R-MVSNet学习笔记
Recurrent MVSNet for High-resolution Multi-view Stereo Depth Inference
摘要
基于深度学习的MVS存在的缺陷:
代价体正则化消耗的内存巨大,使MVS难以运用高分辨率场景
创新
提出了使用循环神经网络正则化方案,将原来的一次性正则化整个3D代价体的方案,改为了通过GRU模块沿着深度划分方向顺序的正则化2D的代价图,极大的减少了内存的消耗,使得基于深度学习的MVS网络能够应用在高分辨率场景。
引言
MVS的目的是通过给定的物体的多视图图像和标定的相机,恢复物体的三维稠密点云表示。
- MVSNet,SurfcaeNet等通过多尺度的3DCNN去正则化3D代价体,内存需求随着模型分辨率呈立方增长。
- OtNet、O-CNN将八叉树结构引入3DCNN;SurfaceNet、DeepMVS采用分治策略,MVSNet将重建解耦为每个视图的深度图问题。
针对代价体正则化,目前采用的方案有如下几种:
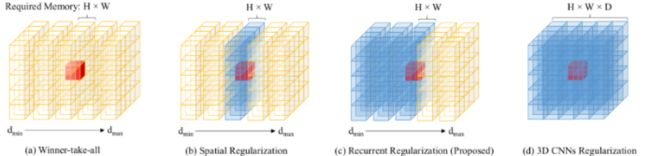
- Winner-take-all(赢家通吃):将这个深度平面最好的值直接替换为该点的深度值,简单但是受到噪声的影响较大。
- Spatial Regularizationg(空间正则化):在不同的深度平面层对代价体进行处理,能够获取该深度层的空间信息,但无法感知不同深度层的信息。
- Recurrent Regularizationg(循环正则化):利用循环神经网络的GRU单元对代价体进行正则化,既能获取该深度层的空间信息,利用GRU单元聚集深度方向上的时间上下文信息。
- 3D CNNs Regularizationg:一次性正则化整个代价体,内存消耗巨大。
网络结构
R-MVSNet的网络借鉴了MVSNet网络,其具体重建的流程可分为
- 特征提取
- 代价正则化
- 深度图优化
- 后处理
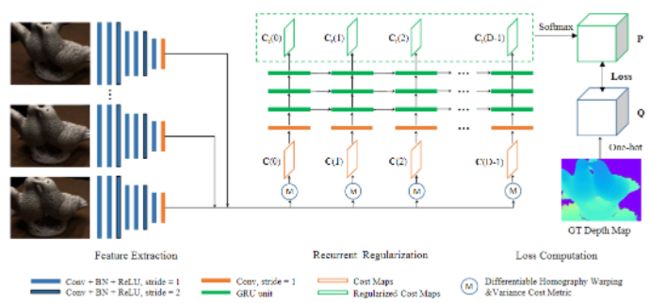
1. 特征提取
R-MVSNet的特征提取与MVSNet一样。
提取N个输入图像 { I i } ( i = 1 ) N \{I_i\}_{(i=1)}^N {Ii}(i=1)N的特征 { F i } i = 1 N \{F_i\}^N_{i=1} {Fi}i=1N。通过一个八层的2DCNN卷积网络,将第三层、第六层的步长设置为2,将特征塔分为3层,将特征进行下采样,由输入的H × \times ×W,变为32通道的 H 4 × W 4 {\frac{H}{4}}\times{\frac{W}{4}} 4H×4W,所有的领域信息都被编码到32通道的像素描述符中,有效的保证上下文信息。
特征提取结束后,源图像(source image)特征图 { F i } ( i = 2 ) N \{F_i\}_{(i=2)}^N {Fi}(i=2)N通过单应性变换(Differentiable Homography)warp到参考图相机平面空间的划分的深度层上,N-1张warp操作后的特征图+一张参考图像所得的特征图,在参考相机视锥空间得到了一个特征体(feature volume) { V i } ( i = 1 ) N {\{V_i\}_{(i=1)}^N} {Vi}(i=1)N。
