【AI】利用简单神经网络做动作识别——基于coco关键点
前言
coco数据集包含了关键点检测,如果想利用提取到的这些关键点做行为识别,该怎么办呢?下文主要通过搭建一个简单神经网络(多层感知机)来做关键点的分类。
任务:假如需要对打电话和玩手机的动作做分类。
开始
第一步,需要利用HRNet提取图像中人物的关键点,所需工程代码详见该博文:
YOLOv5+姿态估计HRnet与SimDR检测视频中的人体关键点_围白的尾巴的博客-CSDN博客_yolov5人体检测
第二步,需要重写main.py文件里的代码:
import argparse
import imp
import time
import os
import cv2 as cv
import numpy as np
from pathlib import Path
from Point_detect import Points
from lib.utils.visualization import draw_points_and_skeleton,joints_dict
import csv
from tqdm import tqdm
def image_detect(opt):
skeleton = joints_dict()['coco']['skeleton']
hrnet_model = Points(model_name='hrnet', opt=opt,resolution=(384,288))
pic_file = os.listdir(opt.source)
for pic in tqdm(pic_file):
img0 = cv.imread(os.path.join(opt.source, pic))
frame = img0.copy()
#predict
pred, bbox = hrnet_model.predict(img0) # 这里修改了Point_detect.py文件, 多获取一个bbox坐标信息
### 转为一位数组保存, 后面再处理(这里涉及到多个人的情况)
for target in range(len(pred)):
pred_flatten = pred[target].ravel()[0:33] # 只获取前11个关键点
new = []
tag = 0
for i in range(len(pred_flatten)):
if tag != 2:
new.append(pred_flatten[i])
tag += 1
else:
tag = 0
point_num = 1
base_x, base_y = pred_flatten[0], pred_flatten[1] # 以这个为基准点(鼻子)
w , h = img0.shape[1]-base_x, img0.shape[0]-base_y
k = 0
with open('keypoint.csv', 'a', encoding='utf8') as name:
for i in pred_flatten:
if k % 3 == 0:
k = 1
name.write(str(i)+',') if point_num < len(pred_flatten) else name.write(str(i)+'\n')
# 归一化坐标, 计算关键点相对图片上的位置 --- 很重要!!主要用于神经网络的训练
# 注意: 要考虑在左右两边的情况, 采用对称计算方法
else: # 下面设置tag,目的是按顺序写入x,y
if tag == 0:
if i-base_x < 0:
x_ = base_x+(base_x-i)
x = -(x_-base_x)/w
else:
x = (i-base_x)/w
tag = 1
name.write(str(x)+',') if point_num < len(pred_flatten) else name.write(str(x)+'\n')
else:
if i-base_y < 0:
y_ = base_y+(base_y-i)
y = -(y_-base_y)/h
else:
y = (i-base_y)/h
tag = 0
name.write(str(y)+',') if point_num < len(pred_flatten) else name.write(str(y)+'\n')
k += 1
point_num += 1
# 可视化和保存
# for i, pt in enumerate(pred):
# frame = draw_points_and_skeleton(frame, pt, skeleton)
# name = 'test_result'+pic+'.jpg'
# cv.imwrite(os.path.join('D:/save',name), frame)
def video_detect(opt):
hrnet_model = Points(model_name='hrnet', opt=opt, resolution=(384, 288)) # resolution = (384,288) or (256,192)
skeleton = joints_dict()['coco']['skeleton']
cap = cv.VideoCapture(opt.source)
if opt.save_video:
fourcc = cv.VideoWriter_fourcc(*'MJPG')
out = cv.VideoWriter('data/runs/{}_out.avi'.format(os.path.basename(opt.source).split('.')[0]), fourcc, 24, (int(cap.get(3)), int(cap.get(4))))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
pred = hrnet_model.predict(frame)
for pt in pred:
frame = draw_points_and_skeleton(frame,pt,skeleton)
if opt.show:
cv.imshow('result', frame)
if opt.save_video:
out.write(frame)
if cv.waitKey(1) == 27:
break
out.release()
cap.release()
cv.destroyAllWindows()
# video_detect(0)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--source', type=str, default='D:/call', help='source') # 存放图片的文件夹
parser.add_argument('--detect_weight', type=str, default="./yolov5/weights/yolov5x.pt", help='e.g "./yolov5/weights/yolov5x.pt"')
parser.add_argument('--save_video', action='store_true', default=False,help='save results to *.avi')
parser.add_argument('--show', action='store_true', default=True, help='save results to *.avi')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
