Multi-instance Multi-label Learning for Relation Extraction-2012
Abstract
Distant supervision for relation extraction (RE) – gathering training data by aligning a database of facts with text – is an efficient approach to scale RE to thousands of different relations. However, this introduces a challeng ing learning scenario where the relation ex pressed by a pair of entities found in a sentence is unknown. For example, a sentence containing Balzac and France may express BornIn or Died, an unknown relation, or no re lation at all. Because of this, traditional super vised learning, which assumes that each example is explicitly mapped to a label, is not appropriate. We propose a novel approach to multi-instance multi-label learning for RE, which jointly models all the instances of a pair of entities in text and all their labels using a graphical model with latent variables. Our model performs competitively on two difficult domains.
关系提取 (RE) 的远程监督——通过将事实数据库与文本对齐来收集训练数据——是将 RE 扩展到数千种不同关系的有效方法。 然而,这引入了一个具有挑战性的学习场景,其中在句子中发现的一对实体所表达的关系是未知的。 例如,包含 Balzac 和 France 的句子可能表示 BornIn 或 Died、未知关系或根本没有关系。 正因为如此,传统的监督学习,假设每个例子都明确地映射到一个标签,是不合适的。 我们提出了一种用于RE多实例多标签学习的新方法,该方法使用具有潜在变量的图形模型对文本中一对实体的所有实例及其所有标签进行联合建模。 我们的模型在两个困难的领域具有竞争力。
1 Introduction
Information extraction (IE), defined as the task of extracting structured information (e.g., events, bi nary relations, etc.) from free text, has received renewed interest in the “big data” era, when petabytes of natural-language text containing thousands of different structure types are readily available. How ever, traditional supervised methods are unlikely to scale in this context, as training data is either limited or nonexistent for most of these structures. One of the most promising approaches to IE that addresses this limitation is distant supervision, which generates training data automatically by aligning a database of facts with text (Craven and Kumlien, 1999; Bunescu and Mooney, 2007).
信息提取 (IE),定义为从自由文本中提取结构化信息(例如,事件、二元关系等)的任务,在“大数据”时代重新引起了人们的兴趣,当 PB 级自然语言文本包含 数以千计的不同结构类型随时可用。 然而,传统的监督方法不太可能在这种情况下扩展,因为大多数这些结构的训练数据要么有限,要么不存在。 解决这一限制的 IE 最有前途的方法之一是远程监督,它通过将事实数据库与文本对齐来自动生成训练数据(Craven 和 Kumlien,1999 年;Bunescu 和 Mooney,2007 年)。
In this paper we focus on distant supervision for relation extraction (RE), a subproblem of IE that ad dresses the extraction of labeled relations between two named entities. Figure 1 shows a simple example for a RE domain with two labels. Distant supervision introduces two modeling challenges, which we highlight in the table. The first challenge is that some training examples obtained through this heuristic are not valid, e.g., the last sentence in Figure 1 is not a correct example for any of the known labels for the tuple. The percentage of such false positives can be quite high. For example, Riedel et al. (2010) report up to 31% of false positives in a corpus that matches Freebase relations with New York Times articles. The second challenge is that the same pair of entities may have multiple labels and it is unclear which label is instantiated by any textual mention of the given tuple. For example, in Figure 1, the tuple (Barack Obama, United States) has two valid labels: BornIn and EmployedBy, each (latently) instantiated in different sentences. In the Riedel corpus, 7.5% of the entity tuples in the training partition have more than one label.
在本文中,我们专注于关系提取 (RE) 的远程监督,这是 IE 的一个子问题,用于提取两个命名实体之间的标记关系。图 1 显示了一个带有两个标签的 RE 域的简单示例。远程监督引入了两个建模挑战,我们在表中强调了这些挑战。第一个挑战是通过这种启发式方法获得的一些训练示例无效,例如,图 1 中的最后一句话对于元组的任何已知标签都不是正确的示例。这种误报的百分比可能相当高。例如,里德尔等人。 (2010) 在将 Freebase 关系与纽约时报文章相匹配的语料库中报告了高达 31% 的误报。第二个挑战是同一对实体可能有多个标签,并且不清楚哪个标签被给定元组的任何文本提及实例化。例如,在图 1 中,元组(美国巴拉克奥巴马)有两个有效标签:BornIn 和 EmployedBy,每个标签(潜在地)在不同的句子中实例化。在 Riedel 语料库中,训练分区中 7.5% 的实体元组有多个标签。

We summarize this multi-instance multi-label (MIML) learning problem in Figure 2. In this pa per we propose a novel graphical model, which we called MIML-RE, that targets MIML learning for relation extraction. Our work makes the following contributions: (a) To our knowledge, MIML-RE is the first RE approach that jointly models both multiple instances (by modeling the latent labels assigned to instances) and multiple labels (by providing a simple method to capture dependencies between labels). For example, our model learns that certain labels tend to be generated jointly while others cannot be jointly assigned to the same tuple. (b) We show that MIML-RE performs competitively on two difficult domains.
