K近邻算法学习(KNN)
K近邻算法——KNN
- 机器学习——K近邻算法(KNN)
-
- 基本知识点
-
- 基本原理
- 示例
- 关于KNN的基本问题
-
- 距离如何计算?
- k如何定义大小?
- k为为什么不定义一个偶数?
- KNN的优缺点
- 代码实现
-
-
- 第一次写(2022.10.25)
- 增强(2022.10.28)
- 结果分析
-
机器学习——K近邻算法(KNN)
基本知识点
基本原理
给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息进行预测。
——周志华,西瓜书
存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本几种特征最相似数据(最近邻)的分类标签(前k个)。 ——机器学习实战
自我理解:也就是说,有一堆做好标注的训练集样本,然后你抛一个样本进行预测,通过待预测样本最近得k个训练样本点得标注情况来判断要预测得样本属于那个类别。
示例
看完原理,对于这个KNN算法你应该有了基本的了解了,所以看看下面的示例吧!(类型模式来自于课本,数据是自己编写的,只是为了理解算法!)
每部电影的打斗镜头数、接吻镜头数以及电影评估类型
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
|---|---|---|---|
| 爱在黎明破晓前 | 3 | 104 | 爱情片 |
| 怦然心动 | 2 | 100 | 爱情片 |
| 侧耳倾听 | 1 | 81 | 爱情片 |
| 罗小黑战记 | 101 | 5 | 动作片 |
| 集结号 | 99 | 2 | 动作片 |
| 末日之战 | 98 | 2 | 动作片 |
| ? | 18 | 90 | 未知 |
从上表,我们前面已知的6部信息可以构建如下坐标图:

然后通过距离公式来计算k个与“ ? ”最近的点,通过这k个点来判断“ ? ”的电影类型。很显然通过与他最近的k个点可以确定它是爱情片。
接下来通过图形来进行理解,如下:
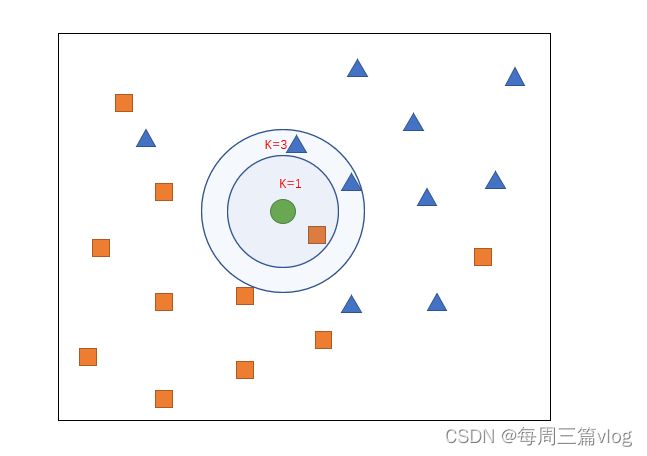
橙色的正方形和蓝色的三角形是我们已经训练好的结果,而绿色的圆形是我们需要进行预测的样本,从图上我们可以发现有两个⭕,这是用来探测待测样本与训练样本距离的最小距离圆(我自己说的)。可以发现k=1和k=3,获得的结果是不一样的,k=1时,预测结果时正方形,而k=3时,预测结果应该为三角形。我们发现,不同的k对我们的预测结果的影响很大,那么这个k的取值应该如何取值呢?通过上表也很容易发现,k为啥都是基数,为啥不定义一个偶数呢?
关于KNN的基本问题
距离如何计算?
