达摩院文档级关系抽取新SOTA和零样本关系抽取新任务

©作者 | 邴立东、谭清宇、谢耀赓
单位 | Alibaba DAMO, NUS, SUTD
引言
关系抽取(RE)是 NLP 的核心任务之一,是构建知识库、事件抽取等下游应用的关键技术。多年来受到研究者的持续关注。本文将介绍达摩院语言实验室多语言算法团队的两篇 ACL Findings 2022 论文。
第一篇论文聚焦于文档级关系抽取,我们的模型在 DocRED 排行榜上将 SOTA F1 值提高了 1.36,Ign_F1 值提高了 1.46。第二篇论文提出了零样本句子级关系抽取的新任务,旨在解决现有的任务设定不能泛化到陌生关系上的问题。具体地,我们提出了 RelationPrompt 方法来为陌生关系生成训练样本,进而训练抽取器。RelationPrompt 还可以作用于零样本关系分类任务,取得了平均优于基线算法 10 个点的 F1。

基于自适应Focal Loss和知识蒸馏的文档级关系抽取
本小节工作来自论文:Document-Level Relation Extraction with Adaptive Focal Loss and Knowledge Distillation, in ACL Findings 2022.

论文链接:
https://arxiv.org/abs/2203.10900
数据代码:
https://github.com/tonytan48/KD-DocRE
1.1 背景介绍
关系抽取,Relation Extraction from Text,简称 IE,是从自然语言文本中,抽取出实体之间的关系。传统的关系抽取方法主要是抽取单个句子间两个实体的关系,这一任务被称为句子级别关系抽取。然而,在真实的应用场景中,大量的实体关系是由多个句子联合表达的,因此,文档级别的关系抽取相对于句子级别更加具有应用价值 [1]。
具体的任务定义为:给定一个文档 D,其中的实体数目为 N,模型需要预测所有实体对之间的关系,总共需要做 N(N-1)个实体对的关系分类。
目前,文档级别的关系抽取依然面临四个方面的挑战:
第一,大部分文档级别的实体关系横跨多个句子,关系抽取模型需要捕捉更长的上下文信息。
第二,同一文档中包含大量实体,文档级别关系抽取需要同时抽取所有实体间的关系,其复杂度与文档中的实体数成平方关系,分类过程中存在大量的负样本。
第三,文档级别关系抽取的样本类别属于长尾分布,以清华大学发布的 DocRED 数据集为例,频率前十的关系占到了所有关系的 60%,而剩下的 86 种关系只占全部关系三元组的 40%。
第四,由于文档级别的数据标注任务较难,现有的数据集中人工标注的训练数据十分有限。大量的训练数据为远程监督 [2] 的训练数据,而远程监督的数据中存在大量的噪音,限制模型的训练。
1.2 模型介绍
鉴于以上的挑战,我们提出了一个基于知识蒸馏的半监督学习框架,和一个新的关系抽取的模型。

