Machine Learning with Python Cookbook 学习笔记 第10章
Chapter 10. Dimensionality Reduction Using Feature Selection
前言
- 本笔记是针对人工智能典型算法的课程中Machine Learning with Python Cookbook的学习笔记
- 学习的实战代码都放在代码压缩包中
- 实战代码的运行环境是python3.9 numpy 1.23.1 anaconda 4.12.0
- 上一章:(97条消息) Machine Learning with Python Cookbook 学习笔记 第9章_五舍橘橘的博客-CSDN博客
- 代码仓库
- Github:yy6768/Machine-Learning-with-Python-Cookbook-notebook: 人工智能典型算法笔记 (github.com)
- Gitee:yyorange/机器学习笔记代码仓库 (gitee.com)
10.0 Introduction
-
在第9章中我们介绍了如何创建(理想状态下)训练质量模型类似的但特征维度显著减少的新特征矩阵。称为Feature Extraction
-
在本章我们将如何介绍选择高质量、信息丰富的特征并删除不太有用的特征。这称为Feature Selection(特征选择)。
-
特征选择往往主要有三种方法:filter, wrapper, and embedded.
- filter:检查特征的统计特性来选择最佳特征
- wrapper: 使用试错法来找到产生具有最高质量预测的模型的特征子集。
- embedded:选择最佳特征子集作为学习算法训练过程的一部分或扩展
- embedded与特定的学习算法密切相关,在深入研究算法本身之前很难解释它们。
-
我们在本章中仅介绍过滤器和包装器特征选择方法,将特定嵌入式方法的讨论留到深入讨论这些学习算法的章节。
10.1 Thresholding Numerical Feature Variance
- 移除方差较小的特征
- 通过设置阈值来控制最小方差达到筛选的作用
thresholdingVariance.py
# Load libraries
from sklearn import datasets
from sklearn.feature_selection import VarianceThreshold
# import some data to play with
iris = datasets.load_iris()
# 创建特征矩阵和目标向量
features = iris.data
target = iris.target
# 创建 thresholder
thresholder = VarianceThreshold(threshold=.5)
# 使用thresholder仅仅保留方差大于0.5的特征
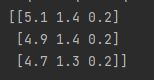
features_high_variance = thresholder.fit_transform(features)
# 打印前三个observation
print(features_high_variance[0:3])
Discussion
-
VT(variance thresholding) 是特征选择的最基本的方式之一。使用该方法的原因是我们认为方差较小的数据可能不如方差较大的数据有用。
-
v a r ( x ) = 1 n Σ i = 1 n ( x i − μ ) 2 var(x) = \frac{1}{n}\Sigma_{i=1}^{n}(x_i-\mu)^2 var(x)=n1Σi=1n(xi−μ)2
-
注意:
- 方差是不居中的。也就是说当单位不同时,VT将不再起到作用
- 阈值是一个hyperparameter。也就是需要我们人为的来制定的。在第12章,我们会学到如何判断这个方差阈值是不是一个好的阈值
-
我们可以通过
variances_查看每个特征的方差:# 查看方差 print(thresholder.fit(features).variances_)
10.2 Thresholding Binary Feature Variance
- 有一组只有分类信息的特征,希望能够删除那些方差较低的特征
- 伯努利分布的方差
binaryThresholdingVariance.py
# Load library
from sklearn.feature_selection import VarianceThreshold
# 创建的矩阵满足:
# 特征 0: 80% class 0
# 特征 1: 80% class 1
# 特征 2: 60% class 0, 40% class 1
features = [[0, 1, 0],
[0, 1, 1],
[0, 1, 0],
[0, 1, 1],
[1, 0, 0]]
# 创建thresholder,并根据伯努利分布的方差声明参数threshold
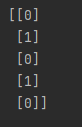
thresholder = VarianceThreshold(threshold=(.75 * (1 - .75)))
print(thresholder.fit_transform(features))
Discussion
- 伯努利分布就是二项分布在n=1的特殊情况,这种分布的方差满足 v a r ( p ) = p ( 1 − p ) var(p)=p(1-p) var(p)=p(1−p)(p为某一类的比例)
10.3 Handling Highly Correlated Features
-
部分特征高度相关的数据集
-
如果存在某些高度相关的特征,我们就可以把它去除
correlatedFeatures.py
# Load libraries
import pandas as pd
import numpy as np
# 创建一个特征矩阵,可以很明显的看出前两个特征高度线性相关
features = np.array([[1, 1, 1],
[2, 2, 0],
[3, 3, 1],
[4, 4, 0],
[5, 5, 1],
