MARL算法笔记:COMA
COMA
Counterfactual Multi-Agent Policy Gradients
keywords: Multi-agent AC method; 用counterfactual baseline解决信用度分配问题
1.方法总结:
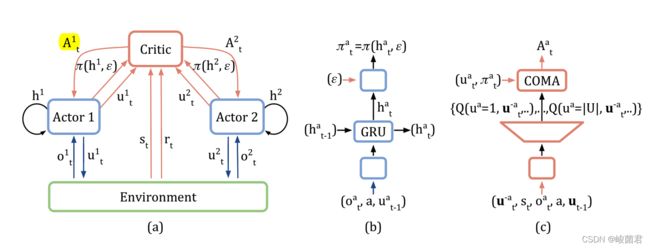
IAC框架+一个优势函数+一个trick
-
先学习 Q ( s , u ) Q(s,u) Q(s,u), s s s是全局 s t a t e state state, u u u是联合动作
-
counterfactual baseline方法
A a ( s , u ) = Q ( s , u ) − ∑ u ′ a π a ( u ′ a ∣ τ a ) Q ( s , ( u − a , u ′ a ) ) A^a(s,u) = Q(s,u) - \sum_{{u'}^{a}}\pi^a({u'}^a|\tau^a)Q(s,({u}^{-a},{u'}^a)) Aa(s,u)=Q(s,u)−u′a∑πa(u′a∣τa)Q(s,(u−a,u′a))第一项表示:其他人不动,我现在这个动作有多好 第二项表示:其他人不动,我平均动作来看有多好。counterfactual baseline -
一个trick:用efficient way来计算 Q ( s , ( u − a , u ′ a ) ) Q(s,({u}^{-a},{u'}^a)) Q(s,(u−a,u′a))

4. 用 A a ( s , u ) A^a(s,u) Aa(s,u)来更新每个agent:
θ = θ + α ∇ θ l o g π θ A a ( s , u ) \theta=\theta+\alpha\nabla_{\theta}log\pi_{\theta}A^a(s,u) θ=θ+α∇θlogπθAa(s,u)
2.学习思路
1.更好的Actor需要更好的优势函数
在单智能体agent的AC算法和REINFORCE算法中,最后到底想要什么?
“The critic is used only during learning and only the actor is needed during execution”
答案是:我们最后的一切目的是得到Actor: π ( a ∣ s ) \pi(a|s) π(a∣s)
在AC中,我们使用Critic来更好的更新Actor:
θ = θ + α ∇ θ l o g π θ Q w ( s , a ) (1) \theta=\theta+\alpha\nabla_{\theta}log\pi_{\theta}Q_w(s,a)\tag1 θ=θ+α∇θlogπθQw(s,a)(1)
为了获得更好的Actor,当然我们也要更好的 Q w ( s , a ) Q_w(s,a) Qw(s,a),COMA也就是在这个 Q w ( s , a ) Q_w(s,a) Qw(s,a)上做的文章,用了更好的优势函数将其代替。
2.IAC中优势函数不是足够好
具体过程
按照定义,多智能体的Independent Actor Critic中,每个agent把除自己外的其他agent和环境统一视作环境,然后把自己看做一个单智能体,不断用AC算法,维护自己的Q和Actor。
而AC算法的流程是,agent进行一步step,然后获得reward,下一个状态,以及下一个状态的动作,然后更新两个参数的网络, w w w和 θ \theta θ,并不断循环。
缺点:
- 不稳定。作为一个单智能体,其在同样的观测下做出同样的动作,reward很可能不一样。
Trick:
- 简化处理:所有agent共用一套网络参数: A c t o r Actor Actor& C r i t i c Critic Critic
- 可以使用两种变体(优势函数):
θ = θ + α ∇ θ l o g π θ A π θ ( o , a ) ; A π θ ( o , a ) = Q ( o , a ) − V ( o ) (2) \theta=\theta+\alpha\nabla_{\theta}log\pi_{\theta}A^{\pi_\theta}(o,a); A^{\pi_{\theta}}(o,a) = Q(o,a) - V(o)\tag2 θ=θ+α∇θlogπθAπθ(o,a);Aπθ(o,a)=Q(o,a)−V(o)(2)
θ = θ + α ∇ θ l o g π θ T D e r r o r ; T D e r r o r = r + V ( o t + 1 ) − V ( o t ) (3) \theta=\theta+\alpha\nabla_{\theta}log\pi_{\theta}TD_{error};TD_{error} = r+V(o_{t+1}) - V(o_t)\tag 3 θ=θ+α∇θlogπθTDerror;TDerror=r+V(ot+1)−V(ot)(3)
插曲:一个问题