当我看到这个算法的时候,我第一时间想到的是,这个算法的最短距离怎么算嘞?一想到的就是一篇空白,距离是怎么算的,这不是用眼睛看的吗?(然后我发现,我真的老了,啥也不会了)
欧式距离:两点之间的直线距离
公式:
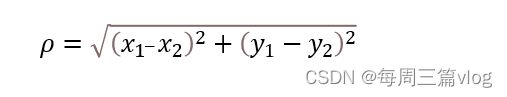
当然,利用的这个公式的话,需要计算待测样本与每一个训练样本之间的距离,然后进行筛选留下最下的k个样本,通过k个样本的标签来判断待测样本的预测结果。
曼哈顿距离:又成为城市街区范围。两个点在坐标轴上的绝对轴距总和。
公式:
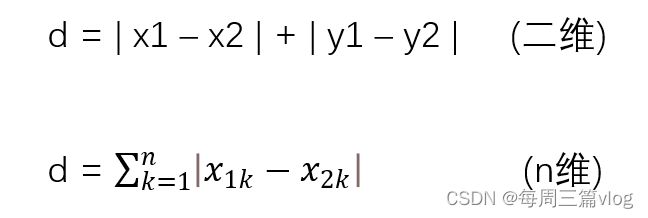
这个比较适合那些维度比较高(特征比较多)的预测分类。
以上最多的是用欧式距离,毕竟简单,直接,最重要的是我们都理解!
说一下我比较喜欢的方法:
直接以待测样本的点作为圆的中心点,然后确定一个最小半径,逐步扩大半径,直到我们圈内的训练样本数>=k时结束,然后根据通过圈内的训练样本数来判断待测样本的预测类型。
k如何定义大小?
通过示例中的正方形和三角形案例,我们可知不同取值的k所造成的影响是不同的,它的泛化能力是比较差的,毕竟它相对于其他的算法而言,没有一个学习(训练)的过程。
| k值 | 影响 |
|---|---|
| 过大 | 预测标签稳定,过于平塌,分类模糊,对于远邻的样本也会起作用 |
| 过小 | 容易造成过拟合,对近邻的样本点过于敏感 |
网络上的结果是:通过交叉验证不断尝试最优的K值,从选取一个较小的K值开始,不断增加K的值,然后计算验证集合的方差,最终找到一个比较合适的K值。
k为为什么不定义一个偶数?
为什么不定义偶数,完全就是为了避免纠结。KNN中的训练样本没有既不也不的情况,不是这个就是那个,是确定的!定义奇数,那么就不可能出现平票的结果。(当然,这里说的是二分类!其余分类需要进行对k进行设计,比如三分类可以用4,7…,总之就是为了避免相对的情况)
KNN的优缺点
我们先看一下KNN的一般流程,如下:
- 收集数据:任何正当手段
- 准备数据:结构化数据格式,就是二分类中的训练样本在坐标中的点,要确定x、y,以及训练样本的(x,y)
- 分析数据:任何正当手段
- 训练算法:不适用!所以——无
- 测试算法:计算错误率
- 使用算法:首先输入样本数据和结构化的输出结果,运行knn算法确定输入样本属于那个分类,然后处理。
| 优点 | 缺点 |
|---|---|
| 精度高 | 没有训练过程 |
| 对异常值不敏感 | 计算复杂度高 |
| 无数据输入假定 | 空间复杂度高 |
代码实现
第一次写(2022.10.25)
数据收集、处理,代码撰写,请往下看:
从百度地图截取下集美大学校本部以及附近周边的区域,通过下图进行数据的划分,分为两部分,一部分为jmu校区内的数据样本,标签我们定义为jmu,一部分为集美大学校区外的数据样本,我们定义它的标签为unjmu,通过它们的横纵坐标来判别是否在jmu校本部内,还是在jmu校本部外。
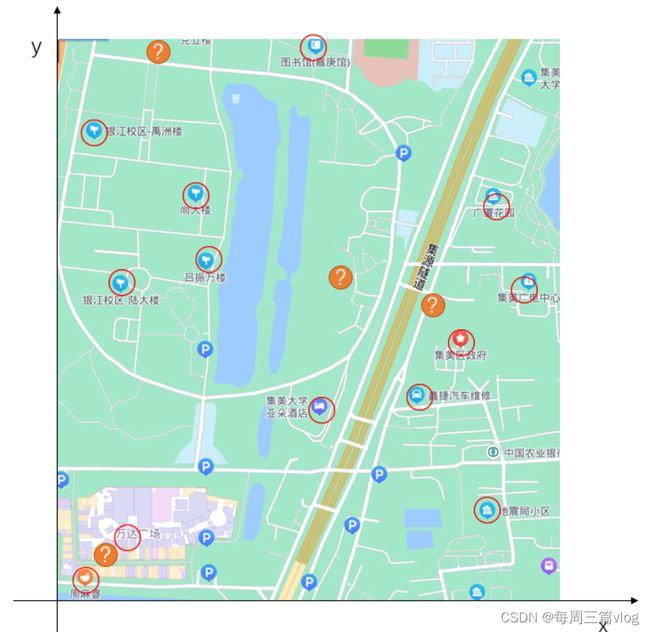
训练集:
| 选取地图的建筑物 | 自定义的位置信息 | label |
|---|---|---|
| 禹州 | (3,85) | jmu |
| 尚大 | (15,70) | jmu |
| 陆大 | (7,58) | jmu |
| 吕振万 | (17,62) | jmu |
| 亚朵酒店 | (33,28) | unjmu |
| 嘉庚图书馆 | (30,100) | jmu |
| 万达 | (10,10) | unjmu |
| 周麻婆 | (2,1) | unjmu |
| 鑫捷汽车维修 | (45,31) | unjmu |
| 集美区政府 | (50,40) | unjmu |
| 广厦花园 | (53,55) | unjmu |
| 集美广电 | (60,58) | unjmu |
| 地震局 | (52,15) | unjmu |
测试集:
| 位置 | label |
|---|---|
| (5, 7) | unjmu |
| (10,100) | jmu |
| (49,49) | jmu |