▲ 图1.1 模型概况
如上图所示,在前人工作 ATLOP 模型 [3] 的基础上,我们提出的模型主要提供了三个新的模块,第一,我们利用轴向注意力机制 [4] 来提取实体对表示之间的相互关系,如上图所示,图中的红色部分代表实体对(e3,e6)的相关区域,例如假设 e3 为杭州,e6 为亚洲,而中间实体 e8 为中国,那么(e3 杭州, e6 亚洲, 大洲)这一关系可以通过(e3 杭州, e8 中国,国家)这一三元组和(e8 中国,e6 亚洲,大洲)这一三元组联合推理得到。
第二,为了缓解关系抽取数据中的样本不平衡的问题,受 Focal Loss [5] 启发,我们提出使用 Adaptive Focal Loss 来提高模型在长尾关系上的表现,具体形式为缩放高频关系的概率输出以及放大一些低频关系的概率输出,详细的方法在文章的章节 2.2.2 中。
第三,我们在训练过程中利用知识蒸馏的机制来过滤远程监督数据中的噪音。DocRED 数据集中包含大量的远程监督的数据,传统的方法仅采用远程监督数据进行预训练,而忽略了远程监督数据中的噪音,我们将这一基准方法记为 Naïve Adaptation(NA),作为对比我们将知识蒸馏 [6] 的方法记为 KD,我们首先利用 DocRED 的少量人工标注训练数据训练一个老师模型,再利用这个老师模型,对于所有的远程监督数据进行预测,其输出的概率分布会被作为软标签。
接下来我们会基于这些软标签,和远程监督数据中带有噪音的标签训练一个结构相同学生模型,学生模型的训练过程中有两个损失函数,第一个就是之前提到的 Adaptive Focal Loss,用来学习远程监督数据中的标签。第二个就是基于老师模型输出的软标签计算的均方误差(MSE),这一损失函数可以尽可能让学生模型的输出更接近于老师模型,这两个损失函数将会被相加并共同训练。最后,所训练得到的学生模型会进一步在人工标注的数据中进行微调,得到我们的最终模型。
1.3 实验分析
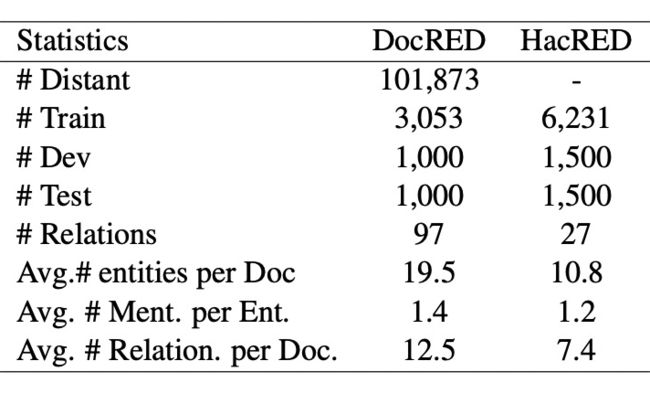
▲ 表1.1 DocRED以及HacRED数据统计
为了验证我们模型的有效性,我们在 DocRED [1] 数据集以及 HacRED [7] 数据集(表1.1)上进行了实验。

▲ 表1.2 DocRED实验结果
我们的实验结果如上表所示,其中我们的模型记为 Ours-B-b 和 Rb-l 分别指的是 Bert-base 和 Roberta-large 语言模型。我们的模型相对于之前的基线模型均取得了显著的提升,并且在 DocRED 排行榜上,我们的 KD-Roberta 模型相对于之前的 SOTA-SSAN-NA [8] 提高了 1.36 F1 以及 1.46 Ign_F1。
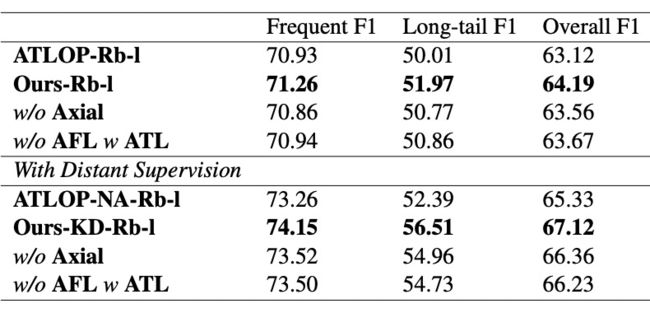
▲ 表1.3 DocRED开发集消融实验
在 DocRED 数据集上,我们针对高频关系(前十种关系)以及长尾关系(剩余 86 种关系)进行了消融实验,从上表(表1.3)可以看到,我们的 AFL 和轴向注意力模块都能有效提高模型在长尾关系上的表现。
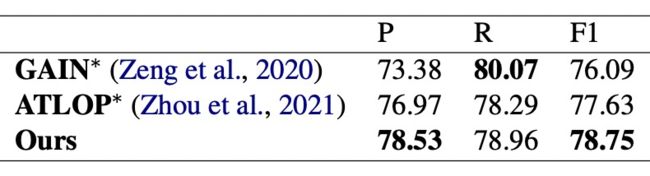
▲ 表1.4 HacRED实验
我们同样在 HacRED 数据集上做了对比实验(表1.4),但由于 HacRED 尚未公布测试集,我们只汇报了相同场景下开发集的结果。
1.4 错误分析
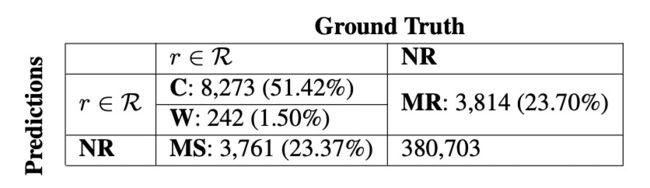
▲ 表1.5 错误分析