Q: 在IAC中,每个单智能体,它的奖励是多少?因为奖励是环境给的,而环境给的时候是根据全局状态和全局动作给,你只给我一个单智能体的action,环境是不会给你你单独这个action的奖励的。换句话说,如果环境能很合理地根据单智能体的action给出合理的评价与奖励,那就没有后话了。
A: 而在星际争霸环境下,代码表示,当使用IAC的时候,每个单智能体的奖励是共享全局奖励的。例:三个agent的动作为actions = (上,下,开枪),代码执行r = env.step(actons),此时这个r就是一个具体的数,可能是0.8。这个时候这三个agent的reward都是0.8;当然,如果环境本身能够很好的给每个单智能体一个reward,也很好。
3.COMA里的优势函数更好
设计好的优势函数,可以带来好的Actor更新
IAC中,每个agent的 Q ( o a , u a ) Q(o^a,u^a) Q(oa,ua)都是用全局r不断更新的,然后再按照这个 Q ( o a , u a ) Q(o^a,u^a ) Q(oa,ua)来更新Actor。所以我们如果想让Actor的参数按照好的梯度更新,就要拿一个好的 Q ( o a , u a ) Q(o^a,u^a) Q(oa,ua)来更新Actor
这个 Q ( o a , u a ) Q(o^a,u^a ) Q(oa,ua)的作用,相当于评价agent在他的观测下的动作的好坏,这个评价越准,Actor网络更新得越好,越快。
在多智能体环境下,一个好的优势函数一定是用到全局state的。上帝视角评估一个agent的动作肯定比在它单独视角评估更加准确。
在COMA之前,一些优势函数的设计
第一种优势函数
θ = θ + α ∇ θ l o g π θ T D e r r o r ; T D e r r o r = r + V ( s t + 1 ) − V ( s t ) \theta=\theta+\alpha\nabla_{\theta}log\pi_{\theta}TD_{error};TD_{error} = r+V(s_{t+1}) - V(s_t) θ=θ+α∇θlogπθTDerror;TDerror=r+V(st+1)−V(st)
算法维护的网络就是 V ( s t ) V(s_t) V(st)和N个agents的Actor网络。
缺点:没有解决信用度分配问题
第二种优势函数
D a = r ( s , u ) − r ( s , ( u − a , c a ) ) D^a=r(s,u) - r(s,(u^{-a},c^a)) Da=r(s,u)−r(s,(u−a,ca))
其中 c a c^a ca表示智能体 a a a的默认动作, s s s表示全局state
这个优势函数评价的就是,在其他智能体动作不变的时候, u a u^a ua比 c a c^a ca好多少
缺点:
- 需要模拟器,计算 r ( s , ( u − a , c a ) ) r(s,(u^{-a},c^a)) r(s,(u−a,ca))
- 需要设计 c a c^a ca,哪个算默认动作?
COMA设计了一个更好的优势函数
A a ( s , u ) = Q ( s , u ) − ∑ u ′ a π a ( u ′ a ∣ τ a ) Q ( s , ( u − a , u ′ a ) ) A^a(s,u) = Q(s,u) - \sum_{{u'}^{a}}\pi^a({u'}^a|\tau^a)Q(s,({u}^{-a},{u'}^a)) Aa(s,u)=Q(s,u)−u′a∑πa(u′a∣τa)Q(s,(u−a,u′a))
其中 s s s表示全局state, u a u^a ua表示第 a a a个智能体的动作
Q ( s , u ) Q(s,u) Q(s,u):在其他agents动作不变的情况下,第 a a a个智能体的动作评价
∑ u ′ a π a ( u ′ a ∣ τ a ) Q ( s , ( u − a , u ′ a ) ) \sum_{{u'}^{a}}\pi^a({u'}^a|\tau^a)Q(s,({u}^{-a},{u'}^a)) ∑u′aπa(u′a∣τa)Q(s,(u−a,u′a)): 在其他agents动作不变的情况下,第a个智能体的平均动作评价,也叫counterfactual baseline
所以 A a ( s , u ) A^a(s,u) Aa(s,u)评价的就是,第 a a a个智能体采取这样的动作的时候,比平均来看好了多少。
好处:
- 不需要模拟器单独算 Q ( s , ( u − a , u ′ a ) Q(s,({u}^{-a},{u'}^a) Q(s,(u−a,u′a)
- 不需要设计默认动作
COMA中用了一个trick
观察 Q ( s , u ) Q(s,u) Q(s,u),两个输入变量都是全局的所以输出大小是 ∣ U ∣ n |U|^n ∣U∣n,指数爆炸。比如我有3个智能体,每个智能体动作有5个,这个 Q ( s , u ) Q(s,u) Q(s,u)输出节点就得有125个。网络太难训了orz
所以COMA做出了如下的改变:

输入由 S S S变成了 S + U − a S+U^{-a} S+U−a,保证输出大小只有 ∣ U ∣ |U| ∣U∣这么大.