kMeans 聚类
kMeans 聚类
1.什么是聚类
监督式学习:训练集有明确答案,监督学习就是寻找问题(又称输入、特征、自变量)与答案(又称输出、目标、因变量)之间关系的学习方式。监督学习模型有两类,分类和回归。
• 分类模型:目标变量是离散的分类型变量;
• 回归模型:目标变量是连续性数值型变量。
无监督学习:只有数据,无明确答案,即训练集没有标签。常见的无监督学习算法有聚类(clustering),由计算机自己找出规律,把有相似属性的样本放在一组,每个组也称为簇(cluster)。
最早的聚类分析是在考古分类、昆虫分类研究中发展起来的,目的是找到隐藏于数据中客观存在的“自然小类”,“自然小类”具有类内结构相似、类间结构差异显著的特点,通过刻画“自然小类”可以发现数据中的规律、揭示数据的内在结构。
回归算法中超级典型的线性回归,分类算法中非常难懂的SVM,这两都是有监督学习中的模型,那今天就来看看无监督学习中最最基础的聚类算法——K-Means Cluster吧。
2.K-Means步骤
K-Means聚类步骤是一个循环迭代的算法,非常简单易懂:
1.假定我们要对N个样本观测做聚类,要求聚为K类,首先选择K个点作为初始中心点;
2.接下来,按照距离初始中心点最小的原则,把所有观测分到各中心点所在的类中;
3.每类中有若干个观测,计算K个类中所有样本点的均值,作为第二次迭代的K个中心点;
4.然后根据这个中心重复第2、3步,直到收敛(中心点不再改变或达到指定的迭代次数),聚类过程结束。
以二维平面中的点 ![]()
为例,用图片展示K=2时的迭代过程:
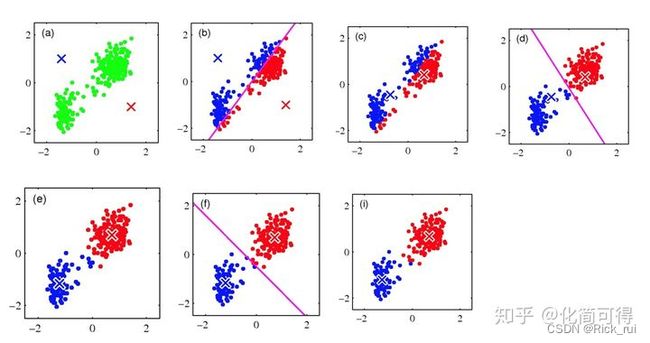
1.现在我们要将(a)图中的n个绿色点聚为2类,先随机选择蓝叉和红叉分别作为初始中心点;
2.分别计算所有点到初始蓝叉和初始红叉的距离,![]()
距离蓝叉更近就涂为蓝色,距离红叉更近就涂为红色,遍历所有点,直到全部都染色完成,如图(b);
3.现在我们不管初始蓝叉和初始红叉了,对于已染色的红色点计算其红色中心,蓝色点亦然,得到第二次迭代的中心,如图©;
4.重复第2、3步,直到收敛,聚类过程结束。
怎么样,很简单吧?看完K-Means算法步骤的文字描述,我们可能会有以下疑问:
1.第一步中的初始中心点怎么确定?随便选吗?不同的初始点得到的最终聚类结果也不同吗?
2.第二步中点之间的距离用什么来定义?
3.第三步中的所有点的均值(新的中心点)怎么算?
4.K怎么选择?
