End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures

End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures
基于LSTM的序列和树结构端到端关系提取
1 Abstract
本文通过在双向sequential LSTM-RNNs上堆叠双向树形结构的LSTM-RNNs来捕获单词序列和依存树子结构信息。基于共享参数的方法进行训练,在训练期间检测实体,并通过实体预训练和计划抽样在关系抽取中使用实体信息。
c code
1 Introduction
本文提出一种新的端到端模型来提取词序列和依存关系树结构上实体之间的关系。通过使用双向顺序和双向树形结构的LSTM-RNNs进行实体和关系的联合建模,首先检测实体,然后使用单个递增解码的神经网络结构提取检测到的实体之间的关系,本文在训练中加入了两个增强:实体预训练和计划抽样。实体预训练用于预先训练实体模型;计划抽样是以一定的概率将预测标签替换为gold label。这种方法缓解了训练早期阶段低性能实体检测的问题,并允许实体信息进一步帮助下游任务。
2 Model
2.1 OVerview
本文使用LSTM-RNNs设计模型,同时表示单词序列和依存关系树结构,并在此基础上进行实体关系的端到端提取。该模型主要由三部分组成:词嵌入层、基于词序列的LSTM-RNN层(序列层)和基于依存关系子树的LSTM-RNNs层(依存关系层)。在解码中,在序列层进行实体检测,在依赖层实现关系分类,每个基于子树的LSTM-RNN对应于两个被检测实体之间的一个关系候选。依赖层堆叠在序列层之上,因此嵌入层和序列层由实体检测和关系分类共享,共享的参数受实体和关系标签的影响。

2.2 Embedding Layer
将词words、词性part-of-speech POS、依存关系dependency types、实体标签entity labels分别映射为:
v ( w ) ∈ R 1 × n w v ( p ) ∈ R 1 × n p v d ∈ R 1 × n d v e ∈ R 1 × n e v^{(w)}\in R^{1\times n_w}\\ v^{(p)}\in R^{1\times n_p}\\ v^{d}\in R^{1\times n_d}\\ v^{e}\in R^{1\times n_e} v(w)∈R1×nwv(p)∈R1×npvd∈R1×ndve∈R1×ne
2.3 Sequence Layer
图一左下所示,将嵌入层的词嵌入和POS嵌入作为输入,即输入为:
x t = [ v t ( w ) , v t ( p ) ] x_t=[v_t^{(w)},v_t^{(p)}] xt=[vt(w),vt(p)]
这一层主要的任务是实体检测,首先利用LSTM进行序列编码,得到两个方向的输出:
s t = [ h → t ; h ← t ] s_t=[\overset{\rightarrow}{h}_t; \overset{\leftarrow}{h}_t] st=[h→t;h←t]
2.4 Entity Detection
将实体识别任务其看做一项序列标注任务,即实体标签采用BILOU的标注方式,实体类别在实体标签之后,利用两个全连接层实现实体识别:
h t ( e ) = t a n h ( W e h [ s t ; v t − 1 ( e ) ] + b ( e h ) ) y t = s o f t m a x ( W e y h t e + b e y ) h_t^{(e)}=tanh(W^{e_h}[s_t;v_{t-1}^{(e)}]+b^{(e_h)})\\ y_t=softmax(W^{e_y}h_t^e+b^{e_y}) ht(e)=tanh(Weh[st;vt−1(e)]+b(eh))yt=softmax(Weyhte+bey)
预测每个实体时,输入为LSTM的输出和上一时刻word的预测出的标签的嵌入 v t − 1 e v_{t-1}^e vt−1e,从而考虑到标签上的依赖性。
2.5 Dependency Layer
依存关系层表示依存树中一对目标词之间的关系,主要关注依存关系树中一对目标词之间的对短距离,如图1最下方的路径就是最短路径。本文使用双向树形结构的LSTM-RNNs表示候选关系(通过捕获目标词对周围的依存结构来表示候选关系)。
这种树形结构的LSTM-RNNs不是对序列建模,而是利用树结构建模,一个句子形成树形结构可以分为两类:句法短语解析树(依存树dependency tree)和依赖树(短语句法树parse tree)。对于句法解析树采用Child-Sum Tree-SLTM;对于依赖树采用N-ary Tree-LSTMs。
- 依存树
- 没有词组这个层次,每个结点都与句子中的单词相对应,能够直接处理句子中词与词之间的关系,便于标注词性

