mmdetection(v1.0rc0)-GTX2080遇到的问题-安装测试保存

./tools/dist_train.sh configs/faster_rcnn_r50_fpn_1x.py 3
test.py configs/faster_rcnn_r50_fpn_1x.py checkpoints/epoch_1000.pth
--out temp_pred/ouput.pkl --eval
train.py configs/faster_rcnn_r50_fpn_1x.py --gpus 1 --seed 10
test.py configs/faster_rcnn_r50_fpn_1x.py checkpoints/gray_epoch_5000.pth
--out temp_pred/gray_luosi.pkl --eval bbox --show
#./tools/dist_test.sh configs/mask_rcnn_r50_fpn_1x.py work_dirs/mask_rcnn_r50_fpn_1x/epoch_380.pth 1 --eval bbox segm --out temp_pred/maskrcnn_out.pkl
bbox(输出评估)
#/home/spple/paddle/vis-project/mmdetection/mmdetection/train.py/datasets/loader/build_loader.py
#/home/spple/paddle/vis-project/mmdetection/mmdetection/mmdet/datasets/custom.py
#/home/spple/paddle/vis-project/mmdetection/mmdetection/mmdet/datasets/coco.py (public:custom.py)
# COCO目标检测测评指标
# https://www.jianshu.com/p/d7a06a720a2b
# COCO 数据集的使用
# https://www.cnblogs.com/q735613050/p/8969452.html
# 将COCO2017标注文件中的bbox显示在图片上
# https://blog.csdn.net/zhuoyuezai/article/details/84315113
# COCO 数据集中目标检测标注说明
# https://blog.vistart.me/description-of-object-detection-in-coco-dataset/
# coco 数据集显示查看 完整代码*****************
# https://blog.csdn.net/yang332233/article/details/97289906如果我们不是使用distributed分布式pytorch模式。那么就可以修改一些东西可以进行指定GPU训练,设置一个--gpus
比如 让123训练,但0不参与
tools/train.py
parser.add_argument( '--gpus', #type=int, default=1, help='number of gpus to use ' '(only applicable to non-distributed training)') if args.work_dir is not None: cfg.work_dir = args.work_dir if args.resume_from is not None: cfg.resume_from = args.resume_from cfg.gpus = str(args.gpus).split(',') os.environ['CUDA_VISIBLE_DEVICES'] = str(args.gpus) if args.autoscale_lr: # apply the linear scaling rule (https://arxiv.org/abs/1706.02677) cfg.optimizer['lr'] = cfg.optimizer['lr'] * len(cfg.gpus) / 8mmdet/apis/train.py
def _non_dist_train(model, dataset, cfg, validate=False): # prepare data loaders data_loaders = [ build_dataloader( dataset, cfg.data.imgs_per_gpu, cfg.data.workers_per_gpu, cfg.gpus, dist=False) ] # put model on gpus #model = MMDataParallel(model, device_ids=range(cfg.gpus)).cuda() model = MMDataParallel(model, device_ids=cfg.gpus).cuda() # build runner optimizer = build_optimizer(model, cfg.optimizer) runner = Runner(model, batch_processor, optimizer, cfg.work_dir, cfg.log_level)再改下shell文件就可以了
#!/usr/bin/env bash #PYTHON=${PYTHON:-"python"} PYTHON=/root/train/results/ynh_copy/anaconda3_py3.7/bin/python CONFIG=$1 GPUS=$2 GPUNAME=$3 nohup $PYTHON -m torch.distributed.launch --nproc_per_node=$GPUS \ $(dirname "$0")/train.py $CONFIG --gpus $GPUNAME --launcher pytorch ${@:4} > out8_tiesi10.26.log 2>&1 &./tools/dist_train.sh configs/mask_rcnn_r50_fpn_1x.py 4 0,1,2,3
#没有成功
CUDA_VISIBLE_DEVICES=2,3 ./tools/dist_train.sh configs/faster_rcnn_r50_fpn_1x.py 2
#成功
./tools/dist_train.sh configs/faster_rcnn_r50_fpn_1x.py 2 2,3
修改mmdetection/tools/train.py
parser.add_argument(
'--gpus',
#type=int,
default=1,
help='number of gpus to use '
'(only applicable to non-distributed training)')
cfg.gpus = str(args.gpus).split(',')
os.environ['CUDA_VISIBLE_DEVICES'] = str(args.gpus)
if args.autoscale_lr:
# apply the linear scaling rule (https://arxiv.org/abs/1706.02677)
cfg.optimizer['lr'] = cfg.optimizer['lr'] * len(cfg.gpus) / 8
修改mmdetection/mmdet/apis/train.py
因为我们没有分布式训练:
def train_detector(model,
dataset,
cfg,
distributed=False,
validate=False,
logger=None):
if logger is None:
logger = get_root_logger(cfg.log_level)
# start training
if distributed:
_dist_train(model, dataset, cfg, validate=validate)
else:
_non_dist_train(model, dataset, cfg, validate=validate)
只修改_non_dist_train
def _non_dist_train(model, dataset, cfg, validate=False):
# put model on gpus
#model = MMDataParallel(model, device_ids=range(cfg.gpus)).cuda()
model = MMDataParallel(model, device_ids=cfg.gpus).cuda()

如果是一个机器双开mmdetection
为每个进程添加不同的端口号,不然会报错:
RuntimeError: Address already in use
#!/usr/bin/env bash
#PYTHON=${PYTHON:-"python"}
PYTHON=/root/train/results/ynh_copy/anaconda3_py3.7/bin/python
CONFIG=$1
GPUS=$2
GPUNAME=$3
nohup $PYTHON -m torch.distributed.launch --nproc_per_node=$GPUS --master_port 8666 \
$(dirname "$0")/train.py $CONFIG --gpus $GPUNAME --launcher pytorch ${@:4} > out4.log 2>&1 &参考:
https://github.com/open-mmlab/mmdetection/issues/261 主要
https://github.com/open-mmlab/mmdetection/issues/878
训练和测试灰度图(三通道)
vim mmdet/datasets/custom.py
def prepare_train_img(self, idx):
img_info = self.img_infos[idx]
# load image
img = mmcv.imread(osp.join(self.img_prefix, img_info['filename']))
###yangninghua
import cv2
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
# corruption
if self.corruption is not None:
img = corrupt(
img,
severity=self.corruption_severity,
corruption_name=self.corruption)
# load proposals if necessary
def prepare_test_img(self, idx):
"""Prepare an image for testing (multi-scale and flipping)"""
img_info = self.img_infos[idx]
img = mmcv.imread(osp.join(self.img_prefix, img_info['filename']))
# corruption
import cv2
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
if self.corruption is not None:
img = corrupt(
img,
severity=self.corruption_severity,
corruption_name=self.corruption)
# load proposals if necessary
if self.proposals is not None:
proposal = self.proposals[idx][:self.num_max_proposals]
if not (proposal.shape[1] == 4 or proposal.shape[1] == 5):
raise AssertionError(
'proposals should have shapes (n, 4) or (n, 5), '
'but found {}'.format(proposal.shape))
else:
proposal = None由于读入的是BGR
后续会转换:
mmdet/datasets transforms.py
class ImageTransform(object):
"""Preprocess an image.