▲ 图1.2 例子分析
我们对目前最好的模型进行了详实的错误分析,我们首先根据实体对将预测出来的三元组与标注中的三元组进行了比对,其中实体对与关系同时预测正确,记为Correct(C),如果实体对预测正确,而预测出来的关系是错误的,记为 Wrong (W)。如果测试集中标注的关系预测为‘No Relation’,我们将其视作未预测出的三元组,记为 Missed(MS)。最后我们将模型预测出有关系,但测试集中未标注的三元组记为 More(MR)。
这一些错误的统计结果在表 1.5 中有所体现,我们可以看到预测错误(W)的占比相对于 MS 和 MR 较小。而 MS 和 MR 的比例相当,根据我们进一步的分析,我们发现 MR 的三元组中,存在一定数量的正确三元组,如图 1.2 所示,该文章描述了一名挪威的政客,在标注数据中,Hol 是挪威的一个城市,而文中出现的 Vestvågøy 同样也是挪威的一个城市,在同一标准下,Vestvågøy 理应同样被标注。这一发现反映了 DocRED 数据中可能存在漏标的现象,这一发现可以为未来文档级别的关系抽取提供一定的思路和启发。
1.5 总结
综上所述, 我们提出了一个基于知识蒸馏的半监督学习框架,并且基于轴向注意力和自适应聚焦函数提出了一个新的文档级别关系抽取的模型,并且在 DocRED 排行榜显著超过了 SOTA 的表现。

RelationPrompt:通过提示语言模型的数据生成来解决零样本关系三元组抽取任务
本小节工作来自论文:RelationPrompt: Leveraging Prompts to Generate Synthetic Data for Zero-Shot Relation Triplet Extraction, in ACL Findings 2022.

论文链接:
https://arxiv.org/abs/2203.09101
数据代码:
http://github.com/declare-lab/RelationPrompt
2.1 问题提出
关系三元组是知识库 [9] 的基本组成部分,能应用于搜索、社交网络、事实核查等等。然而,具体地说,现有的模型只能针对训练时候见过的关系类别执行三元组抽取(Relation Triplet Extraction)。因此,我们首次提出零样本关系三元组抽取任务(Zero-Shot Relation Triplet Extraction)(ZeroRTE)。
比如这个句子“Their grandson was Group Captain Nicolas Tindal.” 包含了 “Military Rank”的关系,但是训练数据没有见过这类关系类别的样本。ZeroRTE 的目标就是在这个零样本的情况下仍然能够抽取三元组(Nicolas Tindal,Military Rank, Group Captain)。
为了执行 ZeroRTE,我们提出了RelationPrompt 方式,为没有见过的关系类别生成伪训练数据(Pseudo-training data)。RelationPrompt 能够利用初次见到的关系名作为语言模型的提示(Prompt),生成该关系的结构化句子样本。这类样本的结构信息标明了句子中三元组的头部实体(Head Entity)和尾部实体(Tail Entity),进而可以作为抽取模型的训练数据。