- 短语句法树
- 由各组成部分的意义以及用以结合它们的规则来决定的
- 如果想要得到一个句子或短语的向量表示,可以先找到它每一组成部分的意思,然后将其融合的父节点作为规则,计算出相邻K个部分的相似度,接着组织相似度高的s个结点的父节点作为其父节点,最后递归构造出句法树。

显然依存树的孩子结点是无序的,而且对于每一个父节点,它所拥有的孩子结点是不限制个数的。可以共享同类型孩子节点的权重矩阵,并且允许孩子节点的数目可变。
- Child-Sum Tree-LSTMs
- 叶子结点一般是序列的输入(词向量)
- 内部节点是LSTM单元
- 存储器单元的更新取决于父节点的孩子结点的状态(可以尽可能多的接受来自多个孩子结点的信息)
- N-ary Tree-LSTMs
- Child-Sum的更新取决于子节点的隐藏状态之和(输入为第j个序列词 x j x_j xj,所有孩子结点的隐藏状态之和 h ∼ j \overset{\sim}{h}_j h∼j)
- N-ary是对每一个孩子结点的隐藏状态分别计算然后求和(输入:第j个序列次 x j x_j xj,N个孩子结点 h j h_j hj)
- N-ary能更细粒度的表达信息,Child-Sum直接简单粗暴求和
LSTM:
i t = σ ( W i x t + U i h t − 1 + b i ) f t = σ ( W f x t + U f h t − 1 + b f ) o t = σ ( W o x t + U o h t − 1 + b o ) u t = t a n h ( W u x t + U u h t − 1 + b u ) c t = i t ⊙ u t + f t ⊙ c t − 1 h t = o t ⊙ t a n h ( c t ) i_t = \sigma(W^ix_t+U^ih_{t-1}+b^i)\\ f_t = \sigma(W^fx_t+U^fh_{t-1}+b^f)\\ o_t = \sigma(W^ox_t+U^oh_{t-1}+b^o)\\ u_t = tanh(W^ux_t+U^uh_{t-1}+b^u)\\ c_t = i_t\odot u_t + f_t\odot c_{t-1}\\ h_t = o_t\odot tanh(c_t) it=σ(Wixt+Uiht−1+bi)ft=σ(Wfxt+Ufht−1+bf)ot=σ(Woxt+Uoht−1+bo)ut=tanh(Wuxt+Uuht−1+bu)ct=it⊙ut+ft⊙ct−1ht=ot⊙tanh(ct)
Child-Sum Tree-LSTMs:
i t = σ ( W i x t + ∑ l ∈ C t U m ( l ) i h t l + b i ) f t k = σ ( W f x t + ∑ l ∈ C t U m ( k ) m ( l ) f h t l + b f ) o t = σ ( W o x t + ∑ l ∈ C t U m ( l ) o h t l + b o ) u t = t a n h ( W u x t + ∑ l ∈ C t U m ( l ) u h t l + b u ) c t = i t ⊙ u t + f t ⊙ c t l h t = o t ⊙ t a n h ( c t ) i_t = \sigma(W^ix_t+\sum_{l\in C_t}U_{m(l)}^ih_{tl}+b^i)\\ f_{tk} = \sigma(W^fx_t+\sum_{l\in C_t}U^f_{m(k)m(l)}h_{tl}+b^f)\\ o_t = \sigma(W^ox_t+\sum_{l\in C_t}U^o_{m(l)}h_{tl}+b^o)\\ u_t = tanh(W^ux_t+\sum_{l\in C_t}U^u_{m(l)}h_{tl}+b^u)\\ c_t = i_t\odot u_t + f_t\odot c_{tl}\\ h_t = o_t\odot tanh(c_t) it=σ(Wixt+l∈Ct∑Um(l)ihtl+bi)ftk=σ(Wfxt+l∈Ct∑Um(k)m(l)fhtl+bf)ot=σ(Woxt+l∈Ct∑Um(l)ohtl+bo)ut=tanh(Wuxt+l∈Ct∑Um(l)uhtl+bu)ct=it⊙ut+ft⊙ctlht=ot⊙tanh(ct)
2.6 Stacking Sequence and Dependency Layers