[6, 6, 0],
[7, 7, 1],
[8, 7, 0],
[9, 7, 1]])
# 特征矩阵 -> DataFrame
dataframe = pd.DataFrame(features)
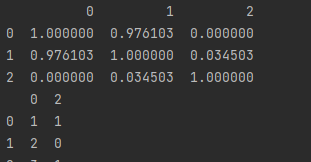
# 创建一个线性相关度的矩阵
corr_matrix = dataframe.corr().abs()
# 观察相关程度
print(corr_matrix)
# 选取这个矩阵的上三角部分(因为对称)
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape),
k=1).astype(bool))
# 寻找特征之间线性相关度大于0.95的特征
to_drop = [column for column in upper.columns if any(upper[column] > 0.95)]
# 删除这些特征
print(dataframe.drop(dataframe.columns[to_drop], axis=1).head(3))
Discussion
-
如果两个特征高度相关,那么它们包含的信息非常相似,同时包含这两个特征可能是多余的。
-
我们求出线性相关度矩阵 c o r r ( ) corr() corr()实际是一个对称矩阵,所以只需要上半部分即可
-
线性相关系数的求解 r ( X , Y ) = C O V ( X , Y ) V a r ( ∣ X ∣ V a r ∣ Y ∣ ) r(X,Y)=\frac{COV(X,Y)}{\sqrt{Var(|X|Var|Y|)}} r(X,Y)=Var(∣X∣Var∣Y∣)COV(X,Y)
10.4 Removing Irrelevant Features for Classification
- 移除分类问题中的无关变量
chi-square (χ2) statistic
irrelevantFeatures.py
# Load libraries
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2, f_classif
# 加载莺尾花数据
iris = load_iris()
features = iris.data
target = iris.target
# 分类数据变为数字
features = features.astype(int)
# 通过chi2来检验分类是否和这些特征有关
chi2_selector = SelectKBest(chi2, k=2)
features_kbest = chi2_selector.fit_transform(features, target)
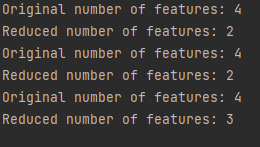
# 结果
print("Original number of features:", features.shape[1])
print("Reduced number of features:", features_kbest.shape[1])
# 选择具有很高的f-value(ANOVA方法)
fvalue_selector = SelectKBest(f_classif, k=2)
features_kbest = fvalue_selector.fit_transform(features, target)
# 结果
print("Original number of features:", features.shape[1])
print("Reduced number of features:", features_kbest.shape[1])
# 选择topn的特征
from sklearn.feature_selection import SelectPercentile
# 选择前75%
fvalue_selector = SelectPercentile(f_classif, percentile=75)
features_kbest = fvalue_selector.fit_transform(features, target)
# 结果
print("Original number of features:", features.shape[1])
print("Reduced number of features:", features_kbest.shape[1])
Discussion
-
chi2( χ 2 χ^2 χ2 统计)判断是否观测值的特征与目标值相互独立。
-
O i 是第 i 类样本的数量, E i 是如果特征与结果没有关系,样本在第 i 类的数量的期望值 O_i是第i类样本的数量,E_i是如果特征与结果没有关系,样本在第i类的数量的期望值 Oi是第i类样本的数量,Ei是如果特征与结果没有关系,样本在第i类的数量的期望值
-
χ 2 = Σ i = 1 n ( O i − E i ) 2 E i χ^2 = \Sigma_{i=1}^n \frac{(O_i-E_i)^2}{E_i} χ2=Σi=1nEi(Oi−Ei)2
-
χ 2 χ^2 χ2统计告诉您观察到的计数与如果总体中没有任何关系时您预期的计数之间存在多少差异。
-
如果目标独立于特征变量,那么它与我们的目的无关,因为它不包含我们可以用于分类的信息。另一方面,如果这两个特征高度依赖,它们可能对训练我们的模型非常有用。
-
-
使用 SelectKBest 选择具有最佳统计信息的特征。参数 k 决定了我们想要保留的特征的数量。
-
χ 2 χ^2 χ2统计量只能在两个分类向量之间计算。出于这个原因,用于特征选择的卡方要求目标向量和特征都是分类的。但是,如果我们有一个数值特征,我们可以通过首先将定量特征转换为分类特征来使用卡方技术。最后,要使用我们的卡方方法,所有值都必须是非负的。
-
如果我们有一个数值特征,我们可以使用 f_classif 来计算每个特征和目标向量的 ANOVA F 值统计量。
- f-classif检查当我们按目标向量对数值特征进行分组时,每组的均值是否显着不同。例如,如果我们有一个二元目标向量、性别和一个定量特征、测试分数,则 f-classif将告诉我们男性的平均测试分数是否不同于女性的平均测试分数。