1. rescale the image to expected size
2. normalize the image
3. flip the image (if needed)
4. pad the image (if needed)
5. transpose to (c, h, w)
"""
def __init__(self,
mean=(0, 0, 0),
std=(1, 1, 1),
to_rgb=True,
size_divisor=None):
self.mean = np.array(mean, dtype=np.float32)
self.std = np.array(std, dtype=np.float32)
self.to_rgb = to_rgb
self.size_divisor = size_divisor
def __call__(self, img, scale, flip=False, keep_ratio=True):
if keep_ratio:
img, scale_factor = mmcv.imrescale(img, scale, return_scale=True)
else:
img, w_scale, h_scale = mmcv.imresize(
img, scale, return_scale=True)
scale_factor = np.array([w_scale, h_scale, w_scale, h_scale],
dtype=np.float32)
img_shape = img.shape
img = mmcv.imnormalize(img, self.mean, self.std, self.to_rgb)
if flip:
img = mmcv.imflip(img)
if self.size_divisor is not None:
img = mmcv.impad_to_multiple(img, self.size_divisor)
pad_shape = img.shape
else:
pad_shape = img_shape
img = img.transpose(2, 0, 1)
return img, img_shape, pad_shape, scale_factor
mmdetection注释
https://github.com/ming71/mmdetection-annotated
显示coco
# coding=UTF-8
from pycocotools.coco import COCO
import skimage.io as io
import matplotlib.pyplot as plt
import pylab
import cv2
import os
from skimage.io import imsave
import numpy as np
pylab.rcParams['figure.figsize'] = (8.0, 10.0)
img_path = '/home/spple/paddle/DeepGlint/deepglint-adv/data/luosi_detection/coco/val2017/'
annFile = '/home/spple/paddle/DeepGlint/deepglint-adv/data/luosi_detection/coco/annotations/instances_val2017.json'
if not os.path.exists('anno_image_coco/'):
os.makedirs('anno_image_coco/')
def draw_rectangle(coordinates, image, image_name):
for coordinate in coordinates:
left = np.rint(coordinate[0])
right = np.rint(coordinate[1])
top = np.rint(coordinate[2])
bottom = np.rint(coordinate[3])
# 左上角坐标, 右下角坐标
cv2.rectangle(image,
(int(left), int(right)),
(int(top), int(bottom)),
(0, 255, 0),
2)
imsave('anno_image_coco/' + image_name, image)
# 初始化标注数据的 COCO api
coco = COCO(annFile)
# display COCO categories and supercategories
cats = coco.loadCats(coco.getCatIds())
nms = [cat['name'] for cat in cats]
# print('COCO categories: \n{}\n'.format(' '.join(nms)))
nms = set([cat['supercategory'] for cat in cats])
# print('COCO supercategories: \n{}'.format(' '.join(nms)))
catIds_1 = coco.getCatIds(catNms=['luosi'])
imgIds_1 = coco.getImgIds(catIds=catIds_1)
# imgIds_1 = coco.getImgIds(catIds=[1,2])
# img_path = 'data/train/'
img_list = os.listdir(img_path)
# for i in range(len(img_list)):
for i in range(len(imgIds_1)):
# imgIds = i+1
# img = coco.loadImgs(imgIds)[0]
# image_name = img['file_name']
# print(img)
img = coco.loadImgs(imgIds_1[i])[0]
image_name = img['file_name']
# 加载并显示图片
# I = io.imread('%s/%s' % (img_path, img['file_name']))
# plt.axis('off')
# plt.imshow(I)
# plt.show()
# catIds=[] 说明展示所有类别的box,也可以指定类别
annIds = coco.getAnnIds(imgIds=img['id'], catIds=[], iscrowd=None)
anns = coco.loadAnns(annIds)
coco.showAnns(anns)
# print(anns)
coordinates = []
img_raw = cv2.imread(os.path.join(img_path, image_name))
img_raw = cv2.cvtColor(img_raw, cv2.COLOR_BGR2RGB)
for j in range(len(anns)):
coordinate = []
coordinate.append(anns[j]['bbox'][0])
coordinate.append(anns[j]['bbox'][1] + anns[j]['bbox'][3])
coordinate.append(anns[j]['bbox'][0] + anns[j]['bbox'][2])
coordinate.append(anns[j]['bbox'][1])
# print(coordinate)
coordinates.append(coordinate)
# print(coordinates)
draw_rectangle(coordinates, img_raw, image_name)
关于ignore的问题:
pycocotools/cocoeval.py
# convert ground truth to mask if iouType == 'segm'
if p.iouType == 'segm':
_toMask(gts, self.cocoGt)
_toMask(dts, self.cocoDt)
# set ignore flag
for gt in gts:
gt['ignore'] = gt['ignore'] if 'ignore' in gt else 0
gt['ignore'] = 'iscrowd' in gt and gt['iscrowd']
if p.iouType == 'keypoints':
gt['ignore'] = (gt['num_keypoints'] == 0) or gt['ignore']
self._gts = defaultdict(list) # gt for evaluation
self._dts = defaultdict(list) # dt for evaluation
for gt in gts:
self._gts[gt['image_id'], gt['category_id']].append(gt)
for dt in dts:
self._dts[dt['image_id'], dt['category_id']].append(dt)
self.evalImgs = defaultdict(list) # per-image per-category evaluation results
self.eval = {} 
为了保证ignore,ignore=1时, iscrowd=1,ignore=0时, iscrowd=0
ignore在训练的时候:
mmdetection/mmdet/models/detectors/two_stage.py
def forward_train(self,
img,
img_meta,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None,
gt_masks=None,
proposals=None):
x = self.extract_feat(img)
losses = dict()
# RPN forward and loss
if self.with_rpn:
rpn_outs = self.rpn_head(x)
rpn_loss_inputs = rpn_outs + (gt_bboxes, img_meta,
self.train_cfg.rpn)
rpn_losses = self.rpn_head.loss(
*rpn_loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
losses.update(rpn_losses)
proposal_cfg = self.train_cfg.get('rpn_proposal',
self.test_cfg.rpn)
proposal_inputs = rpn_outs + (img_meta, proposal_cfg)
proposal_list = self.rpn_head.get_bboxes(*proposal_inputs)
else:
proposal_list = proposals
# assign gts and sample proposals
if self.with_bbox or self.with_mask:
bbox_assigner = build_assigner(self.train_cfg.rcnn.assigner)
bbox_sampler = build_sampler(
self.train_cfg.rcnn.sampler, context=self)
num_imgs = img.size(0)
if gt_bboxes_ignore is None:
gt_bboxes_ignore = [None for _ in range(num_imgs)]
sampling_results = []
for i in range(num_imgs):
assign_result = bbox_assigner.assign(proposal_list[i],
gt_bboxes[i],
gt_bboxes_ignore[i],
gt_labels[i])
sampling_result = bbox_sampler.sample(
assign_result,
proposal_list[i],
gt_bboxes[i],
gt_labels[i],
feats=[lvl_feat[i][None] for lvl_feat in x])
sampling_results.append(sampling_result)mmdetection不需要json的测试:
import os
path = "/home/spple/paddle/DeepGlint/deepglint-adv/data/luosi_detection/coco_100/train2017/"
imgs = os.listdir(path)
config_file = 'configs/faster_rcnn_r50_fpn_1x.py'
checkpoint_file = 'checkpoints/epoch_1000.pth'
model = init_detector(config_file, checkpoint_file, device='cuda:0')
for i in range(len(imgs)):
imgs[i] = path + imgs[i]
for i, result in enumerate(inference_detector(model, imgs)):
show_result(imgs[i], result, model.CLASSES, out_file='./ynh_pred/result_{}.jpg'.format(i+1))mmdetection COCO or VOC的类别数目:
mmdetection/mmdet/datasets/coco.py
def load_annotations(self, ann_file):
self.coco = COCO(ann_file)
self.cat_ids = self.coco.getCatIds()
self.cat2label = {
cat_id: i + 1
for i, cat_id in enumerate(self.cat_ids)
}
self.img_ids = self.coco.getImgIds()
img_infos = []
for i in self.img_ids:
info = self.coco.loadImgs([i])[0]
info['filename'] = info['file_name']
img_infos.append(info)
return img_infos
cat_ids
: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 27, 28, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 67, 70, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 84, 85, 86, 87, 88, 89, 90]
cat2label