3.K-Means的数学描述
我们先解答第2个和第3个问题,其他两个问题放到后面小节中再说。
聚类是把相似的物体聚在一起,这个相似度(或称距离)是用什么来度量的呢?这又得提到我们的老朋友——欧氏距离。
给定两个样本 ![]()
与![]()
,其中n表示特征数 ,X和Y两个向量间的欧氏距离(Euclidean Distance)表示为:
![]()
k-means算法是把数据给分成不同的簇,目标是同一个簇中的差异小,不同簇之间的差异大,这个目标怎么用数学语言描述呢?我们一般用误差平方和作为目标函数(想想线性回归中说过的残差平方和、损失函数,是不是很相似),公式如下:
![[公式]](http://img.e-com-net.com/image/info8/e4358aab46d34aacabc95ec60cd22f19.jpg)
其中C表示聚类中心,如果x属于Ci这个簇,则计算两者的欧式距离,将所有样本点到其中心点距离算出来,并加总,就是k-means的目标函数。实现同一个簇中的样本差异小,就是最小化SSE。
可以通过求导来求函数的极值,我们对SSE求偏导看看能得到什么结果:
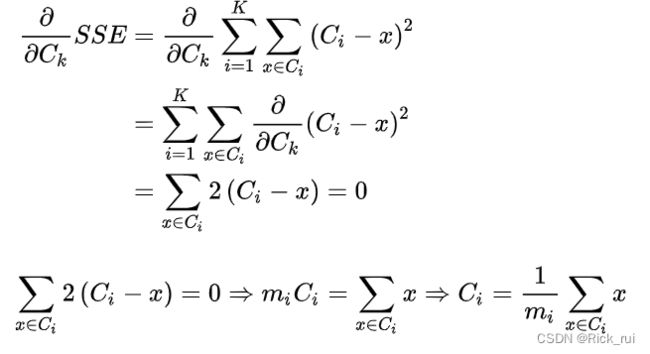
式中m是簇中点的数量,发现了没有,这个C的解,就是X的均值点。多点的均值点应该很好理解吧,给定一组点 X1,…,Xm,其中Xi=(xi1,xi2,…,xin) ,这组点的均值向量表示为:
![]()
4.初始中心点怎么确定
在k-means算法步骤中,有两个地方降低了SSE:
1.把样本点分到最近邻的簇中,这样会降低SSE的值;
2.重新优化聚类中心点,进一步的减小了SSE。
这样的重复迭代、不断优化,会找到局部最优解(局部最小的SSE),如果想要找到全局最优解需要找到合理的初始聚类中心。
那合理的初始中心怎么选?
方法有很多,譬如先随便选个点作为第1个初始中心C1,接下来计算所有样本点与C1的距离,距离最大的被选为下一个中心C2,直到选完K个中心。这个算法叫做K-Means++,可以理解为 K-Means的改进版,它可以能有效地解决初始中心的选取问题,但无法解决离群点问题。
我自己也想了一个方法,先找所有样本点的均值点,计算每个点与均值点的距离,选取最远的K个点作为K个初始中心。当然,如果样本中有离群点,这个方法也不佳。
总的来说,最好解决办法还是多尝试几次,即多设置几个不同的初始点,从中选最优,也就是具有最小SSE值的那组作为最终聚类。
5.K值怎么确定
要知道,K设置得越大,样本划分得就越细,每个簇的聚合程度就越高,误差平方和SSE自然就越小。所以不能单纯像选择初始点那样,用不同的K来做尝试,选择SSE最小的聚类结果对应的K值,因为这样选出来的肯定是你尝试的那些K值中最大的那个。
确定K值的一个主流方法叫“手肘法”。
如果我们拿到的样本,客观存在J个“自然小类”,这些真实存在的小类是隐藏于数据中的。三维以下的数据我们还能画图肉眼分辨一下J的大概数目,更高维的就不能直观地看到了,我们只能从一个比较小的K,譬如K=2开始尝试,去逼近这个真实值J。
1.当K小于样本真实簇数J时,K每增大一个单位,就会大幅增加每个簇的聚合程度,这时SSE的下降幅度会很大;
2.当K接近J时,再增加K所得到的聚合程度回报会迅速变小,SSE的下降幅度也会减小;
3.随着K的继续增大,SSE的变化会趋于平缓。
例如下图,真实的J我们事先不知道,那么从K=2开始尝试,发现K=3时,SSE大幅下降,K=4时,SSE下降幅度稍微小了点,K=5时,下降幅度急速缩水,再后面就越来越平缓。所以我们认为J应该为4,因此可以将K设定为4。
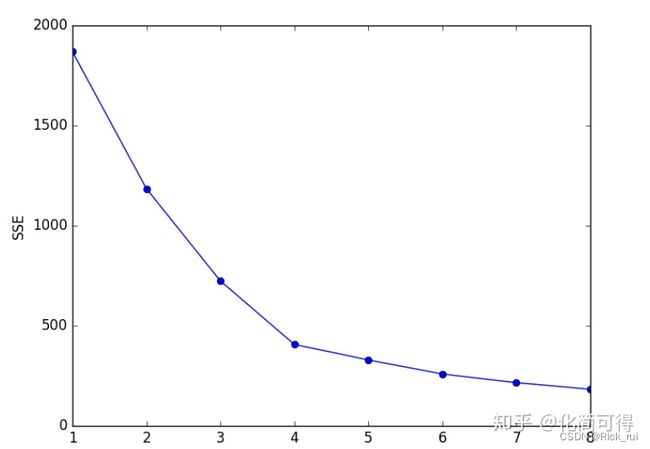
叫“手肘法”可以说很形象了,因为SSE和K的关系图就像是手肘的形状,而肘部对应的K值就被认为是数据的真实聚类数。
当然还有其他设定K值的方法,这里不赘述,总的来说还是要结合自身经验多做尝试,要知道没有一个方法是完美的。
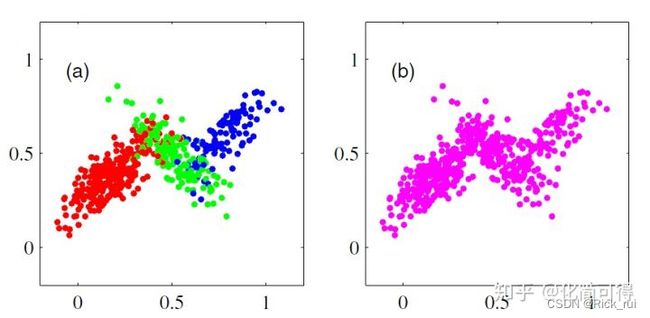
而且,聚类有时是比较主观的事,比如下面这组点,真实簇数J是几呢?我们既可以说J=3,也可以就把它分成2个簇。
6.小结
K-Means优点在于原理简单,容易实现,聚类效果好。
当然,也有一些缺点:
1.K值、初始点的选取不好确定;
2.得到的结果只是局部最优;
3.受离群值影响大。
完整代码:
package machinelearning.kmeans;
import java.io.FileReader;
import java.util.Arrays;
import java.util.Random;
import weka.core.Instances;
/**
* kMeans clustering.
* @author Rui Chen [email protected].
*/
public class KMeans {