深度层的范围划分 [ d m i n , d m a x ] [d_{min},d_{max}] [dmin,dmax]由CLOMAP得到的稀疏点云确定。
(参考论文:Pixelwise View Selection for Unstructured Multi-View Stereo)
深度采样个数D由公式:
d ( i ) = ( ( 1 d m i n − 1 d m a x ) i D − 1 + 1 d m a x ) − 1 d(i)={(({\cfrac {1}{d_{min}}- {\cfrac {1}{d_{max}}}}) {\cfrac {i}{D-1}}+\cfrac {1}{d_{max}})^{-1}} d(i)=((dmin1−dmax1)D−1i+dmax1)−1D = ( 1 d m i n − 1 d m a x ) / ( 1 d m i n − 1 d m a x + ρ ) D=({\cfrac {1}{d_{min}}}-{\cfrac {1}{d_{max}}})/({\cfrac {1}{d_{min}}}-{\cfrac {1}{d_{max}+{\rho}}}) D=(dmin1−dmax1)/(dmin1−dmax+ρ1)
其中 i i i为层数标记,D为深度采样数即深度范围分为多少个深度层, ρ \rho ρ为空间图像分辨率。
2.正则化
与MVSNet不同,RMVSNet采用顺序处理代价体的思想,提出了基于卷积GRU的循环正则化方案。
将代价体C看作是在深度方向上连接的D个代价图(cost maps) { C ( i ) } i = 1 D {\lbrace C(i)\rbrace}_{i=1}^{D} {C(i)}i=1D,经过正则化后的代价图输出表示为 { C r ( i ) } i = 1 D {\lbrace C_r(i)\rbrace}_{i=1}^{D} {Cr(i)}i=1D,对于理想的正则化来说,第t步的正则化后输出的代价图 C r ( t ) C_r(t) Cr(t)应依赖于 C ( t ) C(t) C(t)和前面所有的代价图即 { C ( i ) } i = 1 t − 1 {\lbrace C(i)\rbrace}_{i=1}^{t-1} {C(i)}i=1t−1
![]()
⨀ \bigodot ⨀表示矩阵对应位置元素进行乘积
U ( t ) U(t) U(t) 是更新门图,用于决定是否更新当前步骤的输出,即决定着当前输入 C u ( t ) C_u(t) Cu(t)中哪些值会被保留,而上一个状态中哪些值会被抛弃
![]()
- [ . . . ] [... ] [...]concatenation,表示将新向量拼接到原来的向量之后,对应着维数增加.
- ' ∗ \ * ∗'表示卷积运算
- R ( t ) R(t) R(t)是重置门图,用于决定之前的 C r ( t − 1 ) C_r(t - 1) Cr(t−1)哪些值被重置且和当前输入 C ( t ) C(t) C(t)相衔接组成新的输入。
- σ c \sigma_c σc表示非线性映射

W,b都是可训练参数。通过大量的数据学习出针对不同的空间和深度信息如何抛弃和保留信息。
