【Nan‘s 吴恩达深度学习笔记】第四课第一周 卷积神经网络
【Nan‘s 吴恩达深度学习笔记】第四课第一周 卷积神经网络 Convolutional Neural Networks
- 1.1 计算机视觉(Computer vision)
-
- 边缘检测
-
- 垂直边缘
- 过滤器选择
- Padding
-
- Valid卷积
- Same卷积
- 步长(Stride)
- 1.6 三维卷积
- 1.7 单层卷积网络
-
- 卷积层
- 1.8 简单卷积网络
- 1.9 池化层
-
- 最大池化(max pooling)
- 平均池化(Average pooling)
- 小结
- 卷积神经网络示例
-
- 激活值形状
- 卷积Convolution
-
- 参数共享 Parameter sharing
- 稀疏连接 Sparsity of connections
- 小结
1.1 计算机视觉(Computer vision)
计算机视觉时要面临一个挑战,就是数据的输入可能会非常大。
一般操作的都是 64×64 的小图片,实际上,它的数据量是64×64×3,因为每张图片都有 3 个颜色通道。可得知数据量为 12288,所以我们的特征向量维度为12288。这还是对于 64×64 这张真的很小的图片。
边缘检测
卷积运算是卷积神经网络最基本的组成部分,使用边缘检测作为入门样例。
垂直边缘
为了检测图像中的垂直边缘,可以构造一个 3×3矩阵。在卷积神经网络的术语中,它被称为过滤器/核(filter / kernel)。
在数学中“∗”就是卷积的标准标志,用 3×3的过滤器对这个6x6的图像进行卷积。
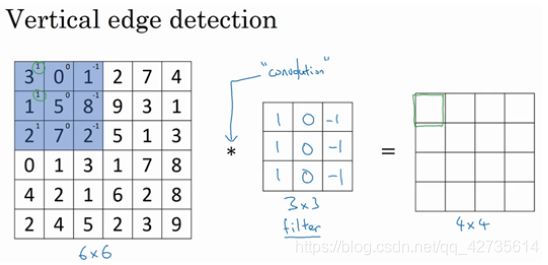
这个卷积运算的输出将会是一个 4×4 的矩阵,你可以将它看成一个 4×4 的图像。
在编程练习中,卷积不用”*“来表示,会使用一个叫 conv_forward 的函数。如果在 tensorflow 下,这个函数叫 tf.conv2d。在其他深度学习框架中, Keras 这个框架下用 Conv2D 实现卷积运算,等等。
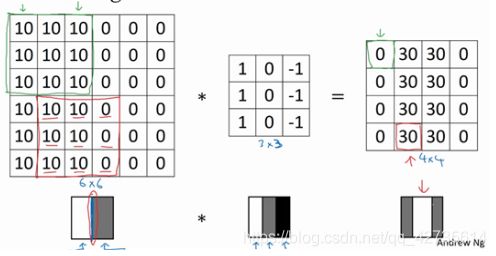
在输出图像中间的亮处,表示在图像中间有一个特别明显的垂直边缘。
我们使用 3×3的矩阵(过滤器),所以垂直边缘是一个 3×3 的区域,左边是明亮的像素,中间的并不需要考虑,右边是深色像素。在这个 6×6 图像的中间部分,明亮的像素在左边,深色的像素在右
边,就被视为一个垂直边缘。
卷积运算提供了一个方便的方法来发现图像中的垂直边缘。
过滤器选择
①、②

③sobel过滤器:优点在于增加了中间一行元素的权重,这使得结果的鲁棒性会更高一些

④Scharr过滤器
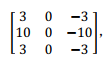
实际上也是一种垂直边缘检测,如果你将其翻转 90 度,你就能得到对应水平边缘检测。
Padding
直接卷积的缺点:
①每次做卷积操作,图像就会缩小;
②在角落或者边缘区域的像素点在输出中采用较少,意味着丢掉了图像边缘位置的许多信息。
解决方案:在卷积操作之前填充图像,在图像边缘再填充一圈图像。即一个基本的卷积操作—— padding.
如果是填充的数量,在这个案例中, = 1,因为我们在周围都填充了一个像素点,输出也就变成了( + 2 − + 1) × ( + 2 − + 1)
Valid卷积
Valid 卷积意味着不填充,p=0!
如果我们有一个 × 的图像,用 × 的过滤器做卷积,那么输出的维度就是( − + 1) × ( − + 1)。
Same卷积
意味着你填充后,你的输出大小和输入大小是一样的。
如果你有一个 × 的图像,用个像素填充边缘,输出的大小就
是这样的( + 2 − + 1) × ( + 2 − + 1)。那么 = ( − 1)/2。
当是一个奇数时,只要选择相应的填充尺寸,你就能确保得到和输入相同尺寸的输出。当然,通常是奇数。
步长(Stride)
如果你用一个 × 的过滤器卷积一个 × 的图像,你的 padding 为,步幅为,在这个例子中 = 2,你会得到一个输出,因为现在你一次移动个步子,输出于是变为 ( n + 2 p − f s + 1 ) × ( n + 2 p − f s + 1 ) (\frac{n+2p-f}{s}+1)×(\frac{n+2p-f}{s}+1) (sn+2p−f+1)×(sn+2p−f+1)
如果商不是整数,则向下取整!!
