机器学习笔记--SVM实现人脸识别
目录
1--前言
2--项目路径总览
3--数据集处理
4--SVM实现人脸识别
5--参考
6--补充说明
1--前言
①模式识别作业
②数据集:ORL Database of Faces
③原理:SVM
2--项目路径总览
3--数据集处理
①代码:
from PIL import Image
import numpy as np
def gen_dataset(data_path):
Label_Num = 40 # 40类
Image_Num = 10 # 10图
data = []
for i in range(Label_Num): # 遍历40类
for j in range(Image_Num): # 遍历每个类的10张图片
# 根据路径读取图片
img_path = data_path + 's{}/{}.pgm'.format(i+1, j+1)
img = Image.open(img_path)
img = np.array(img) # 转换成numpy数组格式
img = np.reshape(img, (1, -1)) # reshape 10304
label = np.array(i, ndmin=2) # label [x] (取值: 0~39)
img_label = np.column_stack((img, label)) # img和label 10305 最后一位为样本的label
data.append(img_label) # 存储当前样本数据
return data
if __name__ == "__main__":
data_path = './dataset/ORL/att_faces/orl_faces/'
save_path = './dataset/dataset.npy'
dataset = gen_dataset(data_path)
np.save(save_path, dataset)②运行gen_data.py生成数据集文件dataset.npy
python gen_data.py4--SVM实现人脸识别
①调用sklearn提供的api:
import numpy as np
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report
def load_dataset(data_path):
dataset = np.load(data_path).reshape((400, -1)) # 导入数据集,shape: 400 10305
data = dataset[:, :10304] # img_data
label = dataset[:, -1:] # label
return data, label
if __name__ == "__main__":
data_path = './dataset/dataset.npy'
data, label = load_dataset(data_path) # 导入数据
# 划分训练集和验证集
x_train, x_test, y_train, y_test = train_test_split(data, label, test_size=0.3, random_state=13)
# 利用PCA进行降维(20维)
pca = PCA(n_components=20)
x_train = pca.fit_transform(x_train)
# 调用SVM API进行训练, C为正则化系数
svm_clf = SVC(C=100)
svm_clf.fit(x_train, y_train)
# 对验证集进行相同的处理
x_test = pca.transform(x_test)