/**
* Manhattan distance.
*/
public static final int MANHATTAN = 0;
/**
* Euclidean distance.
*/
public static final int EUCLIDEAN = 1;
/**
* The distance measure.
*/
public int distanceMeasure = EUCLIDEAN;
/**
* A random instance;
*/
public static final Random random = new Random();
/**
* The data.
*/
Instances dataset;
/**
* The number of clusters.
*/
int numClusters = 2;
/**
* The clusters.
*/
int[][] clusters;
/**
*******************************
* The first constructor.
*
* @param paraFilename
* The data filename.
*******************************
*/
public KMeans(String paraFilename) {
dataset = null;
try {
FileReader fileReader = new FileReader(paraFilename);
dataset = new Instances(fileReader);
fileReader.close();
} catch (Exception ee) {
System.out.println("Cannot read the file: " + paraFilename + "\r\n" + ee);
System.exit(0);
} // Of try
}// Of the first constructor
/**
*******************************
* A setter.
*******************************
*/
public void setNumClusters(int paraNumClusters) {
numClusters = paraNumClusters;
}// Of the setter
/**
*********************
* Get a random indices for data randomization.
*
* @param paraLength
* The length of the sequence.
* @return An array of indices, e.g., {4, 3, 1, 5, 0, 2} with length 6.
*********************
*/
public static int[] getRandomIndices(int paraLength) {
int[] resultIndices = new int[paraLength];
// Step 1. Initialize.
for (int i = 0; i < paraLength; i++) {
resultIndices[i] = i;
} // Of for i
// Step 2. Randomly swap.
int tempFirst, tempSecond, tempValue;
for (int i = 0; i < paraLength; i++) {
// Generate two random indices.
tempFirst = random.nextInt(paraLength);
tempSecond = random.nextInt(paraLength);
// Swap.
tempValue = resultIndices[tempFirst];
resultIndices[tempFirst] = resultIndices[tempSecond];
resultIndices[tempSecond] = tempValue;
} // Of for i
return resultIndices;
}// Of getRandomIndices
/**
*********************
* The distance between two instances.
*
* @param paraI
* The index of the first instance.
* @param paraArray
* The array representing a point in the space.
* @return The distance.
