Modeling Mention Dependencies for Document-Level Relation Extraction
Entity Structure Within and Throughout: Modeling Mention Dependencies for Document-Level Relation Extraction
http://arxiv.org/abs/2102.10249
目录
Entity Structure Within and Throughout: Modeling Mention Dependencies for Document-Level Relation Extraction
1 摘要
2 方法
2.1 Entity Structure
2.2 SSAN (Structured Self-Attention Network)
2.2.1 目的
2.2.2 步骤
2.3 Transformation Module
2.3.1 目的
2.3.2 步骤
2.4 SSAN for Relation Extraction
2.4.1 目的
2.4.2 步骤
3 实验结果
4 结论
1 摘要
实体-作为文档级关系抽取的必要元素,存在某种结构。为了更好地获取实体的结构信息,在这个框架中,我们定义了各种提及的依赖关系。为此,我们提出了SSAN模型,将这种依赖结构纳入self-attention mechanism,对传统的自注意力机制进行了修改,得到一个新型的自注意力机制,使提及之间产生依赖性。该新型的自注意力机制贯穿整个编码阶段,从而得到信息更加丰富的实体的embedding,从而进行关系抽取任务。
2 方法
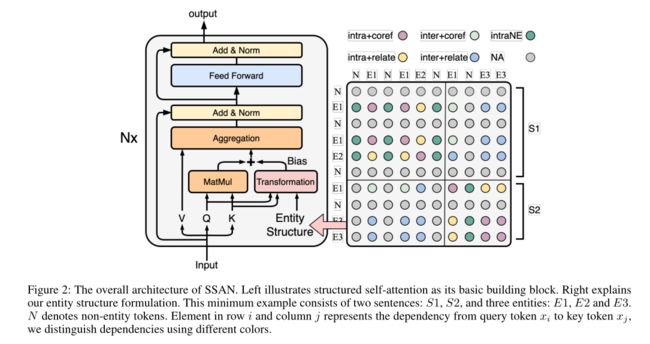
2.1 Entity Structure
实体结构描述了实体在文本上的分布以及它们之间的依赖关系。对于实体的提及之间的依赖关系,我们考虑以下两种:
-
Co-occurrence structure 共现结构:两个提及是否出现在统一句子内
-
Coreference structure 共指结构:两个提及是否指向同一实体

句内的一个提及与非实体的依赖关系结构为:intraNE
不存在关键的依赖关系:NA
所以,整个结构就形成了一个以实体为中心的邻接矩阵,其所有元素都来自一个有限的依赖集:{intra+coref,inter+coref,in-tra+relate,inter+relate,intraNE,NA}
2.2 SSAN (Structured Self-Attention Network)
an input token sequence x = (x1, x2, ..., xn)
sij ∈ {intra+coref,inter+coref,intra+relate,inter+relate,intraNE,NA}
我们这里用token-level依赖代替了mention-level的依赖,用sij表示token xi 到 token xj 的依赖关系
分为两部分,计算非结构化注意力分数和结构哈注意力分数
2.2.1 目的
得到更好的编码模型,使实体的embedding更好
2.2.2 步骤
-
token Xi的embedding作为输入,得到q,k,v的向量表示

-
计算非结构化注意力分数

-
利用模型中的Transformation结构,计算出结构化注意力分数

-
把非结构化注意力分数+结构化注意力分数,得到最终的注意力分数

-
再得到聚合后的注意力分数之后,应用softmax函数,再乘以v的向量表示,得到toekn Xi 的更新后的embedding
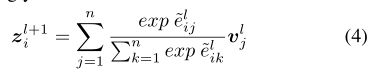
2.3 Transformation Module
2.3.1 目的
介绍Transformation模块中具体是怎么计算结构化注意力分数。
2.3.2 步骤
-
由sij组成的输入结构,我门有相应的神经网络的结构化模型
-
对于神经网络的具体设计,我们提出了两种选择:Biaffine Transformation and Decomposed Linear Transformation

-
Biaffine Transformation
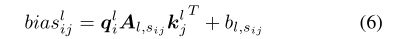
-
Decomposed Linear Transformation


2.4 SSAN for Relation Extraction
2.4.1 目的
所提出的SSAN模型以文档文本为输入,在整个编码阶段,在实体结构的指导下构建其上下文表示。在编码阶段之后,我们使用平均池化来得到目标实体的embedding。对于每个实体对,我们计算预先指定的关系概率
2.4.2 步骤
- 计算实体对是关系r的概率

- 计算损失
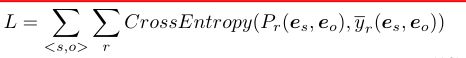
3 实验结果
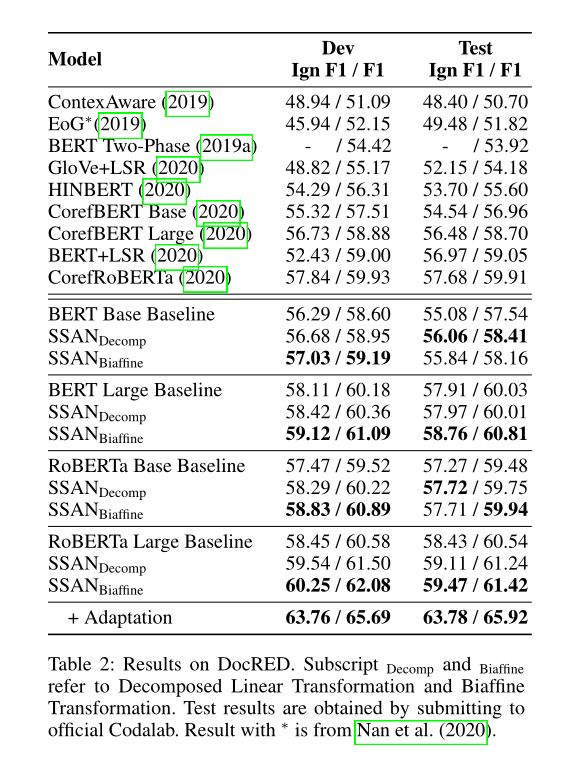
4 结论
在这项工作中,我们形式化了文档级关系抽取的实体结构。在此基础上,我们提出SSAN来有效地结合这种结构,它可以同时交互地执行实体的上下文推理和结构推理。在三个数据集上得到的性能证明了实体结构的有用性和SSAN模型的有效性。对于未来的工作,我们给出了两个有希望的方向:1)将SSAN应用于更多任务,如阅读理解,其中实体结构或语法是有用的先验信息。2) 扩展实体结构公式,以包含更多有意义的依赖项,例如基于话语结构的更复杂交互