1.6 三维卷积
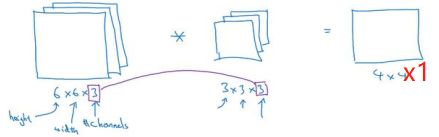
若想检测 RGB 彩色图像的特征。彩色图像如果是 6×6×3,这里的 3 指的是三个颜色通道,可以想象成三个 6×6图像的堆叠。
为了检测图像的边缘或者其他的特征,把图像跟一个三维的过滤器卷积,它的维度是 3×3×3,这个过滤器也有三层,对应红、绿、蓝三个通道。
图像的通道数必须和过滤器的通道数匹配,当输入有特定的高宽和通道数时,你的过滤器可以有不同的高,不同的宽,但是必须一样的通道数。
这个的输出会是一个 4×4 的图像,注意是 4×4×1,最后一个数不是 3 了。
如果想要检测红色通道中的垂直边缘:则只把过滤器的第一层设置,其他通道的过滤器设置为0。

如果想要检测垂直边缘和水平边缘:则对于一个6x6x3的图像用两个3x3x3的过滤器来卷积,由此可以得到两个4x4的输出。
小结:
如果你有一个 × × (通道数)的输入图像,然后卷积上一个 × × ,然后你就得到了( − + 1)× ( − + 1) × ′,这里′其实就是下一层的通道数(用的过滤器的个数)
1.7 单层卷积网络
卷积操作的输出结果是一个4×4 的矩阵,它的作用类似于前向传播中的 W [ 1 ] a [ 0 ] W^{[1]}a^{[0]} W[1]a[0]。
示例中我们有两个过滤器,也就是有两个特征,因此我们才最终得到一个 4×4×2 的输出。如果我们用了 10 个过滤器,而不是 2 个,我们最后会得到一个 4×4×10 维度的输出图像。
卷积层
[]: 过滤器大小,过滤器大小为 × ,上标[]表示层
[]: 标记 padding 的数量
[]: 标记步长
n c [ l ] n_c^{[l]} nc[l]: 过滤器的数量
输入: 某个维度的数据, × × , 为某层上的颜色通道数,也即 n H [ l − 1 ] × n W [ l − 1 ] × n c [ l − 1 ] n_H^{[l−1]} × n_W^{[l−1]} × n_c^{[l−1]} nH[l−1]×nW[l−1]×nc[l−1],因为它是上一层的激活值
输出: n H [ l ] × n W [ l ] × n c [ l ] n_H^{[l]} × n_W^{[l]} × n_c^{[l]} nH[l]×nW[l]×nc[l],图像的宽度和高度计算类似,均为: n H [ l ] n_H^{[l]} nH[l]= ⌊ n H [ l − 1 ] + 2 p [ l ] − f [ l ] s [ l ] + 1 \frac{n_H^{[l-1]}+2p^{[l]}−f^{[l]}}{s^{[l]}}+1 s[l]nH[l−1]+2p[l]−f[l]+1⌋
输出图像中的通道数量: 就是神经网络中这一层所使用的过滤器的数量。输出通道数量就是输入通道数量~
激活值Activations:
应用偏差和非线性函数之后,这一层的输出等于它的激活值[],如果有个例子,就是有个激活值的集合,那么输出[] = × n H [ l ] × n W [ l ] × n c [ l ] n_H^{[l]}× n_W^{[l]}× n_c^{[l]} nH[l]×nW[l]×nc[l]。
权重W: 权重也就是所有过滤器的集合再乘以过滤器的总数量,即 f [ l ] × f [ l ] × n c [ l − 1 ] × n c [ l ] f^{[l]}× f^{[l]}×n_c^{[l-1]}×n_c^{[l]} f[l]×f[l]×nc[l−1]×nc[l]
偏差bias: 1×1×1× n c [ l ] n_c^{[l]} nc[l]
1.8 简单卷积网络
随着神经网络计算深度不断加深,通常开始时的图像要更大一些,高度和宽度会在一段时间内保持一致,然后随着网络深度的加
深而逐渐减小,而通道数量会增加。
当输入的图像,经过多个卷积层后,从39x39x3变为7x7x40,为图片提取了 7×7×40 (1960)个特征。
此后,应对其平滑或展开成 1960 个单元,输出为一个向量,并把这个长向量填充到 softmax 回归函数/logistic回归单元中,输出最后的预测结果 y ^ \hat{y} y^.
