Windows下配置yolov5环境(显卡RTX NVIDIA3070TI)
NVIDIA显卡:是一款硬件板子,主流是NVIDIA的GPU,深度学习本身需要大量计算。GPU的并行计算能力,在过去几年里恰当地满足了深度学习的需求。
显卡驱动:告诉计算机识别显卡硬件,调用其计算资源。
CUDA:是NVIDIA推出的只能用于自家GPU的并行计算框架。只有安装这个框架才能够进行复杂的并行计算。主流的深度学习框架也都是基于CUDA进行GPU并行加速的。
cudnn:是针对深度卷积神经网络的加速库。
————————————————
(原文链接:https://blog.csdn.net/jyfhaoshuai/article/details/118640470)
一:查看自己显卡驱动可以支持的CUDA版本的最高版本(注意:RTX30系列显卡只能支持CUDA11以上的版本!)
(通常新版本的显卡驱动应该能支持当前最高支持CUDA版本以下的所有版本,所以要关注显卡驱动能支持的最高CUDA版本。)
1.打开电脑左下角【搜索键】,搜索NVIDIA控制面板,并打开:


2.点击设置Physx设置——帮助——系统信息——组件,即可出现能支持的最高CUDA版本。
(可以看到,我的显卡最高可以支持到CUDA11.4,所以说我安装的CUDA版本应该满足
CUDA11.0<=我的CUDA版本<=CUDA11.4)

二.安装CUDA
1.打开CUDA Toolkit Archive | NVIDIA Developer,选择自己需要的版本,我这里选择的版本CUDA11.3.0,点Download下载。
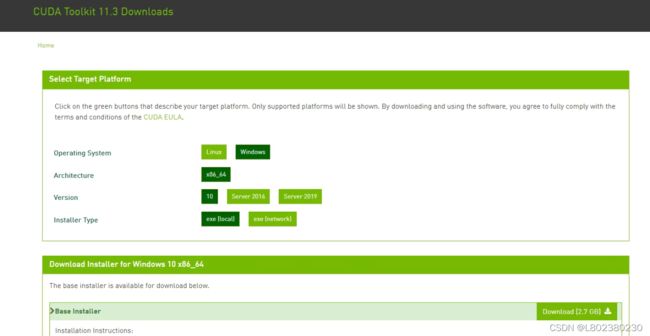
2.下载后点击安装,可以选择默认的安装路径。
(安装cuda时,第一次会让设置临时解压目录,第二次会让设置安装目录;
临时解压路径,建议默认即可,也可以自定义。安装结束后,临时解压文件夹会自动删除;
注意:临时解压目录千万不要和cuda的安装路径设置成一样的,否则安装结束,会找不到安装目录的!!!)
选择【自定义安装选项】
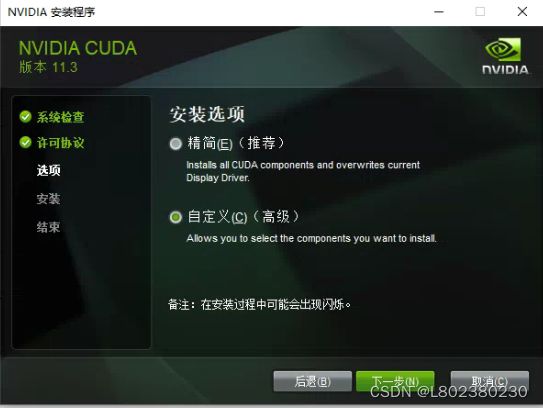
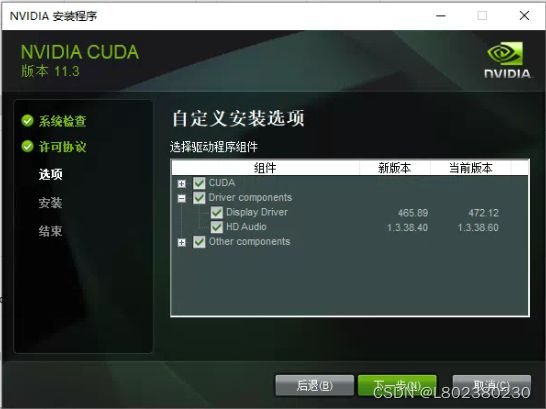
安装目录,建议默认即可:

