MyDLNote - Attention: ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
MyDLNote - Attention: [2020CVPR] ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
Qilong Wang1 , Banggu Wu1 , Pengfei Zhu1 , Peihua Li2 , Wangmeng Zuo3 , Qinghua Hu1,∗
1 Tianjin Key Lab of Machine Learning, College of Intelligence and Computing, Tianjin University, China
2 Dalian University of Technology, China
3 Harbin Institute of Technology, China
【前言】本文的贡献是改变了对传统 SE 的认知,从中学到的收货是,对于一个网络,不要盲目顺从其中的细节,动手做些真实的实验,能得到新的结论和发现。
语言写作只能说正常。
目录
MyDLNote - Attention: [2020CVPR] ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
Abstract
Introduction
Proposed Method
Revisiting Channel Attention in SE Block
Efficient Channel Attention (ECA) Module
Coverage of Local Cross-Channel Interaction
ECA Module for Deep CNNs
Code
Abstract
Recently, channel attention mechanism has demonstrated to offer great potential in improving the performance of deep convolutional neural networks (CNNs). However, most existing methods dedicate to developing more sophisticated attention modules for achieving better performance, which inevitably increase model complexity. To overcome the paradox of performance and complexity trade-off, this paper proposes an Efficient Channel Attention (ECA) module, which only involves a handful of parameters while bringing clear performance gain.
本文的 motivation:传统的方法致力于复杂的注意力设计,而本文提出的方法只引入少量参数,却带来明显的性能增益。
By dissecting the channel attention module in SENet, we empirically show avoiding dimensionality reduction is important for learning channel attention, and appropriate cross-channel interaction can preserve performance while significantly decreasing model complexity.
本文的核心思想:避免降维对于学习通道注意是很重要的;适当的跨通道交互可以在显著降低模型复杂度的同时保持性能。
Therefore, we propose a local cross-channel interaction strategy without dimensionality reduction, which can be efficiently implemented via 1D convolution. Furthermore, we develop a method to adaptively select kernel size of 1D convolution, determining coverage of local cross-channel interaction.
本文的核心工作:
提出了一种无降维的局部跨通道交互策略,该策略可以通过一维卷积有效地实现;
建立了一种自适应选择一维卷积核大小的方法,确定了局部跨通道相互作用的覆盖范围。
The proposed ECA module is efficient yet effective, e.g., the parameters and computations of our modules against backbone of ResNet50 are 80 vs. 24.37M and 4.7e-4 GFLOPs vs. 3.86 GFLOPs, respectively, and the performance boost is more than 2% in terms of Top-1 accuracy. We extensively evaluate our ECA module on image classification, object detection and instance segmentation with backbones of ResNets and MobileNetV2. The experimental results show our module is more efficient while performing favorably against its counterparts.
实验结果。
Introduction
讲清楚一个故事:
Recently, incorporation of channel attention into convolution blocks has attracted a lot of interests, showing great potential in performance improvement [14, 33, 13, 4, 9, 18, 7].
第一段: 大背景介绍 --- attention 用在卷积模块中获得很大成果。
[4] A2 -Nets: Double attention networks. In NIPS, 2018.
[7] Dual attention network for scene segmentation. In CVPR, 2019.
[9] Global second-order pooling convolutional networks. In CVPR, 2019.
[13] Gather-excite: Exploiting feature context in convolutional neural networks. In NeurIPS, 2018.
[14] Squeeze-and-excitation networks. In CVPR, 2018.
[18] Channel locality block: A variant of squeeze-andexcitation. arXiv, 1901.01493, 2019.
[33] CBAM: Convolutional block attention module. In ECCV, 2018.
Following the setting of squeeze (i.e., feature aggregation) and excitation (i.e., feature recalibration) in SENet [14], some researches improve SE block by capturing more sophisticated channel-wise dependencies [33, 4, 9, 7] or by combining with additional spatial attention [33, 13, 7]. Although these methods have achieved higher accuracy, they often bring higher model complexity and suffer from heavier computational burden. Different from the aforementioned methods that achieve better performance at the cost of higher model complexity, this paper focuses instead on a question: Can one learn effective channel attention in a more efficient way?
第二段:提出问题 --- 但是,这些成果都是在设计更复杂的通道 attention 或添加复杂的空间 attention。本文就想,能不能提出一个不用明显增加复杂度,而提高 attention 性能的方法呢?
To answer this question, we first revisit the channel attention module in SENet. Specifically, given the input features, SE block first employs a global average pooling for each channel independently, then two fully-connected (FC) layers with non-linearity followed by a Sigmoid function are used to generate channel weights. The two FC layers are designed to capture non-linear cross-channel interaction, which involve dimensionality reduction for controlling model complexity. Although this strategy is widely used in subsequent channel attention modules [33, 13, 9], our empirical studies show dimensionality reduction brings side effect on channel attention prediction, and it is inefficient and unnecessary to capture dependencies across all channels.
