机器学习(二):pandas
一、pandas简介
增强可读性

二、pandas数据结构
1.三种数据结构
series(一维数据结构)、DataFrame(二维表格型结构)、multiIndex(三维数据结构)
2.series 的创建
导入pandas包: import pandas as pd
创建series: pd.Series(data=None, index=None, dtype=None)
index表示传入的索引编号,若无则为自动从0开始编号
运用字典创建series: pd.Series({‘属性’:值,‘属性’:值}) 字典类型需要大括号
series 的属性:
数据名.index: 可以获取该数据名的数据
数据名.values:
也可以直接使用数据名.[下标]来搜索某一个数据
3.dataFrame的创建
导入pandas包: import pandas as pd
创建series: pd.DataFrame(data=None, index=None, columns=None) index表示行标签,columns表示列标签
dataFrame的属性:
.shape: 查看行列
.index: 查看行索引列表
.colunms: 查看列索引列表
.values: 查看数组值
.T: 查看数组转置
hand(数字): 获取前几行的内容(默认前5行)
tail(数字): 获取后几行的内容
重设索引:
data.reset_index() 表示重新新建一排索引
data.reset_index(drop=True) 表示重置索引,删除了之前的行索引
4.multiindex和Panel
创建multiindex: pd.MultiIndex.from_arrays()
三、pandas基本操作
3.1 读取文件
读取文件: pd.read_csv(“D:\BaiduNetdiskDownload/day03资料/2.code/data/stock_day.csv”)
删除文件: 数据名.drop(”需要删除的行列内容“,axis= 0/1(行/列))
3.2 索引操作
Numpy当中我们已经讲过使用索引选取序列和切片选择,pandas也支持类似的操作,也可以直接使用列名、行名称,甚至组合使用。
直接使用行列索引名字(先列后行): 数据名[‘列数据’][‘行数据’]
使用先行后列:
通过索引值 数据名.loc[“行数据”:“到另一个行数据”,“列数据”:“到另一个列数据”]
通过索引下标: data.iloc[:3, :5]
例如:①data.loc[data.index[0:5],[“open”,“close”]] 取得下标为0到4的数据,从open和close的列数据
②data.iloc[0:4, data.columns.get_indexer([‘open’, ‘close’, ‘high’, ‘low’])]
3.3 赋值操作
data[‘行列索引’] = 想要赋的值 / data.行列索引 = 想要赋的值
3.4 排序
DataFrame排序: 数据名.sort_values(by=, ascending=)
by:指定排序参考的键
ascending:默认升序 False:降序 True:升序
多值排序: 数据名.sort_values(by=[“数据1”,“数据2”])
先按数据1排序,如果数据1有重复的数据,那么在重复的数据里面按照数据2排序
索引排序: 数据名.sort.index()
series值排序: series.sort_values(ascending=True) 因为是一维数组就没有by
series索引排序: series.sort_index()
四、pandas的算术运算和逻辑运算
1.算数运算逻辑运算
.add(数字): 相加
.sub(数字): 相减
逻辑运算: 数组名.query(查询字符串)
查询运算: 数组名.isin(一个或者多个值) 。例如data[data[“open”].isin([23.53, 23.85])]
isin判断是否在这里面
2.统计函数

求最大值的索引位置: 数组名.idxmax()
求最小值的索引位置: 数组名.idxmin()
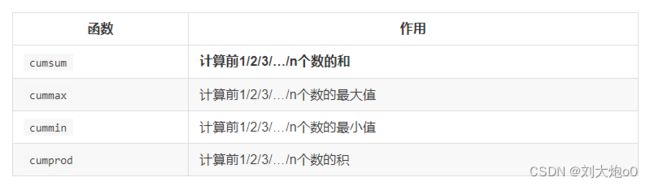
3.累计统计函数(累加之类的)
五、pandas画图
pandas.DataFrame.plot 默认为直方图
pandas.Series.plot
六、pandas文件读取和写入
6.1 CSV
read_csv: pd.read_csv(“文件路径”, usecols= ‘读取列名也可以不写’)
to_csv: 数组名.to_csv(“文件路径”, columns=[‘open’])
6.2 HDF5(跨平台读取)
HDF5文件的读取和存储需要指定一个键,值为要存储的DataFrame
pandas.read_hdf(文件路径,读取的键)
6.3 json文件读取
读取: pd.read_json(“文件路径”, orient=“指定存储的json格式”, lines=True)
修改: json_read.to_json(“./data/test.json”, orient=‘records’)