| (35,40 ) | unjmu |
话不多说,贴代码了:
import matplotlib.pyplot as plt
import numpy as np
import math
class KNN:
def __init__(self, x_train, x_test, k):
# 保留测试点与所以训练样本的距离
self.distance = np.zeros((len(x_test), len(x_train)))
# 保留预测结果
self.predicted = []
# KNN中k的取值(不懂看上面基本知识点)
self.k = k
# KNN核心算法
def knn(self, x_test, x_train, y_train):
print(y_train)
for i in range(len(x_test)):
for j in range(len(x_train)):
self.distance[i][j] = self.knn_distance(x_test[i], x_train[j])
self.predicted.append(self.knn_predicted(self.distance[i], y_train))
return self.predicted
# 利用欧拉公式计算距离
def knn_distance(self, x1, x2):
dis = math.sqrt(math.pow((x1[0]-x2[0]),2) + math.pow((x1[1]-x2[1]),2))
return dis
def knn_predicted(self, distances, y_train):
#利用numpy的argsort方法获取前K小样本的索引
k_predicted_index = distances.argsort()[:self.k]
# 由于对一些库的函数学习不深,所以选择下面我自己可以实现的方法
count_jmu = 0
count_other =0
for i in range(len(k_predicted_index)):
if(y_train[k_predicted_index[i]] == 'jmu'):
count_jmu += 1
else:
count_other += 1
if(count_jmu > count_other):
return 'jmu'
else:
return 'unjmu'
# 自定义训练数据集
x_train = [[3, 85], [15, 70], [7, 58], [17,62], [33,28], [30,100], [10,10], [2,1], [45,31], [50,40], [53,55], [60,58], [52,15]]
y_train = ['jmu', 'jmu', 'jmu', 'jmu', 'unjmu','jmu' ,'unjmu' ,'unjmu' ,'unjmu' ,'unjmu' ,'unjmu' ,'unjmu' ,'unjmu']
# 自定义测试数据集
x_test = [[5,7], [10,100], [19,49], [35,40]]
y_test = ['unjum','jum','unjum','jum']
# 设置KNN中的k
k = 3
knn = KNN(x_train, x_test, k)
# 获得测试集的预测结果
pred = knn.knn(x_test, x_train, y_train)
print(pred)
输出结果展示:

增强(2022.10.28)
数据集:
链接:https://pan.baidu.com/s/1yrDGiK9yXFxB_JyC3Q5ycg
提取码:1234
如果你觉得上面的描述或者代码不够清晰,请看这里,对于上述的代码,如果想要改变数据集好像很困难,而且变化不大,不易于修改,所以进行了一定的精炼,请看下面:
代码:
首先,对于python来说,典型的黑盒子,我们需要导入我们所需方法的库进行调用。
import matplotlib.pyplot as plt
import numpy as np
import math
import pandas as pd