opt = parser.parse_args()
image_detect(opt)
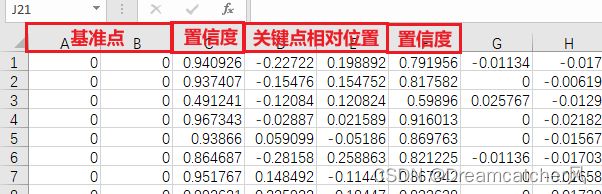
注意,这里有一个地方很重要,就是如何对关键点做归一化处理。
由于每张图片中目标所占图片大小和所在位置完全不同,因此不能直接以图片左上角作为原点去寻找关键点位置,需要利用某个关键点作为原点。我使用的方法是借鉴YOLO v5对Bounding Box做归一化的方式,核心思想是(x/w , y/h),但需要做一些修改:
(下图相对坐标那里有错误,分子应该是y2-y0)

获得一个csv文件:
第三步,搭建多层感知机,训练分类模型:
import csv
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from keras import models, optimizers
from keras.models import Sequential
from keras.layers import Dense, Dropout, BatchNormalization
import keras.backend as K
from keras.callbacks import LearningRateScheduler
from keras.utils.np_utils import *
### 读取文件
data_call = pd.read_csv('D:/keypoint_call.csv') # 这是打电话关键点的文件
data_play = pd.read_csv('D:/keypoint_play.csv') # 这是玩手机关键点的文件
data_no = pd.read_csv('D:/keypoint_no.csv') # 这是负样本文件
### 正负样本拼接, 归一化
train = pd.DataFrame(pd.concat([data_play, data_call], ignore_index=True))
### 补齐17个关键点
for i in range(len(train.columns), 34):
train.insert(loc=i, column=str(i+1), value=0)
### 独热编码
target = [1 if num < len(data_play) else 2 for num in range(len(train))] # 0:负样本 1:玩手机 2:打电话
train = pd.DataFrame(pd.concat([train, data_no], ignore_index=True))
for i in range(len(data_no)):
target.append(0)
target = np.array(target)
target = to_categorical(target, 3)
### 分配训练集和验证集
x_train, x_val, y_train, y_val = train_test_split(train, target, test_size=0.2, random_state=2022)
### 学习率调整方案
def scheduler(epoch):
if epoch % 30 == 0 and epoch != 0:
lr = K.get_value(model.optimizer.lr)
K.set_value(model.optimizer.lr, lr * 0.1)
print("lr changed to {}".format(lr * 0.1))
return K.get_value(model.optimizer.lr)
# 训练
seed = 9
np.random.seed(seed)
model = Sequential()
model.add(Dense(256, input_dim=34, activation='relu'))
# model.add(Dropout(0.5)),
model.add(Dense(128, input_dim=256, activation='relu'))
# model.add(Dropout(0.5)),
# model.add(BatchNormalization()),
model.add(Dense(64, input_dim=128, activation='relu')),
# model.add(Dropout(0.15)),
model.add(Dense(3, activation='softmax'))
model.compile(optimizer=optimizers.adam_v2.Adam(lr=0.001), # 学习率很重要!
loss='categorical_crossentropy',
metrics=['accuracy'])
reduce_lr = LearningRateScheduler(scheduler)
history = model.fit(np.array(x_train),
np.array(y_train),
epochs=100,
batch_size=64, # bs很重要!
validation_data=(np.array(x_val), np.array(y_val)),
callbacks=[reduce_lr]
)
### 可视化训练结果
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.figure(figsize=(6,6))
plt.plot(epochs, acc, 'b', label='Train acc',color='lightseagreen')
plt.plot(epochs, val_acc, 'b', label='Val acc',color='tomato')
plt.xlabel('Epochs')
plt.ylabel('acc')
plt.legend()
plt.show()
### 保存模型
model.save('D:/keypoint_model.h5') 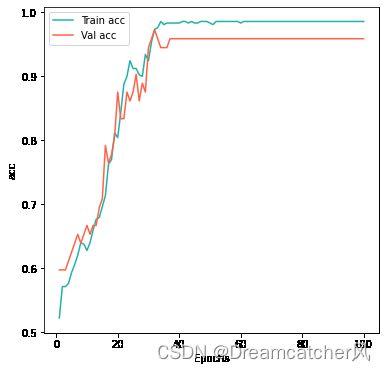
第四步,推理:
对main.py稍作修改即可:(可以用一个if来控制生成csv还是推理,可自行修改)
import argparse
import imp
from random import randrange
import time
import os
import cv2 as cv
import numpy as np
from pathlib import Path
from Point_detect import Points
from lib.utils.visualization import draw_points_and_skeleton,joints_dict
import csv
from tqdm import tqdm
from keras.models import load_model
def image_detect(opt):
skeleton = joints_dict()['coco']['skeleton']
hrnet_model = Points(model_name='hrnet', opt=opt,resolution=(384,288))
keypoint_model = load_model('./keypoint_model.h5')
pic_file = os.listdir(opt.source)
for pic in pic_file:
print('pic = {} :'.format(pic))
img0 = cv.imread(os.path.join(opt.source, pic))
frame = img0.copy()
pred, bbox = hrnet_model.predict(img0)
### 转为一位数组保存, 后面再处理(这里涉及到多个人的情况)
for target in range(len(pred)):
pred_flatten = pred[target].ravel()[0:33] # 只获取前11个关键点
base_x, base_y = pred_flatten[0], pred_flatten[1] # 以这个为基准点(鼻子)
w , h = img0.shape[1]-base_x, img0.shape[0]-base_y
xy = []
k = 1
tag = 0
point_num = 1
for i in pred_flatten:
if k % 3 == 0:
xy.append(i)
k = 1
continue
else:
if i-base_x < 0:
x_ = base_x+(base_x-i)
x = -(x_-base_x)/w
else:
x = (i-base_x)/w
if i-base_y < 0:
y_ = base_y+(base_y-i)
y = -(y_-base_y)/h
else:
y = (i-base_y)/h
if tag == 0:
xy.append(x)
tag = 1
else:
xy.append(y)
tag = 0
k += 1
point_num += 1
for i in range(12):
xy.append(0)
out = keypoint_model.predict(np.array(xy).reshape(1,-1))
predict = np.argmax(out)
tag = 'normal' if predict == 0 else ('play' if predict == 1 else 'call')
print('tag = {}\n'.format(tag))
# 保存bbox和tag
if tag == 'call':
cv.rectangle(frame, (bbox[target][0],bbox[target][1]), (bbox[target][2],bbox[target][3]), (255,0,0), thickness=2)
cv.putText(frame, tag, (bbox[target][0],bbox[target][1]-10), cv.FONT_HERSHEY_SIMPLEX, color=(255,0,0), fontScale = 0.75, thickness=2)
elif tag == 'normal':
cv.rectangle(frame, (bbox[target][0],bbox[target][1]), (bbox[target][2],bbox[target][3]), (255,255,255), thickness=2)
cv.putText(frame, tag, (bbox[target][0],bbox[target][1]-10), cv.FONT_HERSHEY_SIMPLEX, color=(255,255,255), fontScale = 0.75, thickness=2)
else:
cv.rectangle(frame, (bbox[target][0],bbox[target][1]), (bbox[target][2],bbox[target][3]), (0,0,255), thickness=2)
cv.putText(frame, tag, (bbox[target][0],bbox[target][1]-10), cv.FONT_HERSHEY_SIMPLEX, color=(0,0,255), fontScale = 0.75, thickness=2)
name = 'test_result_'+pic+'.jpg'
cv.imwrite('D:/key_save/'+name, frame)
def video_detect(opt):
hrnet_model = Points(model_name='hrnet', opt=opt, resolution=(384, 288)) # resolution = (384,288) or (256,192)
skeleton = joints_dict()['coco']['skeleton']
cap = cv.VideoCapture(opt.source)
if opt.save_video:
fourcc = cv.VideoWriter_fourcc(*'MJPG')
out = cv.VideoWriter('data/runs/{}_out.avi'.format(os.path.basename(opt.source).split('.')[0]), fourcc, 24, (int(cap.get(3)), int(cap.get(4))))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
pred = hrnet_model.predict(frame)
for pt in pred:
frame = draw_points_and_skeleton(frame,pt,skeleton)
if opt.show:
cv.imshow('result', frame)
if opt.save_video:
out.write(frame)
if cv.waitKey(1) == 27:
break
out.release()
cap.release()
cv.destroyAllWindows()
# video_detect(0)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--source', type=str, default='D:/ann', help='source') # 存放图片的文件夹
parser.add_argument('--detect_weight', type=str, default="./yolov5/weights/yolov5x.pt", help='e.g "./yolov5/weights/yolov5x.pt"')
parser.add_argument('--save_video', action='store_true', default=False,help='save results to *.avi')
parser.add_argument('--show', action='store_true', default=True, help='save results to *.avi')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
opt = parser.parse_args()
image_detect(opt)
最后,看看结果
注:当时没加负样本,所以效果仅供娱乐 :)
后记:整个过程比较简单,遇到的一个小坑,主要还是在归一化那里。之前没考虑到这个问题,在实测中发现模型完全胡乱判断,最后才找到原因,解决它。
7.25更新:
经过收集打电话、玩手机、负样本总共10000个样本,训练分类器,最后的效果还不错!
如有新的想法,期待交流探讨

关注我的微信公众号“风的思考笔记”,我们一起思考当下,探索未来自由之路。
