时间序列预测----(基于多变量深度模型)
1. 什么是多变量时序预测:
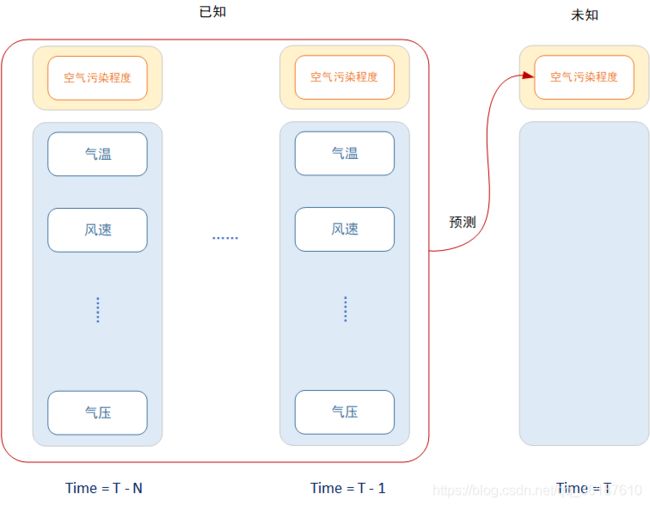
多变量时间序列预测问题可以被理解为,利用历史时刻的各项数据来预测下一个时刻的目标数据。
2. 实验数据集:
在本文中,我使用了北京市空气污染历史监测数据集来进行时序预测实验,那么时序预测任务则是利用过去一段时间所记录的温度、气压、风速以及空气污染程度等数据来预测下一时刻的空气污染程度。
数据集下载地址:http://archive.ics.uci.edu/ml/datasets/Beijing+PM2.5+Data
数据来源自位于北京的美国大使馆在2010年至2014年共5年间每小时采集的天气及空气污染指数。包括了日期、PM2.5浓度(空气污染程度)、露点、温度、风向、风速、累积小时雪量和累积小时雨量,完整特征如下:
1. No 行数
2. year 年
3. month 月
4. day 日
5. hour 小时
6. pm2.5 PM2.5浓度
7. DEWP 露点
8. TEMP 温度
9. PRES 大气压
10. cbwd 风向
11. lws 风速
12. ls 累积雪量
13. lr 累积雨量
3. 数据预处理:
我们使用 Pandas 库函数来进行数据读取和处理:
import pandas as pd
# 加载数据
def parse(x):
return datetime.strptime(x, '%Y %m %d %H')
dataset = pd.read_csv('./PRSA_data_2010.1.1-2014.12.31.csv', parse_dates=[['year', 'month', 'day', 'hour']], index_col=0, date_parser=parse)
# 删除无用列
dataset.drop('No', axis=1, inplace=True)
# 修改剩余列名称
dataset.columns = ['pollution', 'dew', 'temp', 'press', 'wnd_dir', 'wnd_spd', 'snow', 'rain']
dataset.index.name = 'date'
# 将所有空值替换为0
dataset['pollution'].fillna(0, inplace=True)
# 删除前24小时行(因为有缺失)
dataset = dataset[24:]
# 将离散类别型特征数值化
encoder = LabelEncoder()
dataset['wnd_dir'] = encoder.fit_transform(dataset['wnd_dir'])
# 打印前5行
print(dataset.head(5))
打印出来的经处理后的数据集的前五行:
pollution dew temp press wnd_dir wnd_spd snow rain
date
2010-01-02 00:00:00 129.0 -16 -4.0 1020.0 2 1.79 0 0
2010-01-02 01:00:00 148.0 -15 -4.0 1020.0 2 2.68 0 0
2010-01-02 02:00:00 159.0 -11 -5.0 1021.0 2 3.57 0 0
2010-01-02 03:00:00 181.0 -7 -5.0 1022.0 2 5.36 1 0
2010-01-02 04:00:00 138.0 -7 -5.0 1022.0 2 6.25 2 0
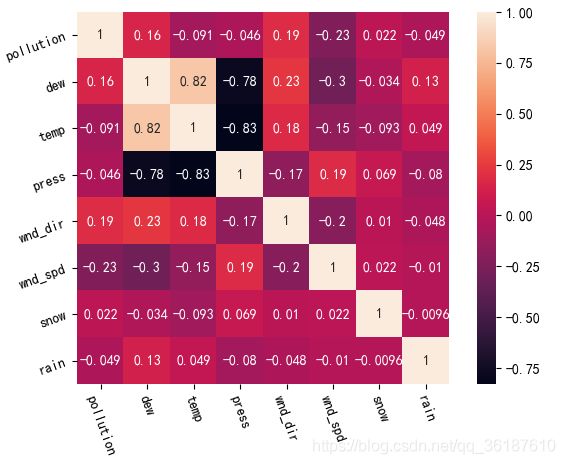
计算各个属性之间的相关性,并绘图:
hitmapTemp = dataset[list(dataset.columns)]
hitmapData = hitmapTemp.corr()
sns.heatmap(hitmapData, vmax=1, square=True, annot=True)
# plt.savefig('./figs/Correlation-Matrix.png')
plt.xticks(rotation=-70)
plt.yticks(rotation=20)
plt.show()
相关矩阵如下图所示,可见空气污染程度与各个特征之间并没有明显相关性(最大与风向呈0.19正相关,风速呈-0.23负相关)。
在建模之前,我们还需要将数据进行归一化处理,从而消除量纲,减少量纲对模型带来的影响。
values = dataset.values
# 确保所有数据是浮点数类型
values = values.astype('float32')
# # 对特征标准化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled = scaler.fit_transform(values)
# 分离出特征和标签
data = scaled
label = scaled[:, 0]
由于我们需要利用 (T-N, T-1) 时间段的数据作为训练数据,T 时刻的空气污染程度作为标签,因此,我们使用时间滑窗来制造训练数据和标签对,示意图如下:
假设当我们设的时间窗口长度为2时,也就是利用历史两期数据来预测下一期的数据:
d a t a = ( X 1 , Y 1 , X 2 , Y 2 ) l a b e l = Y 3 \begin{aligned} data=& (X_1, Y_1,X_2,Y_2)\\ label=& Y_{3} \end{aligned} data=label=(X1,Y1,X2,Y2)Y3