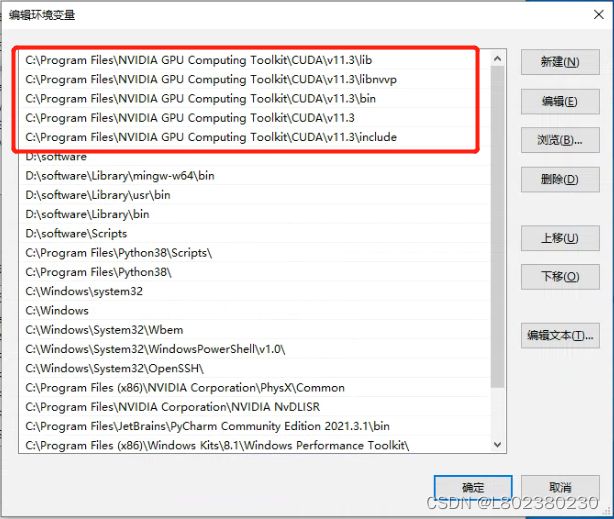
3.在我的电脑右击属性,点【高级系统设置】——【高级】——【环境变量】——【系统变量】
查看:

点【path】——【新建】将这5项添加进去,点击确定。
(这里,我在系统变量和用户变量的path里都把这5项加进去了,因为我不在清楚应该在哪个加,所以都加上了,有懂的大佬,请赐教~)
三.安装cuDNN
1.打开cuDNN Archive | NVIDIA Developer,选择cuDNN v8.2.1的Windows版下载。
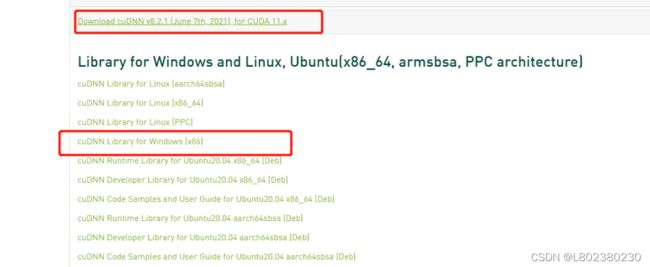
2.下载后打开文件,将文件夹中的三个文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3中:
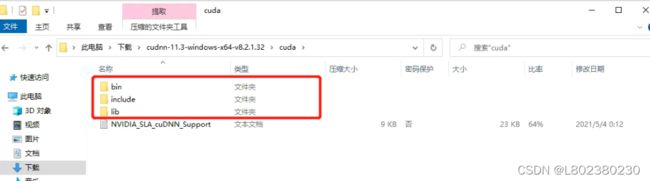
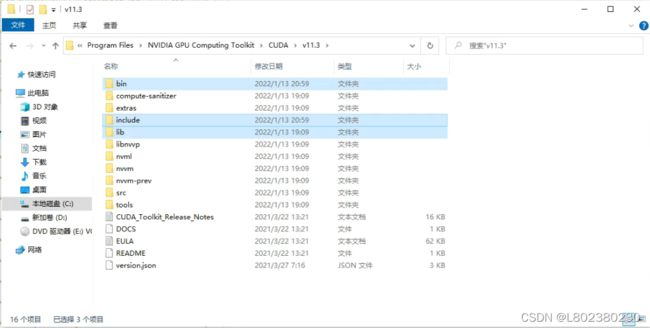
即完成cuDNN下载。
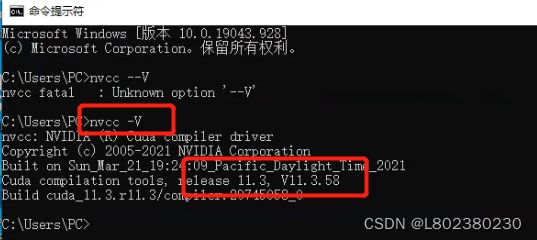
四.测试,进入CMD,输入nvcc -V,可以看到CUDA版本为CUDA11.3。
五.安装Pytorch
1.打开Pytorch官网PyTorch,选择和自己CUDA版本一致的版本。

链接:
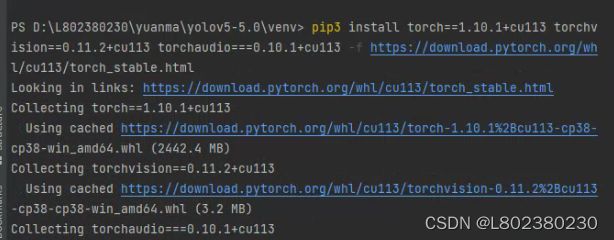
pip3 install torch==1.10.1+cu113 torchvision==0.11.2+cu113 torchaudio===0.10.1+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
2.打开PyCharm,右击venv在Terminal中打开,粘贴链接,回车安装。
检查:可以打开File—settings—Project—Python Interpreter可以看到安装的版本

也可以打开CMD,按顺序输入以下三条指令,可以看出torch版本为1.10.1
!!!(注意最后一条指令是torch.__versio__是两个杠杠![]() )
)

六:运行train.py如果报以下错误,则可以参考成功更改成GPU训练后报错,解决记录_L802380230的博客-CSDN博客

(以上内容只是个人纪录,如果可以帮到大家一点点我也会感到很幸运~)