▲ 表2.1 任务对比
2.2 相关方法的局限
表 2.1 可以显示 ZeroRTE 在两个主要方面比现存的任务更有挑战性。与传统监督的关系三元组抽取(Relation Triplet Extraction)任务相比,ZeroRTE 需要模型泛化到训练中从没遇过的关系类别。与零样本关系分类的任务(Zero-Shot Relation Classification)(ZeroRC)[10] 相比,ZeroRTE 需要模型在不假设给出实体对的情况下抽取完整的关系三元组。因此,ZeroRTE 比 ZeroRC 在实际应用中更现实。目前的几种方法可以解决低资源学习问题。
远程监督(Distant Supervision)[11] 可用知识库构建大规模的关系数据集,但比人类的标注质量低,并且仅限于固定关系类别。另一种方法是设计不受约束的预测类别空间来制定任务目标 [12],例如句子相似度匹配。然而,现存的方式只对句子分类任务有效,不能直接执行三元组抽取任务。第三方向是利用带有提示(Prompt)的语言模型 [13],能让模型在低资源情况下泛化到新任务。然而,提示的方法目前仅限于比较简单的预测目标,比如句子分类或词组抽取。
2.3 任务定义
ZeroRTE 任务的目标是从训练数据集 中学习,并泛化到测试数据集 。 和 是从定义为 的原本数据集中划分的,其中 表示输入句子, 表示输出三元组, 表示数据中存在的一组关系类别。 和 数据集的关系类别组是预定义的,分别表示为 和 ,而且是不相交的 。每一个数据样本包含了输入句子 ,同时也包含一个或以上的三元组。每个三元组定义为(,,y),其中 表示头部实体, 表示尾部实体,y 表示关系类别。

以上的算法描述了 RelationPrompt 执行 ZeroRTE 任务的整体训练和预测过程。由于现存的抽取模型不能泛化到新的关系类别,我们先需要训练一个关系生成模型 ,针对测试集的关系类别生成伪训练数据 ,接着用伪训练数据 训练一个关系抽取模型 来执行 ZeroRTE。
具体地说,我们先用训练数据 来训练关系生成模型 和关系抽取模型 (1,2),接着以测试集的关系类别当作语言模型的提示来生成伪训练数据 (3)。接着,我们使用之前生成的伪训练数据 再次训练关系抽取模型 (4)。最后,我们让关系抽取模型 对测试数据的句子预测出关系三元组(5,6)。

▲ 图2.1 结构化文本格式
2.4 我们的模型
语言模型能够通过大规模的预训练,泛化到地资源的情况。因此,我们使用语言模型生成伪训练数据,以关系名称的提示作为生成的条件。不过,现存的提示方式不能支持生成三元组的信息。另一方面,结构化文本方式(Structured Text)[14] 可以使用自然文本中的特殊标记,对实体和关系的结构信息进行编码。因此,我们的工作统一了提示语言模型和结构化文本的方法,能通过语言模型提来生成带有关系三元组信息的结构化文。
如图 2.1 所示,RelationPrompt 分别有两个模型: 关系生成模型(a)和关系抽取模型(b)。如图 2.1a 所示,关系生成模型的输入是包含关系名称的提示,输出是包含句子、头部实体和尾部实体的结构化文本。我们使用 GPT-2 模型和普通的训练目标 [15] 进行训练,进而生成的样本可用于训练关系抽模型。具体来说,我们对关系抽取模型采用 BART 模型的序列到序列方法。图 2.1b 显示了输入数据如何包含上下文句子,输出格式包含头部实体、尾部实体和关系名称来形成关系三元组。我们使用普通的序列到序列学习目标 [16] 来训练模型。