10.5 Recursively Eliminating Features
- 自动的去选择那些最值得保留的特征
Solution
-
RFECV生成一个使用cross-validation (CV)的recursive feature elimination (RFE) -
反复的训练一个模型,每一次移除一个特征,直到模型训练效果很差,那么保留下来的特征就是我们最需要的特征
recursiveEliminating.py
# 加载库
import warnings
from sklearn.datasets import make_regression
from sklearn.feature_selection import RFECV
from sklearn import datasets, linear_model
# 丢弃警告
warnings.filterwarnings(action="ignore", module="scipy",
message="^internal gelsd")
# 生成有10000个样本,100个特征的线性回归的样本
features, target = make_regression(n_samples=10000,
n_features=100,
n_informative=2,
random_state=1)
# 创建一个线性模型
ols = linear_model.LinearRegression()
# 递归的去除特征
rfecv = RFECV(estimator=ols, step=1, scoring="neg_mean_squared_error")
rfecv.fit(features, target)
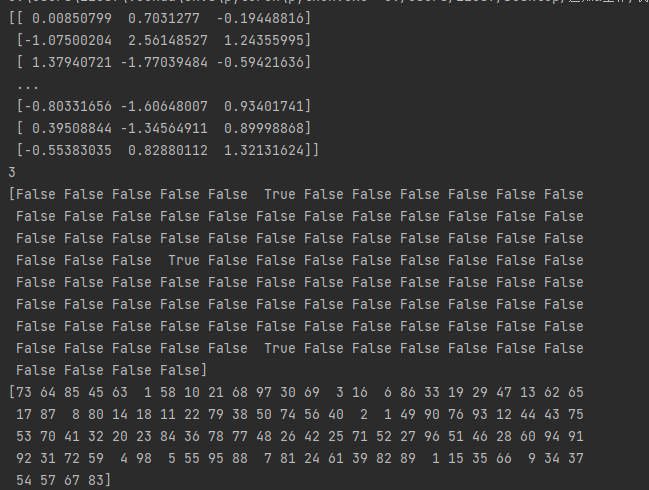
print(rfecv.transform(features))
# 查看好的特征的数量
print(rfecv.n_features_)
# 查看哪些特征应该被保留
print(rfecv.support_)
# 我们可以查看特征的排行
print(rfecv.ranking_)
Discussion
-
作者认为RFE技术是1-10章最为先进的技术(说明很重要)
-
RFE 背后的想法是重复训练一个包含一些参数(也称为权重或系数)的模型,例如线性回归或支持向量机
-
第一次训练模型时,我们包含了所有特征。然后,我们找到具有最小参数的特征(请注意,这假设特征被重新缩放或标准化),这意味着它不太重要,并从特征集中删除该特征。
-
我们应该保留多少特征?我们可以(假设地)重复这个循环,直到我们只剩下一个特征。更好的方法需要我们包含一个称为交叉验证(CV)的新概念。
大体思路:
- 给定包含 (1) 我们要预测的目标和 (2) 特征矩阵的数据,
- 我们将数据分成两组:训练集和测试集
- 我们使用训练集训练我们的模型。
- 假装不知道测试集的目标,并将我们的模型应用于测试集的特征,以预测测试集的值
- 将我们的预测目标值与真实目标值进行比较以评估我们的模型。
-
事实证明:将我们的预测目标值与真实目标值进行比较以评估我们的模型。
-
在 scikit-learn 中,带有 CV 的 RFE 是使用 RFECV 实现的,并且包含许多重要参数。
estimator:决定了我们要训练的模型类型(linear regression)step:设置在每个循环期间要丢弃的特征的数量或比例scoring:设置了我们在交叉验证期间用于评估模型的质量指标
-
查阅资料得到更详细的RFECV的信息
sklearn.feature_selection.RFECV-scikit-learn中文社区
| estimator | object 一种监督学习估计器,其fit方法通过coef_ 属性或feature_importances_属性提供有关特征重要性的信息。 |
|---|---|
| step | int or float, optional (default=1) 如果大于或等于1,则step对应于每次迭代要删除的个特征个数。如果在(0.0,1.0)之内,则step对应于每次迭代要删除的特征的百分比(向下舍入)。请注意,为了达到min_features_to_select,最后一次迭代删除的特征可能少于step。 |
| min_features_to_select | int, (default=1) 最少要选择的特征数量。即使原始特征数量与min_features_to_select之间的差不能被step整除, 也会对这些特征数进行评分。 0.20版中的新功能。 |
| cv | int, cross-validation generator or an iterable, optional 确定交叉验证拆分策略。可能的输入是: - 无,要使用默认的5倍交叉验证 - 整数,用于指定折数。 - CV分配器 - 可迭代的产生(训练,测试)拆分为索引数组。 对于整数或无输入,如果y是二分类或多分类, 则使用sklearn.model_selection.StratifiedKFold。如果估计器是分类器,或者y既不是二分类也不是多分类, 则使用sklearn.model_selection.KFold。 有关可在此处使用的各种交叉验证策略,请参阅用户指南。 在0.22版本中更改:cv无的默认值从3更改为5。 |
| scoring | string, callable or None, optional, (default=None) 字符串(参见模型评估文档)或具有scorer(estimator, X, y)签名的scorer可调用对象或函数。 |
| verbose | int, (default=0) 控制输出的详细程度。 |
| n_jobs | int or None, optional (default=None) 跨折时要并行运行的核心数。 除非在上下文中设置了joblib.parallel_backend参数,否则None表示1 。 -1表示使用所有处理器。有关更多详细信息,请参见词汇表。 |
下一章:(97条消息) Machine Learning with Python Cookbook 学习笔记 第11章_五舍橘橘的博客-CSDN博客