σ g ( ⋅ ) \sigma_g(·) σg(⋅)是为更新做出软决策的双曲正切
软决策:解调器不采用判决门限来将信号波形直接判决成0或者1,而是向译码器输出一种可能性
文中采用了三层堆叠的GRU模块,首先运用2D卷积将32通道的代价图 C ( t ) C(t) C(t)映射到16通道,作为第一层的输入。每层GRU的输出都作为下一个GRU单元的输入,3层的输出通道分别为16、4、1。最终得到的代价图经过一个softmax层生成概率体P用于损失计算。
3.深度图优化
为了达到亚像素精度的深度图,提出了变分深度图细化的方案。为了实现测试,采用winner-take-all从正则化的代价图中顺序的检索深度图。
为了减轻阶梯效应,通过加强多视角照片的一致性来细化深度范围内的深度图。具体来说,在得到正则化的深度图D1后,以D1为参考将源图像投影到参考图像坐标系下,计算重投影图像与参考图像的误差:
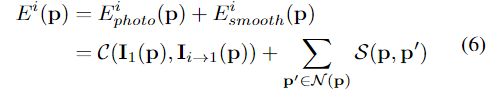
E p h o t o i E_{photo}^{i} Ephotoi为光度误差
E s m o o t h i E_{smooth}^{i} Esmoothi为平滑度误差
C ( ⋅ ) C(·) C(⋅)为光度一致性,使用==零均值互相关(ZNCC)==来计算
两个向量之间夹角的余玄值,即两向量之间的交角为0即余弦值为1时即两向量更一致,反之更不相关
通过P与其邻域p‘的深度平方差来计算平滑度 S ( ⋅ ) S(·) S(⋅)。
4.后处理
深度图滤波
利用光度一致性和几何一致性,过滤掉背景和遮挡区域中的异常值
利用光度一致性,在概率图估计深度图中,对概率小于0.8的值,视为异常值。
利用几何一致性,测量多个视图之间的深度一致性。类似于立体匹配中的视差约束。
点云融合
将不同视点的深度图融合到统一的点云表示中,使用基于可见性的融合算法,把遮挡,光照等影响降到了最低,使得不同视点之间的深度遮挡和冲突最小化。
为了进一步抑制重建噪声,在滤波步骤中确定每个像素的可见视图,并将所有重投影深度的平均值作为像素的最终深度估计。
融合后的深度图直接投影到空间,生成三维点云
5.损失函数
与MVSNet不同,RMVSNet采用的方式是类分类问题的方案。
大多数深度立体和MVS网络使用的是soft Argmin操作来回归深度图或视差图,即沿着深度方向的期望值。但此类方案仅仅适用于深度值在深度范围内均匀采样。
RMVS采用交叉熵损失函数,将问题视作是类分类问题
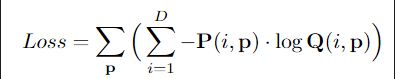
p为空间图像坐标, P ( i , p ) P(i,p) P(i,p)是概率体P中的一个体素,Q为地面真值深度图在经过独热编码后的二进制表示, Q ( i , p ) Q(i,p) Q(i,p)是 P ( i , p ) P(i,p) P(i,p)对应的体素。
6.结果(仅关注DTU数据集)
定量分析
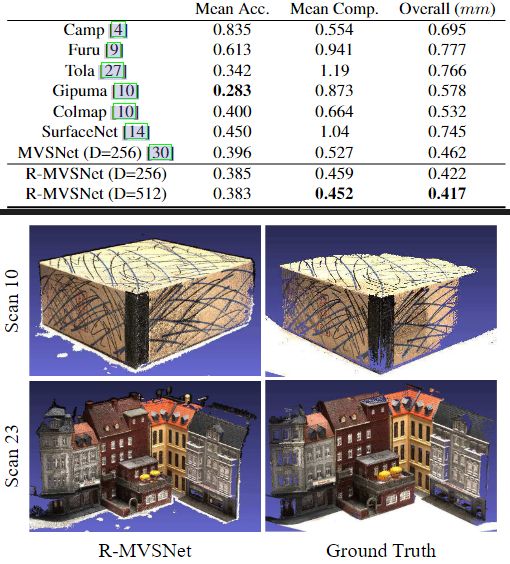
消融实验结果
网络架构
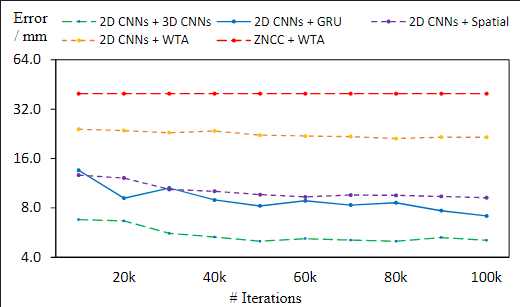
后处理
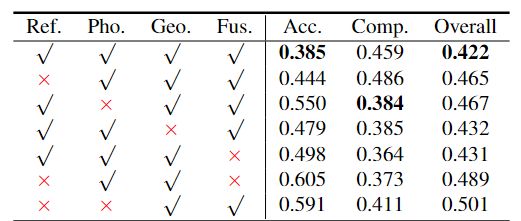
不同正则化方案的实验结果