: {1: 1, 2: 2, 3: 3, 4: 4, 5: 5, 6: 6, 7: 7, 8: 8, 9: 9, 10: 10, 11: 11, 13: 12, 14: 13, 15: 14, 16: 15, 17: 16, 18: 17, 19: 18, 20: 19, 21: 20, 22: 21, 23: 22, 24: 23, 25: 24, 27: 25, 28: 26, 31: 27, 32: 28, 33: 29, 34: 30, 35: 31, 36: 32, 37: 33, 38: 34, 39: 35, 40: 36, 41: 37, 42: 38, 43: 39, 44: 40, 46: 41, 47: 42, 48: 43, 49: 44, 50: 45, 51: 46, 52: 47, 53: 48, 54: 49, 55: 50, 56: 51, 57: 52, 58: 53, 59: 54, 60: 55, 61: 56, 62: 57, 63: 58, 64: 59, 65: 60, 67: 61, 70: 62, 72: 63, 73: 64, 74: 65, 75: 66, 76: 67, 77: 68, 78: 69, 79: 70, 80: 71, 81: 72, 82: 73, 84: 74, 85: 75, 86: 76, 87: 77, 88: 78, 89: 79, 90: 80} CLASSES = ('person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic_light', 'fire_hydrant',
'stop_sign', 'parking_meter', 'bench', 'bird', 'cat', 'dog',
'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe',
'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports_ball', 'kite', 'baseball_bat',
'baseball_glove', 'skateboard', 'surfboard', 'tennis_racket',
'bottle', 'wine_glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot',
'hot_dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted_plant', 'bed', 'dining_table', 'toilet', 'tv', 'laptop',
'mouse', 'remote', 'keyboard', 'cell_phone', 'microwave',
'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock',
'vase', 'scissors', 'teddy_bear', 'hair_drier', 'toothbrush')faster_rcnn_r50_fpn_1x.py:
这里值得注意的是,如果是mask-rcnn:
还有一个:mask_head
mask_head=dict( type='FCNMaskHead', num_convs=4, in_channels=256, conv_out_channels=256, num_classes=81, loss_mask=dict( type='CrossEntropyLoss', use_mask=True, loss_weight=1.0)))还需要将mask-head改为相应的类别数目:
num_classes=81
FasterRCNN(
(backbone): ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
)
(neck): FPN(
(lateral_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
)
(1): ConvModule(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
)
(2): ConvModule(
(conv): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
)
(3): ConvModule(
(conv): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
)
)
(fpn_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(2): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(3): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
(rpn_head): RPNHead(
(loss_cls): CrossEntropyLoss()
(loss_bbox): SmoothL1Loss()
(rpn_conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(rpn_cls): Conv2d(256, 3, kernel_size=(1, 1), stride=(1, 1))
(rpn_reg): Conv2d(256, 12, kernel_size=(1, 1), stride=(1, 1))
)
(bbox_roi_extractor): SingleRoIExtractor(
(roi_layers): ModuleList(
(0): RoIAlign(out_size=7, spatial_scale=0.25, sample_num=2, use_torchvision=False)
(1): RoIAlign(out_size=7, spatial_scale=0.125, sample_num=2, use_torchvision=False)
(2): RoIAlign(out_size=7, spatial_scale=0.0625, sample_num=2, use_torchvision=False)
(3): RoIAlign(out_size=7, spatial_scale=0.03125, sample_num=2, use_torchvision=False)
)
)
(bbox_head): SharedFCBBoxHead(
(loss_cls): CrossEntropyLoss()
(loss_bbox): SmoothL1Loss()
(fc_cls): Linear(in_features=1024, out_features=81, bias=True)
(fc_reg): Linear(in_features=1024, out_features=324, bias=True)
(shared_convs): ModuleList()
(shared_fcs): ModuleList(
(0): Linear(in_features=12544, out_features=1024, bias=True)
(1): Linear(in_features=1024, out_features=1024, bias=True)
)
(cls_convs): ModuleList()
(cls_fcs): ModuleList()
(reg_convs): ModuleList()
(reg_fcs): ModuleList()
(relu): ReLU(inplace)
)
)mAP详解及VOC和COCO mAP的不同之处
mAP详解及VOC和COCO mAP的不同之处
https://blog.csdn.net/xskxushaokai/article/details/89419025
浅谈VOC数据集的mAP的计算过程
https://blog.csdn.net/Blateyang/article/details/81054881
VOC与COCO常用训练集含义
https://blog.csdn.net/xunan003/article/details/89186927
csv to coco
csv to voc
labelme to coco
labelme to voc
http://www.spytensor.com/index.php/archives/48/
https://github.com/spytensor/prepare_detection_dataset

https://github.com/wucng/TensorExpand/tree/master/TensorExpand/Object%20detection/Data_interface/MSCOCO

#!/usr/bin/env bash
#PYTHON=${PYTHON:-"python"}
PYTHON=/root/train/results/ynh_copy/anaconda3_py3.7/bin/python
CONFIG=$1
GPUS=$2
nohup $PYTHON -m torch.distributed.launch --nproc_per_node=$GPUS \
$(dirname "$0")/train.py $CONFIG --launcher pytorch ${@:3} > out1.log 2>&1 &
./tools/dist_train.sh configs/mask_rcnn_r50_fpn_1x.py 3 faster_rcnn_r50_fpn_1x.py中
设置多少次保存一次.pth
checkpoint_config = dict(interval=1)GPU捉襟见肘还想训练大批量模型?谁说不可以
https://www.sohu.com/a/260007852_129720
python -m torch.distributed.launch
遇到问题:
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
解决地址:
https://www.cnblogs.com/walter-xh/p/11586507.html
From rank 0: start training, time:2019-09-26 13:20:13
From rank 1: start training, time:2019-09-26 13:20:13
From rank 0: Outside: input size torch.Size([15, 5]), output size torch.Size([15, 2])
From rank 1: Outside: input size torch.Size([15, 5]), output size torch.Size([15, 2])
From rank 0: Outside: input size torch.Size([15, 5]), output size torch.Size([15, 2])
From rank 1: Outside: input size torch.Size([15, 5]), output size torch.Size([15, 2])
From rank 1: Outside: input size torch.Size([15, 5]), output size torch.Size([15, 2])From rank 0: Outside: input size torch.Size([15, 5]), output size torch.Size([15, 2])
From rank 0: Outside: input size torch.Size([5, 5]), output size torch.Size([5, 2])
From rank 0: end training, time: 2019-09-26 13:20:17
From rank 1: Outside: input size torch.Size([5, 5]), output size torch.Size([5, 2])
From rank 1: end training, time: 2019-09-26 13:20:17
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
我直接将测试果贴上来,可以看出有点乱,是由于多进程并行导致的问题,仔细看可以看出有两个进程并行训练,每个进程处理半个batch数据。最后的OMP_NUM_THREADS 信息是pytorch lanch的时候打印的,翻译过来就是我没有指定OMP多线程的数目,它为了防止系统过负荷,所以贴心的帮我设置为了1,原码参考.https://blog.csdn.net/hajlyx/article/details/85991400
https://blog.csdn.net/hajlyx/article/category/8282410
深度学习目标检测工具箱mmdetection,训练自己的数据
mmdetection的configs中的各项参数具体解释
pytorch中实现深度学习网络的训练和推断——以yolov3为例
https://www.jianshu.com/u/68297d697be9
mmdetection源码阅读笔记(3)--Train and Test
mmdetection源码阅读笔记(2)--Loss
mmdetection源码阅读笔记(0)--创建模型
mmdetection源码阅读笔记(1)--创建网络
转载自:https://blog.csdn.net/hajlyx/article/details/83542167
深度学习目标检测工具箱mmdetection,训练自己的数据
2019.05.26更新了网盘里的demo.py文件,现在的demo应该可以匹配官方的最新代码了。
2019.02.22上传多个mmdetection模型,检测器包括Faster-RCNN、Mask-RCNN、RetinaNet,backbone包括Resnet-50、Resnet-101、ResNext-101,网盘链接:mmdetection(密码:dpyl)
mmdetection的configs中的各项参数具体解释:
faster_rcnn_r50_fpn_1x.py配置文件
基于resnet50的backbone,有着5个fpn特征层的faster-RCNN目标检测网络,训练迭代次数为标准的12次epoch,下面逐条解释其含义
# model settings
model = dict(
type='FasterRCNN', # model类型
pretrained='modelzoo://resnet50', # 预训练模型:imagenet-resnet50
backbone=dict(
type='ResNet', # backbone类型
depth=50, # 网络层数
num_stages=4, # resnet的stage数量
out_indices=(0, 1, 2, 3), # 输出的stage的序号
frozen_stages=1, # 冻结的stage数量,即该stage不更新参数,-1表示所有的stage都更新参数
style='pytorch'), # 网络风格:如果设置pytorch,则stride为2的层是conv3x3的卷积层;如果设置caffe,则stride为2的层是第一个conv1x1的卷积层
neck=dict(
type='FPN', # neck类型
in_channels=[256, 512, 1024, 2048], # 输入的各个stage的通道数