from sklearn.model_selection import train_test_split
然后,根据KNN的算法思想进行编写KNN主体函数
class KNN:
def __init__(self, x_train, x_test, k):
# 保存距离
self.distance = np.zeros((len(x_test), len(x_train)))
# 预测结果
self.predicted = []
# knn中的k值
self.k = k
# knn的主要函数
def knn(self, x_test, x_train, y_train):
for i in range(len(x_test)):
for j in range(len(x_train)):
self.distance[i][j] = self.knn_distance(x_test[i], x_train[j])
self.predicted.append(self.knn_predicted(self.distance[i], y_train))
return self.predicted
# 欧式距离的计算
def knn_distance(self, x1, x2):
dis = math.sqrt(math.pow((x1[0]-x2[0]),2) + math.pow((x1[1]-x2[1]),2))
return dis
# 预测knn函数
def knn_predicted(self, distances, y_train):
k_predicted_index = distances.argsort()[:self.k]
count_jmu = 0
count_other =0
for i in range(len(k_predicted_index)):
if(y_train[k_predicted_index[i]] == 'jmu'):
count_jmu += 1
else:
count_other += 1
if(count_jmu > count_other):
return 'jmu'
else:
return 'unjmu'
通过绘制测试集和训练集的样本分布来视觉上查看预测结果
# 绘图(看数据集分布)
def paint(x_train, x_test):
# 绘制图像, X、Y是存储unjmu的数据,X1、Y1存储的是jmu的数据,Z是用于过渡
X = []
X1 = []
X2 = []
Y = []
Y1 = []
X2 = []
Z = []
# 根据训练样本获取x、y
x_train = np.array( x_train)
X = x_train[:,0]
Y = x_train[:,1]
# 对数据进行处理,根据训练集的数据以及label划分出jmu的点和unjum的点
for i in range(len(y_train)):
if(y_train[i] == 'jmu'):
Z.append(i)
X1.append(X[i])
Y1.append(Y[i])
X = np.delete(X,Z)
Y = np.delete(Y,Z)
# 绘制测试集的数据准备
x_test = np.array(x_test)
X2 = x_test[:,0]
Y2 = x_test[:,1]
# 绘图,红色为jmu的数据,绿色是unjmu数据,蓝色为测试样本
plt.scatter(X, Y, color = 'g')
plt.scatter(X1, Y1, color ='r')
plt.scatter(X2, Y2, color ='b')
# 数据处理,将csv获得的数据变成列表
def data_tolist(x_train, x_test, y_train, y_test):
x_train = np.array(x_train)
x_train = x_train.tolist()
y_train = np.array(y_train)
y_train = y_train.tolist()
x_test = np.array(x_test)
x_test = x_test.tolist()
