P-MVSNet
P-MVSNet: Learning Patch-wise Matching Confidence Aggregation for Multi-View Stereo
摘要
基于平面扫描算法构建代价体的方法运用很广泛,但平面扫描体(plane sweeping volume)在深度和空间方向是各向异性的,但在构建代价体是基本上采用的都是各向同性的方法来近似替代。因此本文提出了一种基于各向同性和各向异性的端到端的深度学习网络P-MVSNet。
创新点
- 提出了一种基于块的匹配置信度聚合模块来构建匹配代价量,该模型对噪声数据具有较强的鲁棒性和准确性。
- 设计了一种混合的3D U-Net网络从匹配置信度中推断出潜在概率量,并估计深度图。
- 提出了深度置信度和深度一致性准则,用于深度图的过滤和融合。
引言
MVS是从已知相机参数的图像合集中,恢复图像场景稠密表示。可分为基于体素和基于深度图两种方案。目前主流的基于深度学习的MVS,其构建代价体的方式都是从输入图像中,通过平面扫描算法在参考相机视锥空间构建代价体,然后每个深度采样假设下计算参考图像中的像素与其他相邻图像中对应的像素之间的匹配代价,一般是采取方差度量。
缺陷:当源图像中由两个特征非常相似,但却和参考图像中的特征匹配,此时的匹配代价值也会很低,这对最后预测的深度图可能会带来影响。
文中解决方案:加强参考图像的重要性,而不是每张图像平等的参与计算。
相关工作
常规的MVS
- 基于patch:将整个场景视为空间内patch的集合,首先重建纹理丰富的patch,然后将其传播到低纹理区域用于稠密重建。
- 基于可变变形多边形网格:需要良好的场景表面初始猜测来初始化曲面演化,然后迭代地提高多视点光度一致性。
- 基于体素:首先计算包含场景的边界框并将其划分为体素网格,然后提取附着在场景表面的体素。
- 基于深度图:估计出场景的深度图,估计单个图像的深度图,然后将所有深度图合并成一致的点云。
网络结构
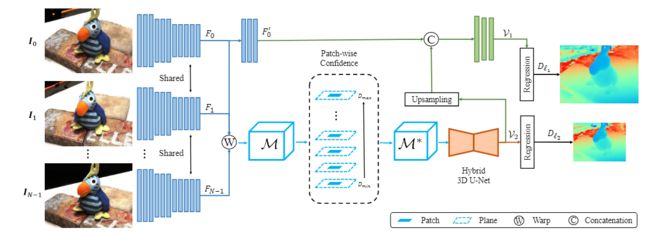
包含四个模块
- 权重共享图像特征提取器
- patch-wise 匹配置信聚合模块
- 混合 3D U-Net 的深度图推理网络
- 深度图优化网络
1.特征提取
提取N张输入图像的特征
。
采用编解码结构,输入和MVSNet一样1张参考图像,N-1张源图像
![[Pasted image 20221113092720.png]]
编码部分由11层二维卷积构成,输出为图像的二级特征映射 F i F_i Fi( l 2 l2 l2)。
解码部分由3个二维卷积构成,为参考图像生成特征图 F 0 ′ F'_0 F0′记作( l 1 l1 l1)。
l 2 l2 l2用来在低分辨率构建匹配置信度,大小为原图的1/4。
l 1 l1 l1用作高边分辨率下的深度估计,大小为原图的1/2。
2.学习Patch-wise匹配置信度
由 l 2 l2 l2特征图结合摄像机参数,用平面扫描算法构建Pixel-wise匹配置信度 (MCV),在把Pixel-wise MVC聚合为Patch-wise MVC。
Pixel-wise MVC定义为 M = ( d , p , c ) \mathcal{M}=(d,p,c) M=(d,p,c)
表示为参考图像像素p,在深度值为d的深度层与源图像特征图相对应的像素点之间的第C个特征通道的匹配置信度。
p ′ p' p′是p在相邻特征图 F j F_j Fj中的对应像素, F j ( p ′ , c ) F_j(p',c) Fj(p′,c)由双线性差值计算
