【py脚本】(小记)Lableme 的json转yolo的txt(仅方框)/多边形labelme转coco/关键点检测labelme转coco/yolo-voc-yolo
各种转换(labelme-coco-yolo)
-
- labelme 转yolo的txt(仅方框有效)
- 多边形的labelme转coco
- labelme 转coco 关键点检测,需要先打框,再打点。
-
- coco转yolo亲测有效
- 脚本1:yolo-voc
- 脚本2:voc-yolo并分文件夹
labelme 转yolo的txt(仅方框有效)
Win10 Labelme标注数据转为YOLOV5 训练的数据集亲测有效。(图和json放一个文档下,文档名:LabelmeData,修改程序中的classes=[" "] 即可)
labelme生成的标注数据转换成yolov5格式亲测有效。(图和json放在一个文件夹下,且在该文件夹下创建 转换用的.py。注意,文件所在路径需要全英文,有中文则会报AttributeError: ‘NoneType’ object has no attribute ‘shape’)
可以用labelme打过框,.py转过格式后,用labelimg的yolo模式下验证转换的是否成功
注意:labelimg的验证中,需要在txt所在文件夹下创建 classes.txt,且在classes.txt手动写一下标签名。其次labelimg中修改:file->open annotation
以上两方法仅对打框有效。
注意
from sklearn.model_selection import train_test_split
需要安装相关的包。
可参考机器学习sklearn库安装与分类、回归数据集
pip install numpy
pip install matplotlib
pip install scipy
pip install sklearn
我想实现 labelme打标 出框和点转换成Yolo格式(txt)进行训练,如:基于 Labelme 制作手部关键点数据集 并转 COCO 格式,还未实现
多边形的labelme转coco
无意中尝试出多边形的labelme转coco 参考:https://github.com/Tony607/labelme2coco
下载下来后,图片和json放在images文档,自己再创建一个result文件夹,result文件夹创建个空的trainval.json
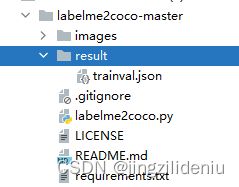
然后用cmd,修改到.py所在路径。键入:python labelme2coco.py images --output result/trainval.json

————————————————————————————————
labelme 转coco 关键点检测,需要先打框,再打点。
基于 Labelme 制作手部关键点数据集 并转 COCO 格式
尝试做背部关键点数据集,labelme先打框,框出背部,再在框里标一个点。
按上面的手部关键点博客中程序,创建j2c.py(复制博客程序直接粘贴进去)
根目录下:
创建文件夹json2 :放图片和原json
创建文件夹 result :用来存放结果
根目录下:j2c.py,json2,result
cmd 里键入 python j2c.py --class_name=back --input=json2 --output=result --join_num=1
并进行修改:
手指21关键点改为“t0”一个点
category['keypoint'] = ["t0"]
程序结尾按自己图片格式bmp改成jpg,且把原来的文件夹改成自己创建的文件夹名(json2)
# 拷贝 labelme 的原始图片到训练集和验证集里面
for file in train_path:
shutil.copy(file.replace("json2", "jpg"), os.path.join(saved_coco_path, "coco", "train"))
for file in val_path:
shutil.copy(file.replace("json2", "jpg"), os.path.join(saved_coco_path, "coco", "val"))
以下是我理解:
–class_name 可以直接是打框的名字,原博客是head,我就改成了back,
–input是输入文件夹
–output是输出文件夹
–join_num是关键点数
程序里是这么解释的:
parser = argparse.ArgumentParser()
parser.add_argument("--class_name", "--n", help="class name", type=str, required=True)
parser.add_argument("--input", "--i", help="json file path (labelme)", type=str, required=True)
parser.add_argument("--output", "--o", help="output file path (coco format)", type=str, required=True)
parser.add_argument("--join_num", "--j", help="number of join", type=int, required=True)
parser.add_argument("--ratio", "--r", help="train and test split ratio", type=float, default=0.12)
args = parser.parse_args()
运行后
result文件夹里创建了文件夹coco
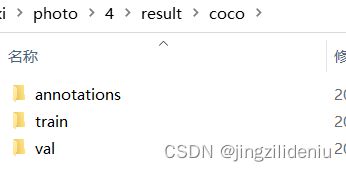
报错情况:
1.若–join_num与json中点个数不同会报错,如下:
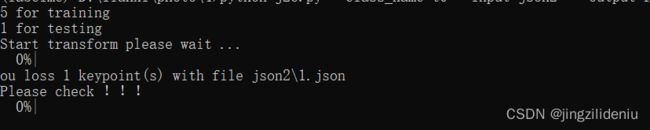
2.我还不知道什么原因
json导出来了,但是图片没有

FileNotFoundError: [Errno 2] No such file or directory: ‘jpg2\4.jpg’
则在此根目录下再创建一个文件夹 叫jpg2,然后把所有的json 和jpg都放进去。就不报错了。