d a t a = ( X 2 , Y 2 , X 3 , Y 3 ) l a b e l = Y 4 \begin{aligned} data=& (X_2, Y_2,X_3,Y_3)\\ label=& Y_{4} \end{aligned} data=label=(X2,Y2,X3,Y3)Y4

d a t a = ( X 3 , Y 3 , X 4 , Y 4 ) l a b e l = Y 5 \begin{aligned} data=& (X_3, Y_3,X_4,Y_4)\\ label=& Y_{5} \end{aligned} data=label=(X3,Y3,X4,Y4)Y5
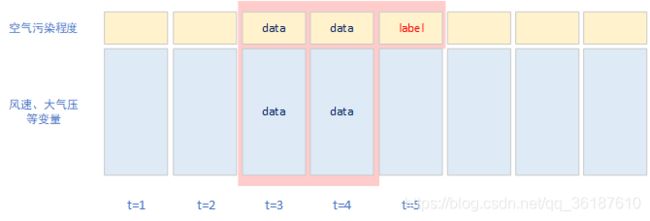
依次类推,生成训练数据-标签对,代码实现如下:
def generate_pair(x, y, ts):
length = len(x)
start, end = 0, length - ts
data = []
label = []
for i in range(end):
data.append(x[i: i+ts, :])
label.append(y[i+ts])
return np.array(data, dtype=np.float64), np.array(label, dtype=np.float64)
data, label = generate_pair(data, label, ts=72)
4. 对时序数据进行建模:
在经过了上述一系列处理后,我们便可以得到能直接拿来建模的数据啦~
在本文中,我们使用 LSTM 进行时序建模预测,LSTM是循环神经网络的一种变体,在这就不具体介绍LSTM了,有需要的可以自行去了解。 知乎专栏:人人都能看懂的LSTM

代码如下:
# 划分数据集
train_test_split = int(0.7 * len(label))
train_X = data[0: train_test_split]
train_y = label[0: train_test_split]
test_X = data
test_y = label
from keras.layers import Dropout
model = Sequential()
model.add(LSTM(128, input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(Dropout(0.6))
model.add(Dense(1))
model.compile(loss='mae', optimizer='adam')
# 训练模型
if __name__ == '__main__':
history = model.fit(train_X, train_y, epochs=200, batch_size=64, validation_data=(test_X, test_y), verbose=2, shuffle=True)
# 开始预测
yhat = model.predict(test_X)
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()
# 绘图
plt.plot(yhat[train_test_split-50: train_test_split+50])
plt.plot(test_y[train_test_split-50: train_test_split+50])
plt.axvline(x=50, c="r", ls="--", lw=2)
plt.legend(['预测数据', '真实数据', '开始预测'])
plt.grid()
plt.show()
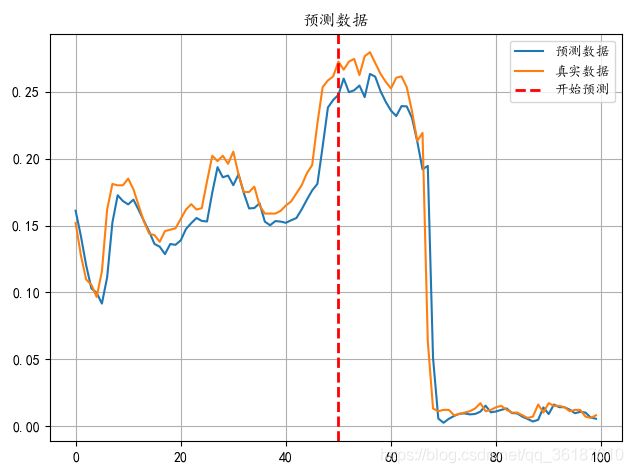
绘制出来的拟合曲线:
5. 思考:
观察上面绘制出来的拟合曲线的波峰波谷,可以发现,预测的曲线存在一个时间的延时,也就是说,预测数据其实是上一个时刻的真实数据。那么该如何消除这个时延性呢?