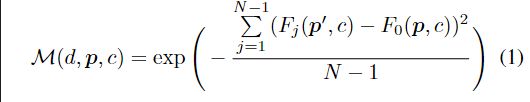
对每个深度假设平面进行Patch-wise聚合 M ∗ = M ∗ ( d , p , c ) \mathcal{M}^*=\mathcal{M}^*(d,p,c) M∗=M∗(d,p,c):
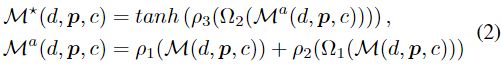
Ω 1 ( ⋅ ) \Omega_1(·) Ω1(⋅):深度假设平面上,以p为中心3×3 patch ω 1 \omega_1 ω1。
Ω 2 ( ⋅ ) \Omega_2(·) Ω2(⋅):沿着深度方向以P为中心的3个相邻patch的集合
ρ 1 , ρ 2 , ρ 3 \rho_1,\rho_2,\rho_3 ρ1,ρ2,ρ3是考虑多通道特征匹配置信度的可学习函数。
ρ 1 \rho_1 ρ1:1×1×1+BN层+ReLU层,只关注p的多通道匹配置信度聚合
ρ 2 \rho_2 ρ2:1×3×3+BN层+ReLU层,融合 ω 1 \omega_1 ω1中相邻像素匹配信息
ρ 3 \rho_3 ρ3:3×3×3+BN层,聚合多个patch之间的匹配置信度
t a n h ( ⋅ ) tanh(·) tanh(⋅):激活函数
4.深度图估计
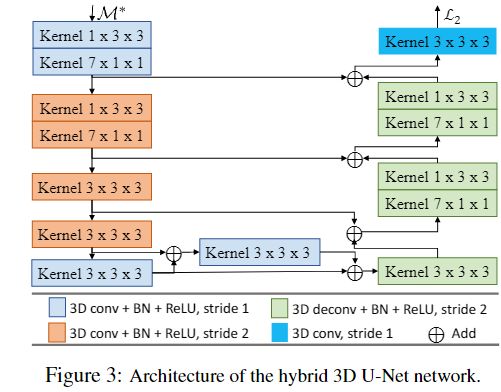
M ∗ \mathcal{M}^* M∗经过混合3D-UNet网络计算,得到潜在概率体(Lpv-latent probability volume),表示为 V 2 = V 2 ( d , p ) \mathcal{V}_2=\mathcal{V}_2(d,p) V2=V2(d,p),表示参考图像沿深度方向每个像素的潜在概率分布,维度为[Z,H/4,W/4]。
混合3D UNet网络由多个各向同性和各向异性的3D卷积层组成。
浅层:两种各向异性卷积
1×3×3,融合每个深度假设平面的信息
7×1×1,用相对较低的计算,沿着深度方向扩大感受野,来获取全局信息
深层:各向同性卷积
3×3×3,融合上下文信息
得到Lpv后,将Lpv转变为概率体(pv) P 2 \mathcal{P}_2 P2。和MVSNet一样,深度图 D l 2 D_{\mathcal{l}2} Dl2中的像素点p的预测深度值,是该点在源图像特征图对应点的所有深度d和概率 p p p的加权和。

D l 2 D_{\mathcal{l}2} Dl2的深度图分辨率较低,通过 l 1 l1 l1来优化所得深度图,生成更高分辨率的深度图。
深度图滤波
引入两个准则来过滤预测深度中的误差值。
深度置信度准则,用于去除明显不可靠的预测;
深度一致性准则,用于丢弃相邻图像中不一致的深度值
深度置信度准则:将 D l 2 D_{\mathcal{l}2} Dl2的深度图转换为置信度图,经过 l 1 l1 l1优化后,所得置信度图进行滤波,低于某个阈值的点舍去。
深度一致性准则:对参考图像中的像素点p进行深度估计得到深度值 d ^ ( p ) \hat{d}(p) d^(p),将p点反投影到邻域的深度图中得到点q’,若投影点p’满足 ∣ q ′ − p ∣ < ϵ |q'-p|<\epsilon ∣q′−p∣<ϵ, ∣ d ^ ( q ′ ) − d ^ ( p ) ∣ / d ^ ( p ) < η |\hat{d}(q')-\hat{d}(p)|/\hat{d}(p)<\eta ∣d^(q′)−d^(p)∣/d^(p)<η则表示该点的预测深度是一致的。

损失函数
采用回归的思想预测深度图
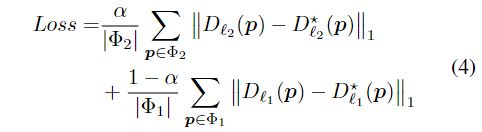
实验结果