out_channels=256, # 输出的特征层的通道数
num_outs=5), # 输出的特征层的数量
rpn_head=dict(
type='RPNHead', # RPN网络类型
in_channels=256, # RPN网络的输入通道数
feat_channels=256, # 特征层的通道数
anchor_scales=[8], # 生成的anchor的baselen,baselen = sqrt(w*h),w和h为anchor的宽和高
anchor_ratios=[0.5, 1.0, 2.0], # anchor的宽高比
anchor_strides=[4, 8, 16, 32, 64], # 在每个特征层上的anchor的步长(对应于原图)
target_means=[.0, .0, .0, .0], # 均值
target_stds=[1.0, 1.0, 1.0, 1.0], # 方差
use_sigmoid_cls=True), # 是否使用sigmoid来进行分类,如果False则使用softmax来分类
bbox_roi_extractor=dict(
type='SingleRoIExtractor', # RoIExtractor类型
roi_layer=dict(type='RoIAlign', out_size=7, sample_num=2), # ROI具体参数:ROI类型为ROIalign,输出尺寸为7,sample数为2
out_channels=256, # 输出通道数
featmap_strides=[4, 8, 16, 32]), # 特征图的步长
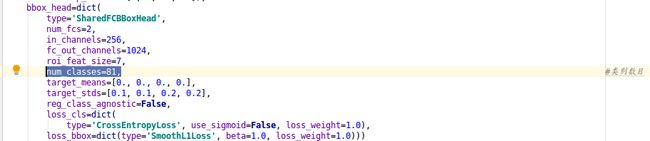
bbox_head=dict(
type='SharedFCBBoxHead', # 全连接层类型
num_fcs=2, # 全连接层数量
in_channels=256, # 输入通道数
fc_out_channels=1024, # 输出通道数
roi_feat_size=7, # ROI特征层尺寸
num_classes=81, # 分类器的类别数量+1,+1是因为多了一个背景的类别
target_means=[0., 0., 0., 0.], # 均值
target_stds=[0.1, 0.1, 0.2, 0.2], # 方差
reg_class_agnostic=False)) # 是否采用class_agnostic的方式来预测,class_agnostic表示输出bbox时只考虑其是否为前景,后续分类的时候再根据该bbox在网络中的类别得分来分类,也就是说一个框可以对应多个类别
# model training and testing settings
train_cfg = dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner', # RPN网络的正负样本划分
pos_iou_thr=0.7, # 正样本的iou阈值
neg_iou_thr=0.3, # 负样本的iou阈值
min_pos_iou=0.3, # 正样本的iou最小值。如果assign给ground truth的anchors中最大的IOU低于0.3,则忽略所有的anchors,否则保留最大IOU的anchor
ignore_iof_thr=-1), # 忽略bbox的阈值,当ground truth中包含需要忽略的bbox时使用,-1表示不忽略
sampler=dict(
type='RandomSampler', # 正负样本提取器类型
num=256, # 需提取的正负样本数量
pos_fraction=0.5, # 正样本比例
neg_pos_ub=-1, # 最大负样本比例,大于该比例的负样本忽略,-1表示不忽略
add_gt_as_proposals=False), # 把ground truth加入proposal作为正样本
allowed_border=0, # 允许在bbox周围外扩一定的像素
pos_weight=-1, # 正样本权重,-1表示不改变原始的权重
smoothl1_beta=1 / 9.0, # 平滑L1系数
debug=False), # debug模式
rcnn=dict(
assigner=dict(
type='MaxIoUAssigner', # RCNN网络正负样本划分
pos_iou_thr=0.5, # 正样本的iou阈值
neg_iou_thr=0.5, # 负样本的iou阈值
min_pos_iou=0.5, # 正样本的iou最小值。如果assign给ground truth的anchors中最大的IOU低于0.3,则忽略所有的anchors,否则保留最大IOU的anchor
ignore_iof_thr=-1), # 忽略bbox的阈值,当ground truth中包含需要忽略的bbox时使用,-1表示不忽略
sampler=dict(
type='RandomSampler', # 正负样本提取器类型
num=512, # 需提取的正负样本数量
pos_fraction=0.25, # 正样本比例
neg_pos_ub=-1, # 最大负样本比例,大于该比例的负样本忽略,-1表示不忽略
add_gt_as_proposals=True), # 把ground truth加入proposal作为正样本
pos_weight=-1, # 正样本权重,-1表示不改变原始的权重
debug=False)) # debug模式
test_cfg = dict(
rpn=dict( # 推断时的RPN参数
nms_across_levels=False, # 在所有的fpn层内做nms
nms_pre=2000, # 在nms之前保留的的得分最高的proposal数量
nms_post=2000, # 在nms之后保留的的得分最高的proposal数量
max_num=2000, # 在后处理完成之后保留的proposal数量
nms_thr=0.7, # nms阈值
min_bbox_size=0), # 最小bbox尺寸
rcnn=dict(
score_thr=0.05, nms=dict(type='nms', iou_thr=0.5), max_per_img=100) # max_per_img表示最终输出的det bbox数量
# soft-nms is also supported for rcnn testing
# e.g., nms=dict(type='soft_nms', iou_thr=0.5, min_score=0.05) # soft_nms参数
)
# dataset settings
dataset_type = 'CocoDataset' # 数据集类型
data_root = 'data/coco/' # 数据集根目录
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True) # 输入图像初始化,减去均值mean并处以方差std,to_rgb表示将bgr转为rgb
data = dict(
imgs_per_gpu=2, # 每个gpu计算的图像数量
workers_per_gpu=2, # 每个gpu分配的线程数
train=dict(
type=dataset_type, # 数据集类型
ann_file=data_root + 'annotations/instances_train2017.json', # 数据集annotation路径
img_prefix=data_root + 'train2017/', # 数据集的图片路径
img_scale=(1333, 800), # 输入图像尺寸,最大边1333,最小边800
img_norm_cfg=img_norm_cfg, # 图像初始化参数
size_divisor=32, # 对图像进行resize时的最小单位,32表示所有的图像都会被resize成32的倍数
flip_ratio=0.5, # 图像的随机左右翻转的概率
with_mask=False, # 训练时附带mask
with_crowd=True, # 训练时附带difficult的样本
with_label=True), # 训练时附带label
val=dict(
type=dataset_type, # 同上
ann_file=data_root + 'annotations/instances_val2017.json', # 同上
img_prefix=data_root + 'val2017/', # 同上
img_scale=(1333, 800), # 同上
img_norm_cfg=img_norm_cfg, # 同上
size_divisor=32, # 同上
flip_ratio=0, # 同上
with_mask=False, # 同上
with_crowd=True, # 同上
with_label=True), # 同上
test=dict(
type=dataset_type, # 同上
ann_file=data_root + 'annotations/instances_val2017.json', # 同上
img_prefix=data_root + 'val2017/', # 同上
img_scale=(1333, 800), # 同上
img_norm_cfg=img_norm_cfg, # 同上
size_divisor=32, # 同上
flip_ratio=0, # 同上
with_mask=False, # 同上
with_label=False, # 同上
test_mode=True)) # 同上
# optimizer
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001) # 优化参数,lr为学习率,momentum为动量因子,weight_decay为权重衰减因子
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2)) # 梯度均衡参数
# learning policy
lr_config = dict(
policy='step', # 优化策略
warmup='linear', # 初始的学习率增加的策略,linear为线性增加
warmup_iters=500, # 在初始的500次迭代中学习率逐渐增加
warmup_ratio=1.0 / 3, # 起始的学习率
step=[8, 11]) # 在第8和11个epoch时降低学习率
checkpoint_config = dict(interval=1) # 每1个epoch存储一次模型
# yapf:disable
log_config = dict(
interval=50, # 每50个batch输出一次信息
hooks=[
dict(type='TextLoggerHook'), # 控制台输出信息的风格
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
# runtime settings
total_epochs = 12 # 最大epoch数
dist_params = dict(backend='nccl') # 分布式参数
log_level = 'INFO' # 输出信息的完整度级别
work_dir = './work_dirs/faster_rcnn_r50_fpn_1x' # log文件和模型文件存储路径
load_from = None # 加载模型的路径,None表示从预训练模型加载
resume_from = None # 恢复训练模型的路径
workflow = [('train', 1)] # 当前工作区名称
NCCL2


https://blog.csdn.net/hanchan94/article/details/80265922
https://developer.nvidia.com/nccl/nccl-download
sudo apt install libnccl2 libnccl-dev
需要下载deb安装
pytorch1.1.0
https://blog.csdn.net/qian99/article/details/86716505
GTX 2080 需要 CUDA10.0以上版本
且安装torch方式:
/root/train/results/ynh_copy/anaconda3_py3.7/bin/python -mpip install torch -f https://download.pytorch.org/whl/cu100/
下载model
https://github.com/open-mmlab/mmdetection/blob/master/docs/MODEL_ZOO.md
https://s3.ap-northeast-2.amazonaws.com/open-mmlab/mmdetection/models/mask_rcnn_r50_fpn_1x_20181010-069fa190.pthhttps://open-mmlab.oss-cn-beijing.aliyuncs.com/mmdetection/models/mask_rcnn_r50_fpn_1x_20181010-069fa190.pth
切换Python
Ubuntu14.0遇到 错误,只能切换到Python3.7才好使
保存jpg(检测,分割)
configs/faster_rcnn_r50_fpn_1x.py checkpoints/faster_rcnn_r50_fpn_1x_20181010-3d1b3351.pth --show
configs/mask_rcnn_r50_fpn_1x.py checkpoints/mask_rcnn_r50_fpn_1x_20181010-069fa190.pth --show
在test.py中:
# build the dataloader # TODO: support multiple images per gpu (only minor changes are needed) dataset = build_dataset(cfg.data.test) ids = dataset.img_infos data_loader = build_dataloader( dataset, imgs_per_gpu=1, workers_per_gpu=cfg.data.workers_per_gpu, dist=distributed, shuffle=False) # build the model and load checkpoint model = build_detector(cfg.model, train_cfg=None, test_cfg=cfg.test_cfg) fp16_cfg = cfg.get('fp16', None) if fp16_cfg is not None: wrap_fp16_model(model) checkpoint = load_checkpoint(model, args.checkpoint, map_location='cpu') # old versions did not save class info in checkpoints, this walkaround is # for backward compatibility if 'CLASSES' in checkpoint['meta']: model.CLASSES = checkpoint['meta']['CLASSES'] else: model.CLASSES = dataset.CLASSES if not distributed: model = MMDataParallel(model, device_ids=[0]) outputs = single_gpu_test(model, data_loader, args.show, ids) else: model = MMDistributedDataParallel(model.cuda()) outputs = multi_gpu_test(model, data_loader, args.tmpdir)
def single_gpu_test(model, data_loader, show=False, ids=None): model.eval() results = [] dataset = data_loader.dataset prog_bar = mmcv.ProgressBar(len(dataset)) for i, data in enumerate(data_loader): with torch.no_grad(): result = model(return_loss=False, rescale=not show, **data) results.append(result) if show: temp = ids[i] temp = temp['file_name'] model.module.show_result(data, result, dataset.img_norm_cfg, ids=temp) batch_size = data['img'][0].size(0) for _ in range(batch_size): prog_bar.update() return results
因为是 faster_rcnn_r50_fpn_1x.py
继承自:


在base.py中:
def show_result(self,
data,
result,
img_norm_cfg,
dataset=None,
score_thr=0.3,
ids=None):
if isinstance(result, tuple):
bbox_result, segm_result = result
else:
bbox_result, segm_result = result, None
img_tensor = data['img'][0]
img_metas = data['img_meta'][0].data[0]
imgs = tensor2imgs(img_tensor, **img_norm_cfg)
assert len(imgs) == len(img_metas)
if dataset is None:
class_names = self.CLASSES
elif isinstance(dataset, str):
class_names = get_classes(dataset)
elif isinstance(dataset, (list, tuple)):
class_names = dataset
else:
raise TypeError(
'dataset must be a valid dataset name or a sequence'
' of class names, not {}'.format(type(dataset)))
for img, img_meta in zip(imgs, img_metas):
h, w, _ = img_meta['img_shape']
img_show = img[:h, :w, :]
bboxes = np.vstack(bbox_result)
# draw segmentation masks
if segm_result is not None:
segms = mmcv.concat_list(segm_result)
inds = np.where(bboxes[:, -1] > score_thr)[0]
for i in inds:
color_mask = np.random.randint(
0, 256, (1, 3), dtype=np.uint8)
mask = maskUtils.decode(segms[i]).astype(np.bool)
img_show[mask] = img_show[mask] * 0.5 + color_mask * 0.5
# draw bounding boxes
labels = [
np.full(bbox.shape[0], i, dtype=np.int32)
for i, bbox in enumerate(bbox_result)
]
labels = np.concatenate(labels)
filename = None
if ids is not None:
filename="./ynh_pred/"+str(ids)
mmcv.imshow_det_bboxes(
img_show,
bboxes,
labels,
class_names=class_names,
score_thr=score_thr,
out_file=filename)修改可以保存到 "./ynh_pred/"
或者:new2020新改
def single_gpu_test(model, data_loader, show=False):
model.eval()
results = []
dataset = data_loader.dataset
prog_bar = mmcv.ProgressBar(len(dataset))
for i, data in enumerate(data_loader):
with torch.no_grad():
result = model(return_loss=False, rescale=not show, **data)
results.append(result)
name = data['img_meta'][0].data
name2 = name[0][0]['filename']
name3 = name2.split("/")[-1]
#[0]['filename']
savepath = "./save_vis/" + name3
if show:
model.module.show_result(data, result, score_thr=0.9, out_file = savepath)
batch_size = data['img'][0].size(0)
for _ in range(batch_size):
prog_bar.update()
return results保存jpg(检测显示ground truth,分割)
test.py:
mycoco = True
if mycoco:
groundtruth = dataset.coco
scale_test = cfg.data.test['img_scale']
else:
groundtruth=None
scale_test=None
if not distributed:
model = MMDataParallel(model, device_ids=[0])
outputs = single_gpu_test(model, data_loader, args.show, ids, groundtruth, scale_test)
else:
model = MMDistributedDataParallel(model.cuda())
outputs = multi_gpu_test(model, data_loader, args.tmpdir)def single_gpu_test(model, data_loader, show=False, ids=None, groundtruth=None, scale_test=None):
model.eval()
results = []
dataset = data_loader.dataset
prog_bar = mmcv.ProgressBar(len(dataset))
for i, data in enumerate(data_loader):
with torch.no_grad():
result = model(return_loss=False, rescale=not show, **data)
results.append(result)
if show:
if groundtruth is not None or scale_test is not None:
catIds_1 = groundtruth.getCatIds(catNms=['shachepian'])
imgIds_1 = groundtruth.getImgIds(catIds=catIds_1)
#temp = ids[i]
#temp = temp['file_name']
img = groundtruth.loadImgs(imgIds_1[i])[0]
image_name = img['file_name']
annIds = groundtruth.getAnnIds(imgIds=img['id'], catIds=[], iscrowd=None)
anns = groundtruth.loadAnns(annIds)
ori_hW = data['img_meta'][0].data[0][0]['ori_shape']
ori_hW = (int(ori_hW[0]), int(ori_hW[1]))
#ori_hW = (int(img['height']),int(img['width']))
else:
temp = ids[i]
image_name = temp['file_name']
anns = None
scale_test = None
ori_hW = None
model.module.show_result(data, result, dataset.img_norm_cfg, ids=image_name, groundtruth=anns, scale_test=scale_test, ori_hW=ori_hW)
batch_size = data['img'][0].size(0)
for _ in range(batch_size):
prog_bar.update()
return results在base.py中:mmdetection/mmdet/models/detectors/base.py
def show_result(self,
data,
result,
img_norm_cfg,
dataset=None,
score_thr=0.3,
ids=None,
groundtruth=None,
scale_test=None,
ori_hW=None):
if isinstance(result, tuple):
bbox_result, segm_result = result
else:
bbox_result, segm_result = result, None
img_tensor = data['img'][0]
img_metas = data['img_meta'][0].data[0]
imgs = tensor2imgs(img_tensor, **img_norm_cfg)
assert len(imgs) == len(img_metas)
if dataset is None:
class_names = self.CLASSES
elif isinstance(dataset, str):
class_names = get_classes(dataset)
elif isinstance(dataset, (list, tuple)):
class_names = dataset
else:
raise TypeError(
'dataset must be a valid dataset name or a sequence'
' of class names, not {}'.format(type(dataset)))
for img, img_meta in zip(imgs, img_metas):
h, w, _ = img_meta['img_shape']
img_show = img[:h, :w, :]
bboxes = np.vstack(bbox_result)
# draw segmentation masks
if segm_result is not None:
segms = mmcv.concat_list(segm_result)
inds = np.where(bboxes[:, -1] > score_thr)[0]
for i in inds:
color_mask = np.random.randint(
0, 256, (1, 3), dtype=np.uint8)
mask = maskUtils.decode(segms[i]).astype(np.bool)
img_show[mask] = img_show[mask] * 0.5 + color_mask * 0.5
# draw bounding boxes
labels = [
np.full(bbox.shape[0], i, dtype=np.int32)
for i, bbox in enumerate(bbox_result)
]
labels = np.concatenate(labels)
filename = None
if ids is not None:
filename="./ynh_pred/"+str(ids)
debug_info = False
if debug_info:
print("\n")
print("ids",str(ids))
if (groundtruth is not None) or (scale_test is not None) or (ori_hW is not None):
# np.ndarray
import cv2
# img_scale = (1333, 800),
img_shape = img_show.shape
h1, w1, c1 = img_shape
#if ori_hW[1]>ori_hW[0]:
# dw,dh=ori_hW[1],ori_hW[0]
#else:
#dw, dh = ori_hW[0], ori_hW[1]
dh, dw = ori_hW[0], ori_hW[1]
hh, ww = dh / h1, dw / w1
if debug_info:
print("h1, w1, c1",h1, w1, c1)
print("ori_hW[0]", dh, dw)
print("hh, ww", hh, ww)
for key in range(len(groundtruth)):
bbox = groundtruth[key]['bbox']
x, y, w, h = bbox[0],bbox[1],bbox[2],bbox[3]
if debug_info:
print("x1, y1, w1, h1", x, y, w, h)
x, y, w, h = int(x), int(y), int(w), int(h)
x, y, w, h = int(x/ww), int(y/hh), int(w/ww), int(h/hh)
if debug_info:
print("x2, y2, w2, h2", x, y, w, h)
#ignore = groundtruth[key]['ignore']