▲ 图2.2 模型应用方式
我们所设计的结构化文本格式能让关系抽取模型同时支持关系三元组抽取和关系分类。如图 2.2 显示,我们可以无条件地生成带有头部实体,尾部实体和关系类别的结构化文本,对 ZeroRTE 任务做预测(a)。另外,我们能以实体对信息为条件来生成关系类别,对 ZeroRC 任务做预测(b) 。因此,我们的关系抽取模型在预测时可以支持 ZeroRTE 和 ZeroRC 任务,不需要分别的训练。
由于结构化文本格式的复杂度会影响到关系生成模型的生成质量, 我们保持生成的结构化文本最多包含一个三元组。因此,关系抽取模型在伪数据训练之后,对每一个输入句子最多预测一个三元组。为了克服这个挑战并预测多个三元组,我们进一步提出了一种生成解码方法(c)。
该方法可以在序列到序列的预测阶段枚举三元组候选并进行排名。对于头部实体、尾部实体和关系名称,我们可以在各个部分考虑多个可能的候选实体。如图 2.2c 表示,每个可能路径代表了一个三元组候选。为了筛选最合适的三元组候选,我们使用分数阈值。只有总体可能性高于得分数阈值的路径才能被预测为最终的关系三元组。
2.5 实验设置
由于 ZeroRTE 是一个新的任务,我们提供了两种基线方法。首先,利用生成方式的关系抽取模型可以在不使用生成数据的情况下抽取陌生关系类别的三元组。但是,由于训练数据和测试数据之间的领域不相关,它无法实现最佳性能。这个基线方式被称为 NoGen。
第二个基线方式是现有的 TableSequence [17] 三元组抽取模型,它用生成的数据进行训练。TableSequence 是一种传统的关系三元组抽取模型,它需要假设在训练数据中存在具有多个关系三元组的句子,才能在测试句子上抽取多个关系三元组。然而,我们生成的数据仅限于每一个句子只包含一个关系三元组。
因此,TableSequence 对于多三元组 ZeroRTE 不能很好地执行。对于 ZeroRC 任务,目前最先进的方法是 ZS-BERT 。它将句子和实体信息转换为表示,并对要预测的候选关系类别的描述文本进行匹配。然而,这种句子表示方法不能保留句子和关系的完整语义。
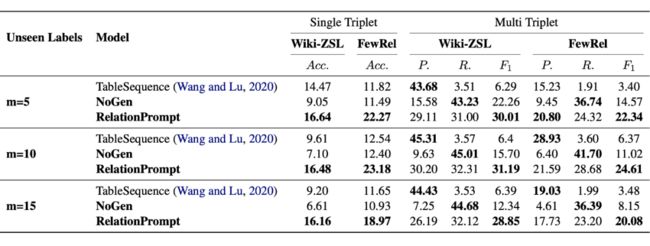
▲ 表2.2 ZeroRTE 任务结果
2.6 主要结果
对于 ZeroRTE 任务,如表 2.2 所示,RelationPrompt 方法在 FewRel [18] 和 Wiki-ZSL 数据集的总体结果始终高于基线模型。没有用生成的样本进行训练的抽取模型(NoGen)性能比较低,表明数据生成对于零样本泛化至关重要。

▲ 表2.3 ZeroRTE 任务结果
对于 ZeroRC 任务,表 2.3 显示了 RelationPrompt 对于现有方法具有一贯的优势。当看陌生关系类别集数量增加的时候,我们的方式能够保持较高的分类性能,而 ZS-BERT 方法不能很好地泛化到比较大的关系类别集。