我们在图 2 中总结了这个多实例多标签 (MIML) 学习问题。在本文中,我们提出了一种新的图形模型,我们称之为 MIML-RE,它针对 MIML 学习进行关系提取。 我们的工作做出了以下贡献:(a) 据我们所知,MIML-RE 是第一个对多个实例(通过对分配给实例的潜在标签进行建模)和多个标签(通过提供一种简单的方法来捕获依赖关系)联合建模的 RE 方法 标签之间)。 例如,我们的模型了解到某些标签往往是联合生成的,而其他标签则不能联合分配给同一个元组。 (b) 我们展示了 MIML-RE 在两个困难的领域上的表现
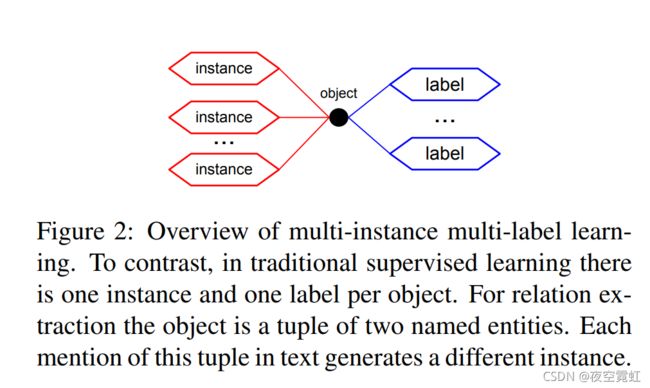
多实例多标签学习概述。 相比之下,在传统的监督学习中,每个对象有一个实例和一个标签。 对于关系提取,对象是两个命名实体的元组。 文本中每次提及此元组都会生成一个不同的实例。
2 Related Work
Distant supervision for IE was introduced by Craven and Kumlien (1999), who focused on the ex traction of binary relations between proteins and cells/tissues/diseases/drugs using the Yeast Protein Database as a source of distant supervision. Since then, the approach grew in popularity (Bunescu and Mooney, 2007; Bellare and McCallum, 2007; Wu and Weld, 2007; Mintz et al., 2009; Riedel et al., 2010; Hoffmann et al., 2011; Nguyen and Moschitti, 2011; Sun et al., 2011; Surdeanu et al., 2011a). However, most of these approaches make one or more approximations in learning. For example, most proposals heuristically transform distant super vision to traditional supervised learning (i.e., single instance single-label) (Bellare and McCallum, 2007; Wu and Weld, 2007; Mintz et al., 2009; Nguyen and Moschitti, 2011; Sun et al., 2011; Surdeanu et al., 2011a). Bunescu and Mooney (2007) and Riedel et al. (2010) model distant supervision for relation extraction as a multi-instance single-label problem, which allows multiple mentions for the same tuple but disallows more than one label per object. Our work is closest to Hoffmann et al. (2011). They address the same problem we do (binary relation extraction) with a MIML model, but they make two approximations. First, they use a deterministic model that aggregates latent instance labels into a set of labels for the corresponding tuple by OR-ing the classification results. We use instead an object level classifier that is trained jointly with the classifier that assigns latent labels to instances and can capture dependencies between labels. Second, they use a Perceptron-style additive parameter update approach, whereas we train in a Bayesian framework. We show in Section 5 that these approximations generally have a negative impact on performance.