label = svm_clf.predict(x_test) # 预测标签
score = svm_clf.score(x_test, y_test) # 计算准确率
report = classification_report(y_test, label) # 报告
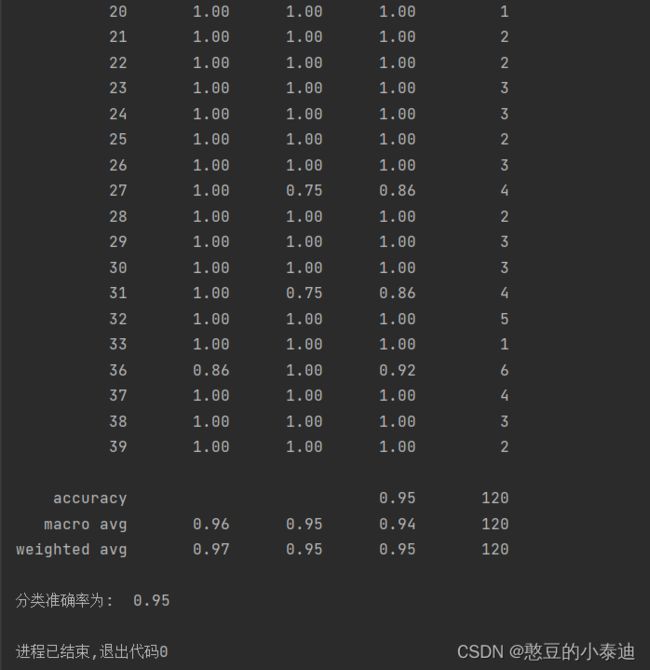
print('分类详细报告如下: \n', report)
print('分类准确率为: ', score)②调用api程序的执行结果:
python svm.py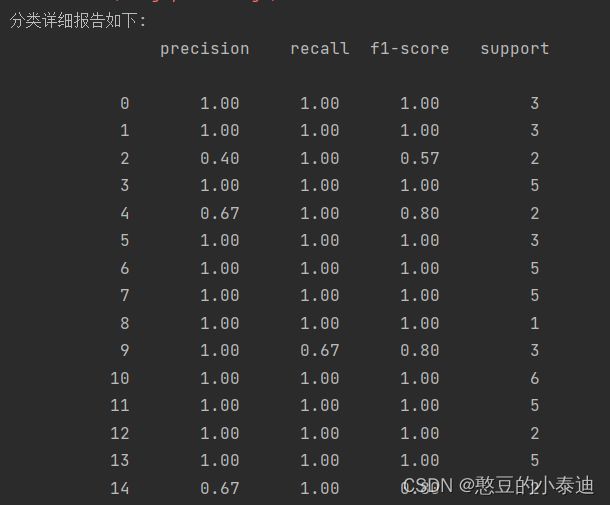
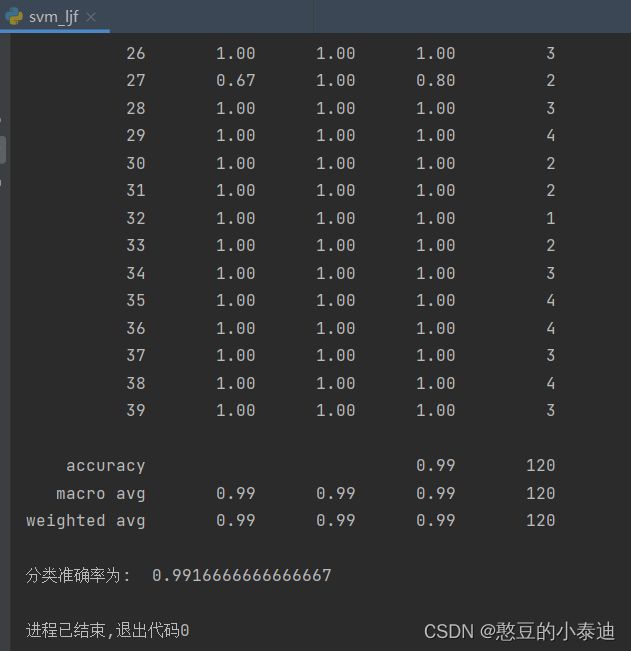
③load_dataset()和train_test_split可以用以下函数代替,在ORL数据集上测试发现准确率有随机性,但相差不大;
def split_dataset(data_path, proportion = 0.7):
dataset = np.load(data_path)# 导入数据集,shape: 400 1 10305
sample_sum = dataset.shape[0] # 样本数
dataset = dataset.reshape((sample_sum, -1)) # 400 10305
np.random.shuffle(dataset) # 打乱数据
train_dataset = dataset[:int(sample_sum*proportion), :] # 70%为训练集
test_dataset = dataset[int(sample_sum*proportion):, :] # 30%为验证集
x_train = train_dataset[:, :10304] # 训练data
y_train = train_dataset[:, -1:] # 训练label
x_test = test_dataset[:, :10304] # 验证data
y_test = test_dataset[:, -1:] # 验证label
return x_train, x_test, y_train, y_test
if __name__ == "__main__":
data_path = './dataset/dataset.npy'
proportion = 0.7 # 训练集比例
# 划分训练集和验证集
x_train, x_test, y_train, y_test = split_dataset(data_path = data_path, proportion = 0.7)
#……
#……
④关于使用sklearn自带的pca进行训练集和验证集的降维,相关疑问可以参考这两篇博客:博客1
和博客2:
pca = PCA(n_components=20)
x_train = pca.fit_transform(x_train)上述代码可以用以下代码代替,博主在ORL数据集上测试发现两者符号相反,数值相等;但由于后面对验证集进行pca降维时,需要用到训练集的参数进行标准化(原因见博客2),所以建议还是使用sklearn自带的api进行降维处理;
# 利用PCA进行降维(20维)
n_components = 20
means = np.mean(x_train, axis=0)
x_train = x_train - means
U, S, V = linalg.svd(new_x_train, full_matrices=False)
x_train = U[:, :n_components] * S[:n_components]5--参考
参考链接1
6--补充说明
未完待续!