ignore = groundtruth[key]['iscrowd']
if int(ignore) == 0:
cv2.rectangle(img_show, (x, y), (x + w -1, y + h -1), (0, 0, 255), 2) #red
else:
cv2.rectangle(img_show, (x, y), (x + w -1, y + h -1), (0, 255, 255), 2) #yello这边还有可能出错,就是json文件中的
img_info['height'], img_info['width'] 有可能写错,所以改用img的shape#ori_shape=(img_info['height'], img_info['width'], 3),
ori_shape=(temp[0], temp[1], 3),最后那一块
def prepare_test_img(self, idx):
"""Prepare an image for testing (multi-scale and flipping)"""
img_info = self.img_infos[idx]
img = mmcv.imread(osp.join(self.img_prefix, img_info['filename']))
###yangninghua
import cv2
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
# corruption
if self.corruption is not None:
img = corrupt(
img,
severity=self.corruption_severity,
corruption_name=self.corruption)
# load proposals if necessary
if self.proposals is not None:
proposal = self.proposals[idx][:self.num_max_proposals]
if not (proposal.shape[1] == 4 or proposal.shape[1] == 5):
raise AssertionError(
'proposals should have shapes (n, 4) or (n, 5), '
'but found {}'.format(proposal.shape))
else:
proposal = None
def prepare_single(img, scale, flip, proposal=None):
_img, img_shape, pad_shape, scale_factor = self.img_transform(
img, scale, flip, keep_ratio=self.resize_keep_ratio)
temp = img.shape
_img = to_tensor(_img)
_img_meta = dict(
#ori_shape=(img_info['height'], img_info['width'], 3),关于COCO的指标问题:
比如:
mask-rcnn rgb: 152张 没有加入ignore在json 迭代:70次
Evaluate annotation type *bbox*
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.841
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.962
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.962
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.874
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.348
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.880
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.880
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.880
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
Evaluate annotation type *segm*
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.867
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.962
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.962
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.895
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.359
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.902
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.902
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.902
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
直接进行测试
from mmdet.apis import init_detector, inference_detector, show_result
import mmcv
# config_file = 'configs/faster_rcnn_r50_fpn_1x.py'
# checkpoint_file = 'checkpoints/faster_rcnn_r50_fpn_1x_20181010-3d1b3351.pth'
#
# # build the model from a config file and a checkpoint file
# model = init_detector(config_file, checkpoint_file, device='cuda:0')
#
# # test a single image and show the results
# img = 'test.jpg' # or img = mmcv.imread(img), which will only load it once
# result = inference_detector(model, img)
# show_result(img, result, model.CLASSES, out_file="result_0.jpg")
#
# # test a list of images and write the results to image files
# imgs = ['test1.jpg', 'test2.jpg']
# for i, result in enumerate(inference_detector(model, imgs)):
# show_result(imgs[i], result, model.CLASSES, out_file='result_{}.jpg'.format(i+1))
import os
path = "/media/spple/新加卷/Dataset/data/luosi_detection/coco_100/train2017/"
imgs = os.listdir(path)
config_file = 'configs/faster_rcnn_r50_fpn_1x.py'
#faster_rcnn_rgb_epoch_1000.pth
#faster_rcnn_gray_epoch_5000.pth
#img_scale=(1333, 800)
checkpoint_file = 'checkpoints/faster_rcnn_rgb_epoch_1000.pth'
model = init_detector(config_file, checkpoint_file, device='cuda:0')
import cv2
imglist = []
imgname = []
CLASSES = ('person')
for i in range(len(imgs)):
imgname.append(imgs[i])
imgs[i] = path + imgs[i]
img = mmcv.imread(imgs[i])
h,w,c = img.shape
dst, scale_factor = mmcv.imrescale(img, (1333, 800), return_scale=True)
#dst = cv2.cvtColor(dst, cv2.COLOR_BGR2RGB)
#dst = cv2.cvtColor(dst, cv2.COLOR_BGR2GRAY)
#dst = cv2.cvtColor(dst, cv2.COLOR_GRAY2BGR)
#dst = dst.transpose(2, 0, 1)
#dst = cv2.resize(img, (1333, 800))
imglist.append(dst)
for i, result in enumerate(inference_detector(model, imglist)):
#show_result(imglist[i], result, model.CLASSES, out_file='./ynh_pred/result_{}.jpg'.format(imgname[i]))
show_result(imglist[i], result, model.CLASSES, out_file='./ynh_pred/result_{}.jpg'.format(imgname[i]))新需求,mmdetection-faster-rcnn检测,把检测的结果进行分割,把deeplabv3分割结果可视化到原图:
mmdetection/mmdet/models/detectors/base.py新加一些代码:注释掉的这些
# draw bounding boxes
labels = [
np.full(bbox.shape[0], i, dtype=np.int32)
for i, bbox in enumerate(bbox_result)
]
labels = np.concatenate(labels)
# # temp
# import cv2
# temp_path = '/home/spple/paddle/vis-project/mmdetection/mmdetection/luosi_temp/'
# temp_img = '/home/spple/paddle/vis-project/mmdetection/mmdetection/luosi_bbox_img_temp/'
# temp_txt = '/home/spple/paddle/vis-project/mmdetection/mmdetection/luosi_bbox_txt_temp/'
# cv2.imwrite(temp_path+str(ids),img_show)
# if score_thr > 0:
# assert bboxes.shape[1] == 5
# scores = bboxes[:, -1]
# inds = scores > score_thr
# temp_bboxes = bboxes[inds, :]
# txtFile = open(temp_txt+str(ids).replace('.jpg','.txt'), 'w')
# h,w,c = img_show.shape
# for i,key in enumerate(temp_bboxes):
# #left_top, right_bottom
# hh = key[3] - key[1] + 1
# ww = key[2] - key[0] + 1
# key[0] = 0 if (key[0] - ww / 2) < 0 else int(key[0] - ww / 2)
# key[1] = 0 if (key[1] - hh / 2) < 0 else int(key[1] - hh / 2)
# key[2] = w if (key[2] + ww / 2) > w else int(key[2] + ww / 2)
# key[3] = h if (key[3] + hh / 2) > h else int(key[3] + hh / 2)
# #crop_img = img_show[key[1]:key[3], key[0]:key[2]]
# crop_img = img_show[int(key[1]):int(key[3]), int(key[0]):int(key[2])]
# txtFile.write("%d %d %d %d\n" % (int(key[0]), int(key[1]), int(key[2]), int(key[3])))
# cv2.imwrite(temp_img + str(ids).split('.jpg')[0] + '_ccvt_' + str(i) + '.jpg', crop_img)
# txtFile.close()
filename = None
if ids is not None:
filename="./ynh_pred/"+str(ids)
然后修改项目pytorch-deeplab-xception:
import argparse
import os
import numpy as np
import tqdm
import torch
from PIL import Image
from dataloaders import make_data_loader
from modeling.deeplab import *
from dataloaders.utils import get_pascal_labels
from utils.metrics import Evaluator
class Tester(object):
def __init__(self, args):
if not os.path.isfile(args.model):
raise RuntimeError("no checkpoint found at '{}'".fromat(args.model))
self.args = args
self.color_map = get_pascal_labels()
self.nclass = 2
# Define model
model = DeepLab(num_classes=self.nclass,
backbone=args.backbone,
output_stride=args.out_stride,
sync_bn=False,
freeze_bn=False)
self.model = model
device = torch.device('cuda')
checkpoint = torch.load(args.model, map_location=device)