▲ 图2.3 模型输出分析
为了进一步分析 RelationPrompt 的有效性,我们也检关系生成模型如何适应野外关系,并在图 2.3 中给出了几个例子。对于大多数关系,比如 “Investor”、“Defeated By” 和 “Currency Of”关系生成模型能够正确地推断关系的语义并生成合理的句子。然而,对于关系 “Political Partner” 的关系,生成的句子能正确地建立在政治背景,但是实体对不适合关系的语义。因此,这是一个未来的进步空间。
2.7 总结
我们介绍了零样本关系三元组抽取任务(ZeroRTE),要求模型在测试情况下抽取未见过的关系类别的三元组。与之前零样本关系分类任务(ZeroRC)相比,ZeroRTE 不需要假设实体对已经被提供。因此,ZeroRTE 在实际应用中更现实。为了执行 ZeroRTE,我们提出了关系提示的方式(RelationPrompt),利用关系名称当作语言模型的提示,来生成未见过的关系类别的新的句子样本。
为了克服句子中多个关系三元组的挑战,我们也设计了新的三元组搜索解码方法(Triplet Search Decoding)。实验结果表明,RelationPrompt 比基线模型更有效,在 ZeroRTE 任务能达到 16.5 F1 提升,在 ZeroRC 任务能达到 28.2 F1 提升。
关于作者:本文由阿里巴巴达摩院自然语言智能实验室邴立东、联培博士生谭清宇、谢耀赓共同整理。由 PaperWeekly 编辑同学做了校对和格式调整。

参考文献
[1] Yao, Yuan, et al. "DocRED: A Large-Scale Document-Level Relation Extraction Dataset." Proceedings of ACL. 2019.
[2] Mintz, Mike, et al. "Distant supervision for relation extraction without labeled data." Proceedings of ACL. 2009.
[3] Zhou, Wenxuan, et al. "Document-level relation extraction with adaptive thresholding and localized context pooling." Proceedings of AAAI. 2021.
[4] Wang, Huiyu, et al. "Axial-deeplab: Stand-alone axial-attention for panoptic segmentation." Proceedings of ECCV. Springer, 2020.
[5] Lin, Tsung-Yi, et al. "Focal loss for dense object detection." Proceedings of ICCV. 2017.
[6] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 2.7 (2015).
[7] Cheng, Qiao, et al. "HacRED: A Large-Scale Relation Extraction Dataset Toward Hard Cases in Practical Applications." Findings of ACL. 2021.
[8] Xu, Benfeng, et al. "Entity Structure Within and Throughout: Modeling Mention Dependencies for Document-Level Relation Extraction." Proceedings of the AAAI. 2021.
[9] Yankai Lin, Zhiyuan Liu, Maosong Sun, Yang Liu, and Xuan Zhu. 2015. Learning entity and relation embeddings for knowledge graph completion. In Proc. of AAAI.
[10] Chih-Yao Chen and Cheng-Te Li. 2021. Zs-bert: To- wards zero-shot relation extraction with attribute representation learning. In Proc. of NAACL.
[11] Guoliang Ji, Kang Liu, Shizhu He, and Jun Zhao. 2017. Distant supervision for relation extraction with sentence-level attention and entity descriptions. In Proc. of AAAI.
[12] Pushpankar Kumar Pushp and Muktabh Mayank Srivastava. 2017. Train once, test anywhere: Zero-shot learning for text classification. CoRR, arXiv:1712.05972.
[13] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2021. Pre- train, prompt, and predict: A systematic survey of prompting methods in natural language processing. CoRR, arXiv:2107.13586.
[14] Giovanni Paolini, Ben Athiwaratkun, Jason Krone, Jie Ma, Alessandro Achille, Rishita Anubhai, Ci- cero Nogueira dos Santos, Bing Xiang, and Stefano Soatto. 2020. Structured prediction as translation between augmented natural languages. In Proc. of ICLR.
[15] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Lan- guage models are unsupervised multitask learners. OpenAI.
[16] Mike Lewis, Yinhan Liu, Naman Goyal, Mar- jan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. Bart: Denoising sequence-to-sequence pre- training for natural language generation, translation, and comprehension. In Proc. of ACL.
[17] Jue Wang and Wei Lu. 2020. Two are better than one: Joint entity and relation extraction with table- sequence encoders. In Proc. of EMNLP.
[18] Xu Han, Hao Zhu, Pengfei Yu, Ziyun Wang, Yuan Yao, Zhiyuan Liu, and Maosong Sun. 2018. Fewrel: A large-scale supervised few-shot relation classifica- tion dataset with state-of-the-art evaluation. In Proc. of EMNLP.
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