IE 的远程监督是由 Craven 和 Kumlien (1999) 引入的,他们专注于使用酵母蛋白数据库作为远程监督的来源提取蛋白质和细胞/组织/疾病/药物之间的二元关系。从那时起,这种方法越来越受欢迎(Bunescu 和 Mooney,2007;Bellare 和 McCallum,2007;Wu 和 Weld,2007;Mintz 等,2009;Riedel 等,2010;Hoffmann 等,2011;Nguyen 和Moschitti,2011;Sun 等,2011;Surdeanu 等,2011a)。然而,这些方法中的大多数都在学习中做出了一种或多种近似。例如,大多数提议启发式地将远程超级视觉转换为传统的监督学习(即单实例单标签)(Bellare 和 McCallum,2007;Wu 和 Weld,2007;Mintz 等,2009;Nguyen 和 Moschitti,2011;Sun等,2011;Surdeanu 等,2011a)。 Bunescu 和 Mooney (2007) 和 Riedel 等人。 (2010) 将关系提取的远程监督建模为多实例单标签问题,它允许对同一元组进行多次提及,但不允许每个对象有多个标签。我们的工作最接近霍夫曼等人。 (2011)。它们解决了我们使用 MIML 模型所做的相同问题(二元关系提取),但它们做了两个近似。首先,他们使用确定性模型,通过对分类结果进行 OR 运算,将潜在实例标签聚合为对应元组的一组标签。我们使用一个对象级分类器,该分类器与分类器联合训练,该分类器为实例分配潜在标签并可以捕获标签之间的依赖关系。其次,他们使用感知器风格的附加参数更新方法,而我们在贝叶斯框架中进行训练。我们在第 5 节中表明,这些近似通常对性能有负面影响。
MIML learning has been used in fields other than natural language processing. For example, Zhou and Zhang (2007) use MIML for scene classification. In this problem, each image may be assigned multiple labels corresponding to the different scenes captured. Furthermore, each image contains a set of patches, which forms the bag of instances assigned to the given object (image). Zhou and Zhang pro[1]pose two algorithms that reduce the MIML problem to a more traditional supervised learning task. In one algorithm, for example, they convert the task to a multi-instance single-label problem by creating a separate bag for each label. Due to this, the proposed approach cannot model inter-label dependencies. Moreover, the authors make a series of approximations, e.g., they assume that each instance in a bag shares the bag’s overall label. We instead model all these issues explicitly in our approach.
MIML 学习已用于自然语言处理以外的领域。 例如,Zhou and Zhang (2007) 使用 MIML 进行场景分类。 在这个问题中,每个图像可能会被分配多个标签,对应于捕获的不同场景。 此外,每个图像都包含一组补丁,它们形成了分配给给定对象(图像)的实例包。 Zhou 和 Zhang pro 提出了两种算法,将 MIML 问题简化为更传统的监督学习任务。 例如,在一种算法中,他们通过为每个标签创建一个单独的袋子,将任务转换为多实例单标签问题。 因此,所提出的方法无法对标签间依赖性进行建模。 此外,作者进行了一系列近似,例如,他们假设包中的每个实例都共享包的整体标签。 相反,我们在我们的方法中明确地对所有这些问题进行建模。
In general, our approach belongs to the category of models that learn in the presence of incomplete or incorrect labels. There has been interest among machine learning researchers in the general problem of noisy data, especially in the area of instance-based learning. Brodley and Friedl (1999) summarize past approaches and present a simple, all-purpose method to filter out incorrect data before training. While potentially applicable to our problem, this approach is completely general and cannot incorporate our domain-specific knowledge about how the noisy data is generated.
一般来说,我们的方法属于在存在不完整或不正确标签的情况下学习的模型类别。 机器学习研究人员对噪声数据的一般问题很感兴趣,尤其是在基于实例的学习领域。 Brodley 和 Friedl (1999) 总结了过去的方法,并提出了一种简单的通用方法,可以在训练前过滤掉不正确的数据。 虽然可能适用于我们的问题,但这种方法是完全通用的,不能结合我们关于如何生成噪声数据的特定领域知识。
3 Distant Supervision for Relation Extraction 关系抽取的远程监督
Here we focus on distant supervision for the extraction of relations between two entities. We define a relation as the construct r(e1, e2), where r is the relation name, e.g., BornIn in Figure 1, and e1 and e2 are two entity names, e.g., Barack Obama and United States. Note that there are entity tuples (e1, e2) that participate in multiple relations, r1, . . . , ri . In other words, the tuple (e1, e2) is the object illustrated in Figure 2 and the different relation names are the labels. We define an entity mention as a sequence of text tokens that matches the corresponding entity name in some text, and relation mention (for a given relation r(e1, e2)) as a pair of entity mentions of e1 and e2 in the same sentence. Relation mentions thus correspond to the instances in Figure 2.1 As the latter definition indicates, we focus on the extraction of relations expressed in a single sentence. Furthermore, we assume that entity mentions are extracted by a different process, such as a named entity recognizer.