*********************
*/
public double distance(int paraI, double[] paraArray) {
int resultDistance = 0;
double tempDifference;
switch (distanceMeasure) {
case MANHATTAN:
for (int i = 0; i < dataset.numAttributes() - 1; i++) {
tempDifference = dataset.instance(paraI).value(i) - paraArray[i];
if (tempDifference < 0) {
resultDistance -= tempDifference;
} else {
resultDistance += tempDifference;
} // Of if
} // Of for i
break;
case EUCLIDEAN:
for (int i = 0; i < dataset.numAttributes() - 1; i++) {
tempDifference = dataset.instance(paraI).value(i) - paraArray[i];
resultDistance += tempDifference * tempDifference;
} // Of for i
break;
default:
System.out.println("Unsupported distance measure: " + distanceMeasure);
}// Of switch
return resultDistance;
}// Of distance
/**
*******************************
* Clustering.
*******************************
*/
public void clustering() {
int[] tempOldClusterArray = new int[dataset.numInstances()];
tempOldClusterArray[0] = -1;
int[] tempClusterArray = new int[dataset.numInstances()];
Arrays.fill(tempClusterArray, 0);
double[][] tempCenters = new double[numClusters][dataset.numAttributes() - 1];
// Step 1. Initialize centers.
int[] tempRandomOrders = getRandomIndices(dataset.numInstances());
for (int i = 0; i < numClusters; i++) {
for (int j = 0; j < tempCenters[0].length; j++) {
tempCenters[i][j] = dataset.instance(tempRandomOrders[i]).value(j);
} // Of for j
} // Of for i
int[] tempClusterLengths = null;
while (!Arrays.equals(tempOldClusterArray, tempClusterArray)) {
System.out.println("New loop ...");
tempOldClusterArray = tempClusterArray;
tempClusterArray = new int[dataset.numInstances()];
// Step 2.1 Minimization. Assign cluster to each instance.
int tempNearestCenter;
double tempNearestDistance;
double tempDistance;
for (int i = 0; i < dataset.numInstances(); i++) {
tempNearestCenter = -1;
tempNearestDistance = Double.MAX_VALUE;
for (int j = 0; j < numClusters; j++) {
tempDistance = distance(i, tempCenters[j]);
if (tempNearestDistance > tempDistance) {
tempNearestDistance = tempDistance;
tempNearestCenter = j;
} // Of if
} // Of for j
tempClusterArray[i] = tempNearestCenter;
} // Of for i
// Step 2.2 Mean. Find new centers.
tempClusterLengths = new int[numClusters];
Arrays.fill(tempClusterLengths, 0);
double[][] tempNewCenters = new double[numClusters][dataset.numAttributes() - 1];
// Arrays.fill(tempNewCenters, 0);
for (int i = 0; i < dataset.numInstances(); i++) {
for (int j = 0; j < tempNewCenters[0].length; j++) {
tempNewCenters[tempClusterArray[i]][j] += dataset.instance(i).value(j);
} // Of for j
tempClusterLengths[tempClusterArray[i]]++;
} // Of for i
// Step 2.3 Now average
for (int i = 0; i < tempNewCenters.length; i++) {
for (int j = 0; j < tempNewCenters[0].length; j++) {
tempNewCenters[i][j] /= tempClusterLengths[i];
} // Of for j
} // Of for i
System.out.println("Now the new centers are: " + Arrays.deepToString(tempNewCenters));
tempCenters = tempNewCenters;
} // Of while
// Step 3. Form clusters.
clusters = new int[numClusters][];
int[] tempCounters = new int[numClusters];
for (int i = 0; i < numClusters; i++) {
clusters[i] = new int[tempClusterLengths[i]];
} // Of for i
for (int i = 0; i < tempClusterArray.length; i++) {
clusters[tempClusterArray[i]][tempCounters[tempClusterArray[i]]] = i;
tempCounters[tempClusterArray[i]]++;
} // Of for i
System.out.println("The clusters are: " + Arrays.deepToString(clusters));
}// Of clustering
/**
*******************************
* Clustering.
*******************************
*/
public static void testClustering() {
KMeans tempKMeans = new KMeans("D:/data/iris.arff");
tempKMeans.setNumClusters(3);
tempKMeans.clustering();
}// Of testClustering
/**
*************************
* A testing method.
*************************
*/
public static void main(String arags[]) {
testClustering();
}// Of main
}// Of class KMeans