self.model.load_state_dict(checkpoint['state_dict'])
def transform_val(self, sample):
from torchvision import transforms
from dataloaders import custom_transforms as tr
composed_transforms = transforms.Compose([
#tr.FixScaleCrop(crop_size=self.args.crop_size),
tr.FixedResize(size=self.args.crop_size),
tr.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
tr.ToTensor()
])
return composed_transforms(sample)
def test(self):
self.model.cuda()
self.model.eval()
from PIL import Image
newpath = "/home/spple/paddle/vis-project/mmdetection/mmdetection/luosi_bbox_img_temp/"
ori_path = '/home/spple/paddle/vis-project/mmdetection/mmdetection/luosi_temp/'
ori_txt = '/home/spple/paddle/vis-project/mmdetection/mmdetection/luosi_bbox_txt_temp/'
imgs = os.listdir(ori_path)
for i in range(len(imgs)):
namename = imgs[i].replace("\n", "")
namename = namename.replace("\t", "")
namename = namename.split(".jpg")[0]
ori_path_name = ori_path + namename + '.jpg'
ori_img = Image.open(ori_path_name).convert('RGB')
ori_img = np.array(ori_img).astype(np.float32)
#打开原始图区域txt
ori_txt_name = ori_txt + namename + '.txt'
file = open(ori_txt_name)
lines = file.readlines()
bbox = []
for line in lines:
list = line.strip('\n').split(' ')
bbox.append([int(list[0]), int(list[1]), int(list[2]), int(list[3])])
#遍历区域
num = len(bbox)
for j in range(len(bbox)):
print(j,'/',num)
#载入原始图区域对应的位置
imgsname = newpath + namename + '_ccvt_' + str(j) + '.jpg'
img = Image.open(imgsname).convert('RGB')
W,H = img.size
imglabel = Image.open(imgsname).convert('P')
sample = {'image': img, 'label': imglabel, 'ori_image': img, 'path': None}
imgdist = self.transform_val(sample)
#进行了如下处理
#arrayimg = np.array(img).astype(np.float32)
#transposeimg = arrayimg.transpose((2, 0, 1))
#torchimg = torch.from_numpy(transposeimg).float()
#扩张维度
image = imgdist['image']
image = image.unsqueeze(0)
image = image.cuda()
#预测
with torch.no_grad():
output = self.model(image)
pred = output.data.cpu().numpy()
#多类别取最大
pred = np.argmax(pred, axis=1)
#预测图像处理
predimage = Image.fromarray(pred[0].astype('uint8'))
mask = predimage.resize((W, H), Image.NEAREST)
mask = np.array(mask)
#预测图分割覆盖
# img = np.array(img).astype(np.float32)
# for i in range(self.nclass):
# if i != 0:
# index = np.argwhere(mask == i)
# for key in index:
# img[key[0]][key[1]][0] = img[key[0]][key[1]][0] * 0.5 + self.color_map[i][0] * 0.5
# img[key[0]][key[1]][1] = img[key[0]][key[1]][1] * 0.5 + self.color_map[i][1] * 0.5
# img[key[0]][key[1]][2] = img[key[0]][key[1]][2] * 0.5 + self.color_map[i][2] * 0.5
# #原图区域替换
# indexbbox = bbox[j]
# ori_img[indexbbox[1]:indexbbox[3], indexbbox[0]:indexbbox[2]] = img
#直接覆盖原图
indexbbox = bbox[j]
for i in range(self.nclass):
if i != 0:
index = np.argwhere(mask == i)
for key in index:
#indexbbox[1]=y indexbbox[0]=x
#key[0]=h key[1]=w
ori_img[key[0]+indexbbox[1]][key[1]+indexbbox[0]][0] = ori_img[key[0]+indexbbox[1]][key[1]+indexbbox[0]][0] * 0.5 + self.color_map[i][0] * 0.5
ori_img[key[0]+indexbbox[1]][key[1]+indexbbox[0]][1] = ori_img[key[0]+indexbbox[1]][key[1]+indexbbox[0]][1] * 0.5 + self.color_map[i][1] * 0.5
ori_img[key[0]+indexbbox[1]][key[1]+indexbbox[0]][2] = ori_img[key[0]+indexbbox[1]][key[1]+indexbbox[0]][2] * 0.5 + self.color_map[i][2] * 0.5
#画出这块区域
import cv2
left_top = (indexbbox[0], indexbbox[1])
right_bottom = (indexbbox[2], indexbbox[3])
cv2.rectangle(
ori_img, left_top, right_bottom, (0, 255, 0), thickness=1)
#保存原始图
file_name = namename + '_' + 'vis' + '.png'
save_img = Image.fromarray(ori_img.astype('uint8'))
save_img.save(self.args.save_path + os.sep + file_name)
def main():
parser = argparse.ArgumentParser(description='Pytorch DeeplabV3Plus Test your data')
parser.add_argument('--test', action='store_true', default=True,
help='test your data')
parser.add_argument('--dataset', default='pascal',
help='datset format')
parser.add_argument('--backbone', default='xception',
help='what is your network backbone')
parser.add_argument('--out_stride', type=int, default=16,
help='output stride')
parser.add_argument('--crop_size', type=int, default=513,
help='image size')
parser.add_argument('--model', type=str, default='',
help='load your model')
parser.add_argument('--save_path', type=str, default='',
help='save your prediction data')
args = parser.parse_args()
if args.test:
tester = Tester(args)
tester.test()
if __name__ == "__main__":
main()另一个需求,mmdetection-faster-rcnn检测,把检测的结果进行mask-rcnn分割,把mask-rcnn分割结果可视化到原图:
import os
from mmdet.apis import init_detector, inference_detector
import mmcv
import numpy as np
import torch
from PIL import Image
import pycocotools.mask as maskUtils
import cv2
red = (0, 0, 255)
green = (0, 255, 0)
blue = (255, 0, 0)
cyan = (255, 255, 0)
yellow = (0, 255, 255)
magenta = (255, 0, 255)
white = (255, 255, 255)
black = (0, 0, 0)
def get_pascal_labels():
"""Load the mapping that associates pascal classes with label colors
Returns:
np.ndarray with dimensions (21, 3)
"""
return np.asarray([[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],
[0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],
[64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],
[64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],
[0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],
[0, 64, 128]])
nclass = 2
color_map = get_pascal_labels()
save_path = '/home/spple/paddle/vis-project/mmdetection/mmdetection/temp__'
config_file = 'configs/mask_rcnn_r50_fpn_1x.py'
checkpoint_file = 'checkpoints/marker_10.30_epoch_440.pth'
model = init_detector(config_file, checkpoint_file, device='cuda:0')
score_thr=0.3
newpath = "/home/spple/paddle/vis-project/mmdetection/mmdetection/luosi_bbox_img_temp/"
ori_path = '/home/spple/paddle/vis-project/mmdetection/mmdetection/luosi_temp/'
ori_txt = '/home/spple/paddle/vis-project/mmdetection/mmdetection/luosi_bbox_txt_temp/'
imgs = os.listdir(ori_path)
num = len(imgs)
for i in range(len(imgs)):
print(i, '/', num)
namename = imgs[i].replace("\n", "")
namename = namename.replace("\t", "")
namename = namename.split(".jpg")[0]
ori_path_name = ori_path + namename + '.jpg'
ori_img = Image.open(ori_path_name).convert('RGB')
ori_img = np.array(ori_img).astype(np.float32)
# 打开原始图区域txt
ori_txt_name = ori_txt + namename + '.txt'
file = open(ori_txt_name)
lines = file.readlines()
bbox = []
for line in lines:
list = line.strip('\n').split(' ')
bbox.append([int(list[0]), int(list[1]), int(list[2]), int(list[3])])
# 遍历区域
for j in range(len(bbox)):
# 载入原始图区域对应的位置
imgsname = newpath + namename + '_ccvt_' + str(j) + '.jpg'
img = Image.open(imgsname).convert('RGB')
W, H = img.size
img = np.array(img)
dst, scale_factor = mmcv.imrescale(img, (1333, 800), return_scale=True)
newH, newW, newC = dst.shape
result = inference_detector(model, dst)
out_file = './ynh_pred/result_{}.jpg'.format(namename)
if isinstance(result, tuple):