y_test = np.array(y_test)
y_test = y_test.tolist()
return x_train, x_test, y_train, y_test
# 计算精确度
def predicted(pred, y_test):
count = 0
for i in range(len(pred)):
if(y_test[i] == pred[i]):
count += 1
pred1 = count / len(y_test)
return pred1
# 利用panda库进行对csv文件的读取和处理操作
data=pd.read_csv("D:/桌面/1.csv")
X = data.iloc[:,:2]
Y = data.iloc[:,2]
# 划分数据集,并且将数据集转换成list类型,0.8的训练集,0.2的测试集
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2)
x_train, x_test, y_train, y_test = data_tolist(x_train, x_test, y_train, y_test)
paint(x_train, x_test)
for i in range(len(x_train)):
if (i%2 != 0):
k = i
knn = KNN(x_train, x_test, k)
pred = knn.knn(x_test, x_train, y_train)
print(y_test)
print(f"预测结果:{pred}")
predicte = predicted(pred, y_test)
print(f"k = {k}时,测试精度为:{predicte}")
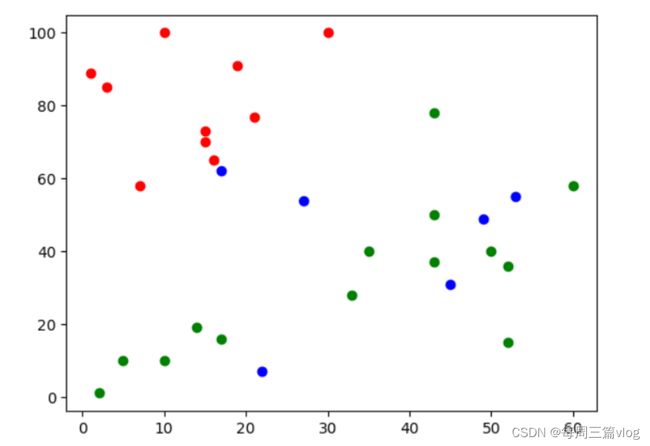
注:红色定义为jmu样本,蓝色为待遇测样本,绿色为unjmu样本
结果分析
以上面增强代码和运行结果进行分析,去十次结果(理应进行对k=0,到k=len(x_train)进行分析),之所以取10十因为k取值越大,其实结果过于模糊,说白了k越大,等于比较数据集那个label的样本数更多了。
| k = ? | predicate |
|---|---|
| 1 | 1 |
| 3 | 0.83333 |
| 5 | 1 |
| 7 | 1 |
| 9 | 1 |
| 11 | 0.83333 |
| 13 | 0.83333 |
| 15 | 0.83333 |
| 21 | 0.66666 |
| 23 | 0.66666 |
从上表看:貌似k取越小越好,k越大预测的精度就越差了,这是为什么呢?难道k真的取值越小越好吗?
首先来说第一个问题:
k越大精度就越差,为什么呢?
首先,先分析一下我的数据集,我的数据集中label为unjmu的样本和jmu的样本数量上是不匹配的,unjmu的样本明显大于jmu,那么在k取值越大的情况下unjmu的样本就会在那些label标签为jmu中的作用越大,导致将label将jmu样本预测成unjmu。所以说,当k大于一定的值时,预测结果和样本数据集标签种类的数量关系会被放大。
再说一下第二个问题:
k取越小越好吗?
看下图:
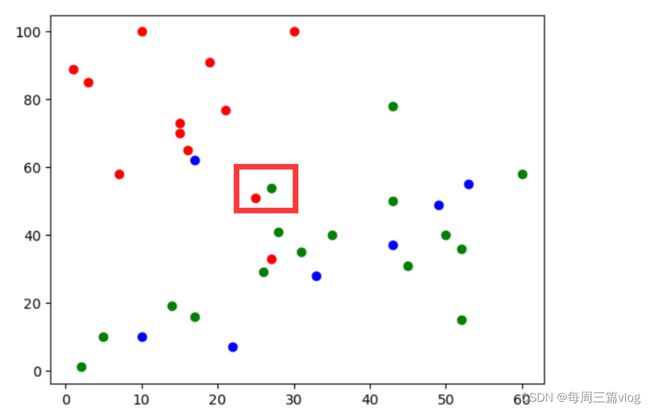
框中待预测的样本为unjmu,但是与他最近的标签是人为标注错误的标签,如果k越小越好,那么理应取k=1(最近邻),可是这样的话很大程度需要样本0错误,但凡出现了一个错误标签都可能导致预测结果出现错误,而人工标注的数据集想要实现0错误是很难的。(就像我刚开始编写数据的时候,出现了label撰写错误的情况)。所以说k的取值也不是越小越好。
综上:那么k应该如何定义大小呢。在上文对于KNN的基本问题的提出中,提到了交叉验证的方法,大家可以尝试一下。我个人认为k的取值主要与一下几个方面有关:
- 数据集的大小。(太大,则k不能取太小的值,否则过拟合严重;太小,k不能取大值,否则模糊性太强)
- 样本标签种类。(种类多了,那么出现标注错误的可能性就大了)
- 样本的数据维度。(不同维度最好取不同的距离计算公式,计算方法不同,则k值得选取也需要进行调控)