——————————————
coco转yolo亲测有效
COCO 格式的数据集转化为 YOLO 格式的数据集亲测:可以转换一般的打框的,但coco中的关键点无法转换。(只需要再根目录下创建一个文件夹labels,且程序里修改相应路径即可)
COCO(.json)格式 转换为 YOLO(.txt)格式训练(详细介绍,避坑贴)亦是如此
以下内容为尝试过的labelme转yolo方法,仅为笔记
我先打框back,再打关键点t0。
考虑使用
貌似 使用CSDN上的labelme转coco工具(但有数量限制),将标注的框和点转为coco。与上面使用的基于 Labelme 制作手部关键点数据集 并转 COCO 格式所转换出的coco有一定差异。
1.CSDN上的labelme转coco工具,将标注的框和点转为coco。后再通过COCO 格式的数据集转化为 YOLO 格式的数据集,转换的是包含back和t0。
要注意的是,我创建的程序名为cocozhuanyolo.py,
待转的json的文件(train.json)路径 与改程序所在同一目录下,且在该目录下 手动创建一个文件夹(labels) 用来存导出的txt。
2.通过基于 Labelme 制作手部关键点数据集 并转 COCO 格式转换的coco后,再通过COCO 格式的数据集转化为 YOLO 格式的数据集是有back和t0。
用labelimg打开如下。注意用打开一定要修改打标的路径(open annotation,但是经常打不开。那就修改 change save dir 。再反复关闭labelimg试试,而且有时候 其实打开了但界面没有刷新,需要手动双击列表中后面的图,才会突然显示出来)
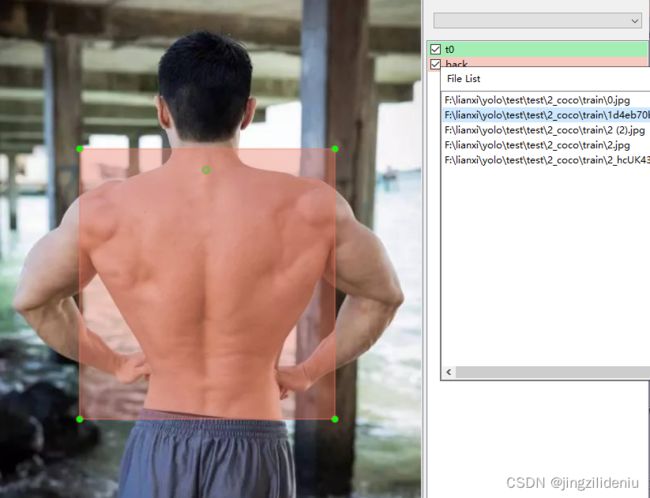
得到的yolo格式,先通过脚本1转成voc,再通过脚本2 ,将voc转成yolo并分文件夹(train\val)
根目录下先创建以下文件夹(运行前创建)
#-mydata
# -images(空)(脚本2转得到的)
# -labels(空)(脚本2转得到的yolo的txt)
# -VOC2007(用存放最原的yolo的文件夹)
# -Annotations(空)(脚本1得到xml)
# -YOLO(放原yolo.txt)
# -JPEGImages(放原图片)
# -YOLOLabels(空)(放脚本2得到的txt)
脚本1:yolo-voc
####
from xml.dom.minidom import Document
import os
import cv2
# def makexml(txtPath, xmlPath, picPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
在自己的标注图片文件夹下建三个子文件夹,分别命名为picture、txt、xml
"""
dic = {'0': "back", # 创建字典用来对类型进行转换
# 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致
}#最后有逗号
files = os.listdir(txtPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
txtList = txtFile.readlines()
img = cv2.imread(picPath + name[0:-4] + ".jpg")
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签
filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin标签结束
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin标签结束
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax标签结束
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax标签结束
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object) # object标签结束
f = open(xmlPath + name[0:-4] + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == "__main__":
picPath = "mydata/VOC2007/JPEGImages/" # 图片所在文件夹路径,后面的/一定要带上
txtPath = "mydata/VOC2007/YOLO/" # txt所在文件夹路径,后面的/一定要带上
xmlPath = "mydata/VOC2007/Annotations/" # xml文件保存路径,后面的/一定要带上
makexml(picPath, txtPath, xmlPath)
脚本2:voc-yolo并分文件夹
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes = ["back"]
# classes=["ball"]
TRAIN_RATIO = 80
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('mydata/VOC2007/Annotations/%s.xml' % image_id)
out_file = open('mydata/VOC2007/YOLOLabels/%s.txt' % image_id, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "mydata/")#修改 一级目录
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0, len(list_imgs)):
path = os.path.join(image_dir, list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if (prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()