在这里,我们专注于提取两个实体之间关系的远程监督。我们将关系定义为构造 r(e1, e2),其中 r 是关系名称,例如图 1 中的 BornIn,e1 和 e2 是两个实体名称,例如 Barack Obama 和 United States。请注意,存在参与多个关系的实体元组 (e1, e2),r1, . . , ri .换句话说,元组 (e1, e2) 是图 2 中所示的对象,不同的关系名称是标签。我们将实体mention 定义为与某些文本中对应的实体名称匹配的文本标记序列,并将关系mention(对于给定的关系r(e1, e2))定义为同一句子中e1 和e2 的一对实体mention .因此,关系提及对应于图 2 中的实例,正如后一个定义所示,我们专注于提取单个句子中表达的关系。此外,我们假设实体提及是由不同的过程提取的,例如命名实体识别器。
We define the task of relation extraction as a function that takes as input a document collection (C), a set of entity mentions extracted from C (E), a set of known relation labels (L) and an extraction model, and outputs a set of relations (R) such that any of the relations extracted is supported by at least one sentence in C. To train the extraction model, we use a database of relations (D) that are instantiated at least once in C. Using distant supervision, D is aligned with sentences in C, producing relation mentions for all relations in D.
我们将关系提取的任务定义为一个函数,该函数将文档集合(C)、从 C(E)中提取的一组实体提及、一组已知的关系标签(L)和一个提取模型作为输入,并输出一个 一组关系 (R),使得提取的任何关系至少得到 C 中的一个句子的支持。为了训练提取模型,我们使用在 C 中至少实例化一次的关系数据库 (D)。使用远程监督 , D 与 C 中的句子对齐,为 D 中的所有关系产生关系提及。
4 Model
Our model assumes that each relation mention involving an entity pair has exactly one label, but allows the pair to exhibit multiple labels across different mentions. Since we do not know the actual relation label of a mention in the distantly supervised setting, we model it using a latent variable z that can take one of the k pre-specified relation labels as well as an additional NIL label, if no relation is expressed by the corresponding mention. We model the multiple relation labels an entity pair can assume using a multi-label classifier that takes as input the latent relation types of the all the mentions involving that pair. The two-layer hierarchical model is shown graphically in Figure 3, and is described more formally below. The model includes one multi-class classifier (for z) and a set of binary classifiers (for each yj ). The z classifier assigns latent labels from L to individual relation mentions or NIL if no relation is expressed by the mention. Each yj classifier decides if relation j holds for the given entity tuple, using the mention-level classifications as input. Specifically, in the figure:
我们的模型假设涉及实体对的每个关系提及只有一个标签,但允许该对在不同的提及中展示多个标签。由于我们不知道远程监督设置中提及的实际关系标签,因此我们使用潜在变量 z 对其进行建模,该变量可以采用 k 个预先指定的关系标签之一以及一个额外的 NIL 标签(如果没有关系)由相应的提及表示。我们使用多标签分类器对实体对可以假设的多个关系标签进行建模,该分类器将涉及该对的所有提及项的潜在关系类型作为输入。图 3 中以图形方式显示了两层分层模型,下面将对其进行更正式的描述。该模型包括一个多类分类器(对于 z)和一组二元分类器(对于每个 yj )。 z 分类器将 L 中的潜在标签分配给单个关系提及或 NIL,如果提及没有表达任何关系。每个 yj 分类器使用提及级别的分类作为输入,决定关系 j 是否适用于给定的实体元组。具体来说,如图:
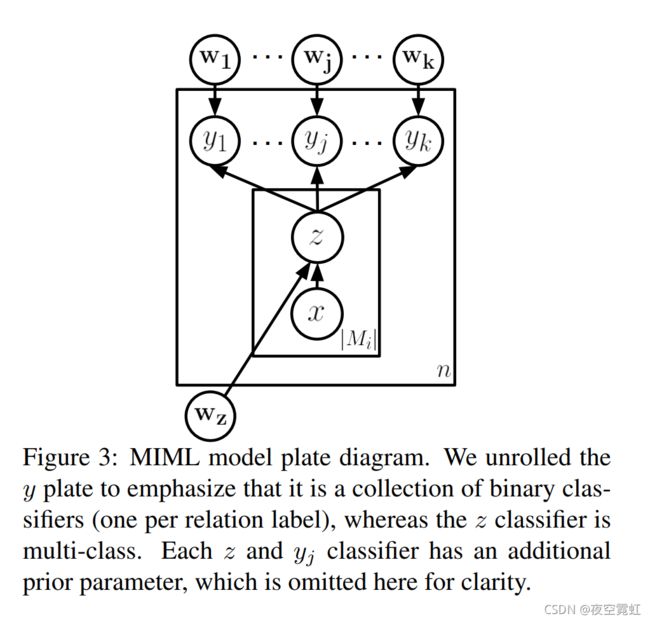
• n is the number of distinct entity tuples in D;
• Mi is the set of mentions for the ith entity pair;
• x is a sentence and z is the latent relation classification for that sentence;
• wz is the weight vector for the multi-class mention-level classifier;
• k is the number of known relation labels in L;
• yj is the top-level classification decision for the entity pair as to whether the jth relation holds;
• wj is the weight vector for the binary top-level classifier for the jth relation
• n 是 D 中不同实体元组的数量;
• Mi 是第 i 个实体对的提及集;
• x 是一个句子,z 是该句子的潜在关系分类;
• wz 是多类提及级别分类器的权重向量;
• k 是 L 中已知关系标签的数量;
• yj 是实体对关于第j 个关系是否成立的顶级分类决策;
• wj 是第 j 个关系的二元顶级分类器的权重向量
Additionally, we define Pi (Ni) as the set of all known positive (negative) relation labels for the ith entity tuple. In this paper, we construct Ni as L \Pi , but, in general, other scenarios are possible. For example, both Sun et al. (2011) and Surdeanu et al. (2011a) proposed models where Ni for the ith tuple (e1, e2) is defined as: {rj | rj (e1, ek) ∈ D, ek 6= e2, rj ∈/ Pi}, which is a subset of L \Pi . That is, entity e2 is considered a negative example for relation rj (in the context of entity e1) only if rj exists in the training data with a different value. The addition of the object-level layer (for y) is an important contribution of this work. This layer can capture information that cannot be modeled by the mention-level classifier. For example, it can learn that two relation labels (e.g., BornIn and SpouseOf) cannot be generated jointly for the same entity tuple. So, if the z classifier outputs both these labels for different mentions of the same tuple, the y layer can cancel one of them. Furthermore, the y classifiers can learn when two labels tend to appear jointly, e.g., CapitalOf and Contained between two locations, and use this occurrence as positive reinforcement for these labels. We discuss the features that implement these ideas in Section 5.
此外,我们将 Pi (Ni) 定义为第 i 个实体元组的所有已知正(负)关系标签的集合。在本文中,我们将 Ni 构造为 L \Pi ,但一般来说,其他情况也是可能的。例如,Sun 等人。 (2011) 和 Surdeanu 等人。 (2011a) 提出的模型,其中第 i 个元组 (e1, e2) 的 Ni 定义为:
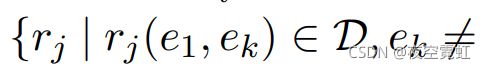
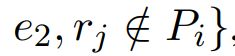
,是L \Pi 的子集。也就是说,只有当 rj 存在于具有不同值的训练数据中时,实体 e2 才被视为关系 rj 的反例(在实体 e1 的上下文中)。添加对象级层(对于 y)是这项工作的重要贡献。该层可以捕获提及级别分类器无法建模的信息。例如,它可以了解到不能为同一个实体元组联合生成两个关系标签(例如 BornIn 和 SpouseOf)。因此,如果 z 分类器为同一元组的不同提及输出这两个标签,则 y 层可以取消其中一个。此外,y 分类器可以学习何时两个标签倾向于共同出现,例如两个位置之间的 CapitalOf 和 Contained,并将这种出现用作这些标签的正强化。我们将在第 5 节中讨论实现这些想法的功能。