将依赖层堆叠在序列层的顶部,以便将单词序列和依赖树结构信息合并到输出中。该层的输入:sequence layer对应时刻的隐藏状态、依存关系嵌入和实体嵌入
x t = [ s t ; v t d ; v t e ] x_t=[s_t;v_t^d;v_t^e] xt=[st;vtd;vte]
2.7 Relation Classification
译码过程中,使用被检测实体的最后一个单词的所有可能组合,对于每个候选关系,本文实现了与关系候选词对P之间的路径相对应的依赖层 d p d_p dp,神经网络接收到由依赖树层构造的关系候选向量,并预测其关系符号,如果检测的实体是错误或没有关系时,视为一对负关系。本文通过类型和方向来表示关系标签。
在预测实体关系时,tree-LSTM会有三个输出:
d p = [ ↑ h p A ; ↓ h p 1 ; ↓ h p 2 ] d_p = [\uparrow h_{p_A};\downarrow h_{p_1};\downarrow h_{p_2}] dp=[↑hpA;↓hp1;↓hp2]
↑ h p A \uparrow h_{p_A} ↑hpA表示自下而上的LSTM-RNNs中顶部LSTM单元的隐藏状态向量(代表目标单词对p的最近公共祖先,两个实体向上传播到根结点的输出); ↓ h p 1 , ↓ h p 2 \downarrow h_{p_1},\downarrow h_{p_2} ↓hp1,↓hp2是自上而下的两个LSTM单元的隐藏状态(LSTM-RNNs)
关系分类和实体检测相似,使用具有 n h r n_{hr} nhr维度的隐藏状态层 h r h^r hr和softmax:
h p r = t a n h ( W r h d p + b r h ) y p = s o f t m a x ( W r y h t r + b r y ) h_p^r = tanh(W^{r_h}d_p + b^{r_h})\\ y_p = softmax(W^{r_y}h_t^r + b^{r_y}) hpr=tanh(Wrhdp+brh)yp=softmax(Wryhtr+bry)
由于本模型使用words表示实体,因此不能充分利用实体信息,为了缓解这个问题,本文将序列层到输入 d p d_p dp再到关系分类的**每个实体的隐藏状态向量的平均值**拼接到 d p d_p dp上:
d p ’ = [ d p ; 1 ∣ I p 1 ∣ ∑ i ∈ I p 1 s i ; 1 ∣ I p 2 ∣ ∑ i ∈ I p 2 s i ] d_p^{’} = [d_p;\frac{1}{|I_{p_1}|}\sum_{i\in I_{p_1}}s_i;\frac{1}{|I_{p_2}|}\sum_{i\in I_{p_2}}s_i] dp’=[dp;∣Ip1∣1i∈Ip1∑si;∣Ip2∣1i∈Ip2∑si]
其中 I p 1 、 I p 2 I_{p_1}、I_{p_2} Ip1、Ip2表示第一个实体和第二个实体中的单词索引的集合
3 Results
3.1 Data
ACE2005定义了7种粗粒度实体类型和6种粗粒度的关系类型。
ACE2004定义了相同的七个粗粒度实体类型,7个粗粒度关系类型,采用交叉验证设置。
SemEval-2010 Task 8定义了名词性名词之间的9种关系类型,以及两个名词之间没有这些关系时的第十种关系类型,将第十种关系定义为负关系类型。
3.2 Experiment Settings
- 使用Stanford 神经依赖解析器和原始的Stanford依赖项对文本进行解析
- 将嵌入维度 n w = 200 , n p = n d = n e = 25 n_w=200,n_p=n_d=ne=25 nw=200,np=nd=ne=25,中间层维度为100
- 在ACE05上进行调参,在ACE04上直接采用ACE05的最佳参数
- 对于SemEval-2010 Task8省略了实体检测和标签嵌入
3.3 End-to-end Relation Extraction Results
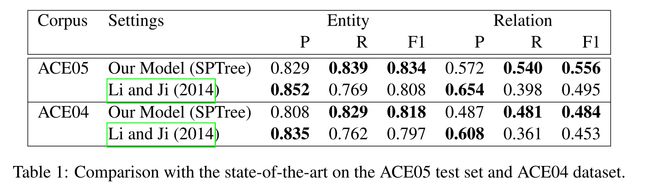

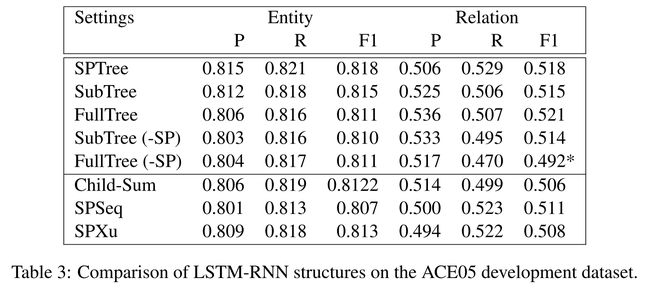
4 启示
- 第一篇联合实体关系抽取论文
- 采用依赖树的方式会忽略标签之间的长依赖关系