bbox_result, segm_result = result
else:
bbox_result, segm_result = result, None
bboxes = np.vstack(bbox_result)
indexbbox = bbox[j]
# 画出这块区域
import cv2
left_top = (indexbbox[0], indexbbox[1])
right_bottom = (indexbbox[2], indexbbox[3])
cv2.rectangle(
ori_img, left_top, right_bottom, (0, 255, 0), thickness=1)
if segm_result is not None:
segms = mmcv.concat_list(segm_result)
inds = np.where(bboxes[:, -1] > score_thr)[0]
for i in inds:
color_mask = np.random.randint(0, 256, (1, 3), dtype=np.uint8)
mask = maskUtils.decode(segms[i])#.astype(np.bool)
#dst[mask] = dst[mask] * 0.5 + color_mask * 0.5
predimage = Image.fromarray(mask.astype('uint8'))
mask = predimage.resize((W, H), Image.NEAREST)
mask = np.array(mask)
# 直接覆盖原图
for i in range(nclass):
if i != 0:
index = np.argwhere(mask == i)
for key in index:
# indexbbox[1]=y indexbbox[0]=x
# key[0]=h key[1]=w
ori_img[key[0] + indexbbox[1]][key[1] + indexbbox[0]][0] = \
ori_img[key[0] + indexbbox[1]][key[1] + indexbbox[0]][0] * 0.5 + color_map[i][0] * 0.5
ori_img[key[0] + indexbbox[1]][key[1] + indexbbox[0]][1] = \
ori_img[key[0] + indexbbox[1]][key[1] + indexbbox[0]][1] * 0.5 + color_map[i][1] * 0.5
ori_img[key[0] + indexbbox[1]][key[1] + indexbbox[0]][2] = \
ori_img[key[0] + indexbbox[1]][key[1] + indexbbox[0]][2] * 0.5 + color_map[i][2] * 0.5
# draw bounding boxes
labels = [
np.full(bbox.shape[0], i, dtype=np.int32)
for i, bbox in enumerate(bbox_result)
]
labels = np.concatenate(labels)
if score_thr > 0:
assert bboxes.shape[1] == 5
scores = bboxes[:, -1]
inds = scores > score_thr
bboxes = bboxes[inds, :]
labels = labels[inds]
if len(bboxes)==0:
continue
#画出mask-rcnn的区域:
for boxindex in bboxes:
left_top = (int(boxindex[0]/scale_factor) + indexbbox[0], int(boxindex[1]/scale_factor) + indexbbox[1])
right_bottom = (int(boxindex[2]/scale_factor) + indexbbox[0], int(boxindex[3]/scale_factor) + indexbbox[1])
cv2.rectangle(
ori_img, left_top, right_bottom, red, thickness=1)
# 保存原始图
file_name = namename + '_' + 'vis' + '.png'
save_img = Image.fromarray(ori_img.astype('uint8'))
save_img.save(save_path + os.sep + file_name)合并coco数据集格式的json文件:
参考:https://blog.csdn.net/Andrwin/article/details/93850275
修改了一些东西,因为拿来用不了,因为json的id都是自定义的,直接append可能导致ID重复
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import os
import datetime
import random
import sys
import operator
import math
import numpy as np
import skimage.io
import matplotlib
from matplotlib import pyplot as plt
from collections import defaultdict, OrderedDict
import json
#待合并的路径
FILE_DIR = "./coco_all_wires_10.26/annotations/"
def load_json(filenamejson):
with open(filenamejson, 'r') as f:
raw_data = json.load(f)
return raw_data
file_count = 0
files = os.listdir(FILE_DIR)
root_data = {}
annotations_num = 0
images_num = 0
annotations_id = []
images=[]
for x in range(len(files)):
#解析文件名字和后缀
#print(str(files[x]))
file_suffix = str(files[x]).split(".")[1]
file_name = str(files[x]).split(".")[0]
#过滤类型不对的文件
if file_suffix not in "json":
continue
#json文件计数
file_count = file_count + 1
#组合文件路径
filenamejson = FILE_DIR + str(files[x])
print(filenamejson)
#读取文件
if x == 0:
#第一个文件作为root
root_data = load_json(filenamejson)
#为了方便直接在第一个json的id最大值基础上进行累加新的json的id
annotations_num = len(root_data['annotations'])
images_num = len(root_data['images'])
#拿到root的id
for key1 in range(annotations_num):
annotations_id.append(int(root_data['annotations'][key1]['id']))
for key2 in range(images_num):
images.append(int(root_data['images'][key2]['id']))
print("{0}生成的json有 {1} 个图片".format(x, len(root_data['images'])))
print("{0}生成的json有 {1} 个annotation".format(x, len(root_data['annotations'])))
else:
#载入新的json
raw_data = load_json(filenamejson)
next_annotations_num = len(raw_data['annotations'])
next_images_num = len(raw_data['images'])
categories_num = len(raw_data['categories'])
print("{0}生成的json有 {1} 个图片".format(x, len(raw_data['images'])))
print("{0}生成的json有 {1} 个annotation".format(x, len(raw_data['annotations'])))
#对于image-list进行查找新id且不存在id库,直到新的id出现并分配
old_imageid = []
new_imageid = []
for i in range(next_images_num):
#追加images的数据
while(images_num in images):
images_num += 1
#将新的id加入匹配库,防止重复
images.append(images_num)
#保存新旧id的一一对应关系,方便annotations替换image_id
old_imageid.append(int(raw_data['images'][i]['id']))
new_imageid.append(images_num)
#使用新id
raw_data['images'][i]['id'] = images_num
root_data['images'].append(raw_data['images'][i])
#对于annotations-list进行查找新id且不存在id库,直到新的id出现并分配
for i in range(next_annotations_num):
#追加annotations的数据
while(annotations_num in annotations_id):
annotations_num += 1
#将新的annotations_id加入匹配库,防止重复
annotations_id.append(annotations_num)
#使用新id
raw_data['annotations'][i]['id'] = annotations_num
#查到该annotation对应的image_id,并将其替换为已经更新后的image_id
ind = int(raw_data['annotations'][i]['image_id'])
#新旧image_id一一对应,通过index旧id取到新id
try:
index = old_imageid.index(ind)
except ValueError as e:
print("error")
exit()
imgid = new_imageid[index]
raw_data['annotations'][i]['image_id'] = imgid
root_data['annotations'].append(raw_data['annotations'][i])
#统计这个文件的类别数--可能会重复,要剔除
#这里我的,categories-id在多个json文件下是一样的,所以没做处理
raw_categories_count = str(raw_data["categories"]).count('name',0,len(str(raw_data["categories"])))
for j in range(categories_num):
root_data["categories"].append(raw_data['categories'][j])
#统计根文件类别数
temp = []
for m in root_data["categories"]:
if m not in temp:
temp.append(m)
root_data["categories"] = temp
print("共处理 {0} 个json文件".format(file_count))
print("共找到 {0} 个类别".format(str(root_data["categories"]).count('name',0,len(str(root_data["categories"])))))
print("最终生成的json有 {0} 个图片".format(len(root_data['images'])))
print("最终生成的json有 {0} 个annotation".format(len(root_data['annotations'])))
json_str = json.dumps(root_data, ensure_ascii=False, indent=1)
#json_str = json.dumps(root_data)
with open('./instances_train2019.json', 'w') as json_file:
json_file.write(json_str)
#写出合并文件
print("Done!") python实现从一个文件夹下随机抽取一定数量的图片并移动到另一个文件夹
参考:
https://blog.csdn.net/weixin_40769885/article/details/82869760
import os, random, shutil
def moveFile(fileDir):
pathDir = os.listdir(fileDir)
filenumber=len(pathDir)
rate=0.15
picknumber=int(filenumber*rate)
sample = random.sample(pathDir, picknumber)
#print (sample)
for name in sample:
shutil.move(fileDir+name, tarDir+name)
return
if __name__ == '__main__':
fileDir = "./JPEGImages/"
tarDir = './image/test/'
moveFile(fileDir)关于mask可视化的一些问题:
# 画出mask-rcnn的mask区域:
# /home/spple/paddle/vis-project/mmdetection/mmdetection/mmdet/models/detectors/base.py
# draw segmentation masks
# 原始代码
# if segm_result is not None:
# segms = mmcv.concat_list(segm_result)
# inds = np.where(bboxes[:, -1] > score_thr)[0]
# for i in inds:
# color_mask = np.random.randint(
# 0, 256, (1, 3), dtype=np.uint8)
# mask = maskUtils.decode(segms[i]).astype(np.bool)
# img_show[mask] = img_show[mask] * 0.5 + color_mask * 0.5