一个典型的卷积神经网络通常有三(种)层:
①卷积层,常用 Conv 来标注
②池化层,POOL
③全连接层,FC
1.9 池化层
除了卷积层, 卷积网络也经常使用池化层来:
①缩减模型的大小
②提高计算速度
③提高所提取特征的鲁棒性
最大池化(max pooling)
把 4×4 的输入拆分成不同的区域,把这个区域用不同颜色来标记。对于 2×2的输出,输出的每个元素都是其对应颜色区域中的最大元素值。
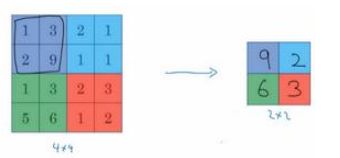
这就像是应用了一个规模为 2 的过滤器,因为我们选用的是 2×2 区域,步长是 2。
**最大化操作的功能:**只要在任何一个象限内提取到某个特征,它都会保留在最大化的池化输出里。
如果在过滤器中提取到某个特征,那么保留其最大值。如果没有提取到这个特征,可能在右上象限中不存在这个特征,那么其中的最大值也还是很小。
计算: 计算卷积层输出大小的公式同样适用于最大池化,即: ( n + 2 p − f s + 1 ) × ( n + 2 p − f s + 1 ) (\frac{n+2p-f}{s}+1)×(\frac{n+2p-f}{s}+1) (sn+2p−f+1)×(sn+2p−f+1)
这个公式也可以计算最大池化的输出大小。
平均池化(Average pooling)
并不太常用,只是将取Max,变为取平均!
不过在深度很深的神经网络,可以用平均池化来分解规模为 7×7×1000 的网络的表示层,在整个空间内求平均值,得到1×1×1000。
小结
- 最大池化比平均池化更常用
- 最大池化时,往往很少用到超参数 padding
- 池化过程中没有需要学习的参数
卷积神经网络示例
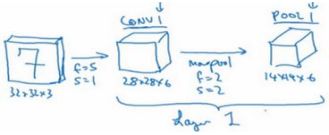
- 在计算神经网络有多少层时,通常只统计具有权重和参数的层。因为池化POOL层没有权重和参数,只有一些超参数。这里,我们把 CONV1和 POOL1 共同作为一个卷积,并标记为 Layer1。
- 在两次卷积+池化后,将 POOL2 平整化为一个大小为 400 的一维向量。可以把平整化结果想象成这样的一个神经元集合,然后利用这 400 个单元构建下一层。下一层含有 120 个单元,这就是我们第一个全连接层,标记为 FC3。
这 400 个单元与 120 个单元紧密相连,这就是全连接层,很像讲过的单神经网络层。
它的权重矩阵为[3], 维度为 120×400。 这就是所谓的“全连接”, 因为这 400 个单元与这 120 个单元的每一项连接,还有一个偏差参数。最后输出 120 个维度,因为有 120 个输出。

- 最后,用这 84 个单元填充一个 softmax 单元。如果我们想通过手写数字识别来识别手写 0-9 这 10 个数字,这个 softmax 就会有 10 个输出。
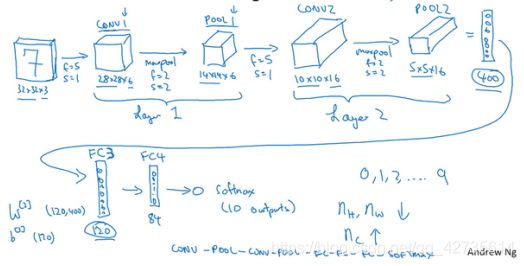
随着神经网络深度的加深,高度和宽度通常都会减少。而通道数量会增加,从 3 到 6 到 16 不断增加,然后得到一个全连接层。
**在神经网络中,一种常见模式:**一个或多个卷积后面跟随一个池化层,然后一个或多个卷积层后面再跟一个池化层,然后是几个全连接层,最后是一个 softmax。
激活值形状
①池化层和最大池化层没有参数
②卷积层的参数相对较少
③许多参数都存在于神经网络的全连接层
④随着神经网络的加深,激活值尺寸会逐渐变小,如果激活值尺寸下降太快,也会影响神经网络性能。
卷积Convolution
和只用全连接层相比,卷积层的两个主要优势在于:
①参数共享②稀疏连接
如果全连接,则会有爆炸多的参数,而卷积层的参数数量只需考虑过滤器,总体数量很少。
参数共享 Parameter sharing
每个特征检测器以及输出都可以在输入图片的不同区域中使用同样的参数,以便提取垂直边缘或其它特征。它不仅适用于边缘特征这样的低阶特征,同样适用于高阶特征。
稀疏连接 Sparsity of connections
一个输出单元(元素 0)仅与 36 个输入特征中 9 个相连接。而且其它像素值都不会对输出产生任何影响,这就是稀疏连接的概念。
小结
神经网络可以通过这两种机制减少参数,以便我们用更小的训练集来训练它,从而预防过度拟合。
卷积神经网络善于捕捉平移不变。因为神经网络的卷积结构使得即使移动几个像素,这张图片依然具有非常相似的特征,应该属于同样的输出标记。