不隐含任何空间信息(因为要有空间信息至少得是一维即向量)。所以,为了强行得到一个单独像素点的空间信息,我们使用矩阵 W g W_g Wg将其扩展到二维的矩阵 Γ \Gamma Γ,此时我们的目的就达到了。而回顾整个过程,我们是不是就像对一个像素点进行了某种表示呢?所以啊,作者所说的“ representation ”可能就是这个含义吧,同时,这也正式 g g g函数的含义。那么我们现在来看Figure 2 中输入 x x x(方便起见,我们把Figure 2 看作是计算机视觉领域Non-local,而不是Spacetime的,因此 x x x的维度分布为[Batch ,Width ,Height ,Channel])对应的 g g g函数模块,可以发现其对应的矩阵 W g W_g Wg就是一个1×1的卷积核。但是之前我们的输入不是是一个像素点吗,现在怎么变成了一张完整的图像,而且对应的矩阵为什么是1×1大小的?其实我是这样理解的(很可能错的,纯属想象以便于个人理解):对于输入图像 x x x,我们只看其中的一个像素点 p p p,当我们施加一个1×1的卷积时我们可以得到一个新的像素点 p 1 ^ \hat{p_1} p1^,而当我们继续对像素点 p p p施加1×1的卷积并且我们前后共施加filters次,我们把得到的filters个(假设filters=n n n)新像素组成的向量
{ p 1 ^ , p 2 ^ , p 3 ^ , . . . , p n ^ } \{\hat{p_1} , \hat{p_2} , \hat{p_3} , ...,\hat{p_n} \} {p1^,p2^,p3^,...,pn^}重新排列成W×H的格式,并且满足W×H=n,那么我们不就得到了一个新的矩阵 Γ \Gamma Γ了吗?而对应原来的矩阵 W g W_g Wg就是这n个卷积核排列成W×H的格式所形成的矩阵。这下便恍然大悟了对吧。接着,我们再来看Figure 2 中输入 x x x最左边的分枝,正如原文所说,这是一个基于ResNet的残差连接,对于残差连接的示意图我也在上面给出了。再接下来,就是Non-local最核心的部分,也就是Figure 2 中间的两条支路。
观察Figure 2中间的两条支路,这里的流程图实际上将Embedded Gaussian进行了拆分,先点积(Dot Product),再施加 e x e^{x} ex函数,最后再利用 C ( x ) C(x) C(x)进行归一化(后两个步骤在流程图中直接由softmax激活函数激活一步到位,它们是等价的)。同样的我们把Embedded Gaussian的表达式拿到这里来:
f ( x i , x j ) = e θ ( x i ) T ϕ ( x j ) f(x_i,x_j)=e^{\theta(x_i)^T\phi(x_j)} f(xi,xj)=eθ(xi)Tϕ(xj)其中, θ ( x i ) = W θ x i \theta(x_i)=W_{\theta}x_i θ(xi)=Wθxi, ϕ ( x j ) = W ϕ x j \phi(x_j)=W_{\phi}x_j ϕ(xj)=Wϕxj。到这里,对于 W ϕ W_{\phi} Wϕ和 W θ W_{\theta} Wθ为什么同样也是一个1×1的卷积核理解与前面的讨论一致。得到 θ \theta θ函数和 ϕ \phi ϕ函数输出(卷积)结果 x θ x_{\theta} xθ和 x ϕ x_{\phi} xϕ后,我们便来到了矩阵相乘结构 ⨂ \bigotimes ⨂。这时,我们首先得将得到的张量 x θ x_{\theta} xθ和 x ϕ x_{\phi} xϕ进行展平,即将维度分布由[Batch,Width,Height,Channel] “ 拉直 ” 为[ Batch×Width×Height , Channel ]得到 x θ ^ \hat{x_{\theta}} xθ^和 x ϕ ^ \hat{x_{\phi}} xϕ^。随后,我们再将 x ϕ ^ \hat{x_{\phi}} xϕ^进行矩阵转置([ Channel , Batch×Width×Height ]),使得二者满足矩阵相乘规则,这一点在流程图中也有体现。最后便通过 ⨂ \bigotimes ⨂运算符得到结果 x ^ \hat{x} x^。之后的过程我便不再描述,因为大致都是同样的道理。
总而言之,一批维度分布是[ Batch,Width,Height,Channel ]的图像张量经过Non-local模块后的输出结果其尺寸大小和维度分布都不变。
论文中,作者称Non-local模块是轻量的,流程图中的 H , W H,W H,W常取14或7。接下来,作者对Non-local模块做了进一步的优化,也即流程图中所表示的信息:作者将由 W g W_g Wg、 W θ W_{\theta} Wθ和 W ϕ W_{\phi} Wϕ所表示的通道数(看到这里,我发现我在上面的猜想与理解是正确的,因为作者的的确确是用通道维度来表示矩阵的)设置为输入图像的一半(也就是我们在流程图中所看到的从1024变到512)。作者称这样的设置方法对可以减少计算量。
进一步的,作者还引入了 “ subsampling trick ”来减少计算量。具体而言就是将
替换为
![]()
其中的 “ ^ \hat{} ^ ”标记代表经过池化处理。也就是说,作者在原来Non-local模块的基础上,在 g g g函数和 ϕ \phi ϕ函数后添置了池化层(具体来说是最大池化层)。为什么这样做呢,这样做有什么好处? “ can reduce the amount of pairwise computation by 1/4. ” “ This trick does not alter the non-local behavior, but only makes the computation sparser. ”。
后记
论文的其他部分是关于实验和Non-local在视频分类中的应用,这里我就不再说明了。直接给出Non-local模块在视频分类中的运行效果吧。

对于这幅图,有必要进行一些说明和理解。我们可以清楚的看到每组图都有许多起点相同的矢量,而这些矢量共同的起点代表的就是一个单独的像素 x i x_i xi,而所有这些矢量各自的终点指向的像素就是 x j x_j xj(对应权重最高的前20个像素)。也就是说,我们的神经网络最终找到了某个像素点和一些像素之间的关系。换句话说,经过训练,神经网络将对某一个像素点的思考集中在了某群像素点中,至于其他像素点,网络并不太关心。接下来,这种针对某群像素点的视觉注意力,则会用以辅助网络的预测。
这就是所谓的视觉注意力机制。
写在文章最后
本篇文章只是初步了解视觉注意力机制在Non-local模块中的体现,关于这种机制更多的思考我们还是得沉下心来从其一些应用中慢慢琢磨。所以接下来,我将学习语义分割领域中结合了视觉注意力机制的CCNet。