第三段:提出本文的核心发现 --- SE 的两个问题:
1. FC 中间隐含层降维:降维对同道注意力预测有负面影响;(这个问题大家都知道)
2. FC 层学习通道之间的关系:跨所有通道捕获依赖项是低效且不必要的。(这个问题我是第一次听说,还是蛮吸引人的)
Therefore, this paper proposes an Efficient Channel Attention (ECA) module for deep CNNs, which avoids dimensionality reduction and captures cross-channel interaction in an efficient way. As illustrated in Figure 2, after channel-wise global average pooling without dimensionality reduction, our ECA captures local cross-channel interaction by considering every channel and its
neighbors. Such method is proven to guarantee both efficiency and effectiveness. Note that our ECA can be efficiently implemented by fast 1D convolution of size
第四段:针对发现,提出解决方案 --- 1)避免 FC 中的降维,以有效的方式捕获跨通道交互;2)自动调整 的大小。
具体地,1)就是将感知器换成局部卷积层,输出与输入维度相同;虽然很简单,但确实是常规思维的突破;
2)交互的范围(即,内核 大小)与通道维数成正比。
Figure 2. Diagram of our efficient channel attention (ECA) module. Given the aggregated features obtained by global average pooling (GAP), ECA generates channel weights by performing a fast 1D convolution of size k, where k is adaptively determined via a mapping of channel dimension C.

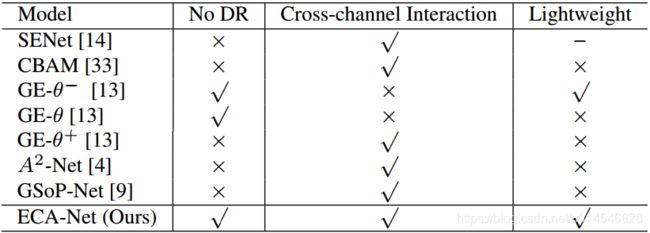
Table 1 summarizes existing attention modules in terms of whether channel dimensionality reduction (DR), cross-channel interaction and lightweight model, where we can see that our ECA module learn effective channel attention by avoiding channel dimensionality reduction while capturing cross-channel interaction in an extremely lightweight way. To evaluate our method, we conduct experiments on ImageNet-1K [6] and MS COCO [23] in a variety of tasks using different deep CNN architectures.
第五段:提出解决方案和其它方法的直观对比,可以赢得渎者对本文方法的好感和信任。
Table 1. Comparison of existing attention modules in terms of whether no channel dimensionality reduction (No DR), crosschannel interaction and less parameters than SE (indicated by lightweight) or not.
The contributions of this paper are summarized as follows. (1) We dissect the SE block and empirically demonstrate avoiding dimensionality reduction and appropriate cross-channel interaction are important to learn effective and efficient channel attention, respectively. (2) Based on above analysis, we make an attempt to develop an extremely lightweight channel attention module for deep CNNs by proposing an Efficient Channel Attention (ECA), which increases little model complexity while bringing clear improvement. (3) The experimental results on ImageNet-1K and MS COCO demonstrate our method has lower model complexity than state-of-the-arts while achieving very competitive performance.
第六段:总结贡献:(1)我们解剖了SE块,并通过实证证明避免降维和适当的跨通道交互对学习对于有效的和高效的通道注意是重要的。(2)基于以上分析,我们提出了一种有效的通道注意(ECA)方法,尝试为深度CNNs开发一种非常轻量级的通道注意模块,该方法在提高模型复杂度的同时,也带来了明显的改进。(3)在ImageNet-1K和MS COCO上的实验结果表明,我们的方法在获得极具竞争力的性能的同时,具有较低的模型复杂度。
Proposed Method
In this section, we first revisit the channel attention module in SENet [14] (i.e., SE block). Then, we make a empirical diagnosis of SE block by analyzing effects of dimensionality reduction and cross-channel interaction. This motivates us to propose our ECA module. In addition, we develop a method to adaptively determine parameter of our ECA, and finally show how to adopt it for deep CNNs.
Revisiting Channel Attention in SE Block
Let the output of one convolution block be
, where
,
and
are width, height and channel dimension (i.e., number of filters). Accordingly, the weights of channels in SE block can be computed as
, (1)
where
is channel-wise global average pooling (GAP) and
is a Sigmoid function. Let
,
takes the form
, (2)
where ReLU indicates the Rectified Linear Unit. To avoid high model complexity, sizes of
and
are set to
and
, respectively. We can see that
提出了SE的问题:Eq.(2)首先将信道特征投影到低维空间中,然后将其映射回来,使得信道与其权值之间的对应是间接的。
Efficient Channel Attention (ECA) Module
Avoiding Dimensionality Reduction
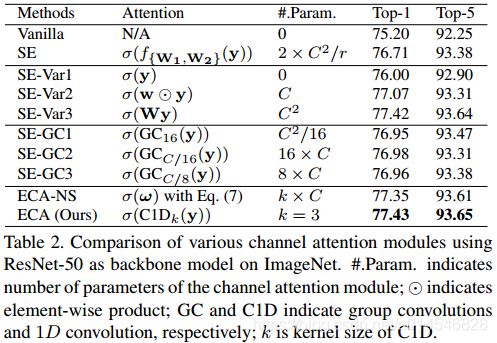
As discussed above, dimensionality reduction in Eq. (2) makes correspondence between channel and its weight be indirect. To verify its effect, we compare the original SE block with its three variants (i.e., SE-Var1, SE-Var2 and SEVar3), all of which do not perform dimensionality reduction. As presented in Table 2, SE-Var1 with no parameter is still superior to the original network, indicating channel attention has ability to improve performance of deep CNNs. Meanwhile, SE-Var2 learns the weight of each channel independently, which is slightly superior to SE block while involving less parameters. It may suggest that channel and its weight needs a direct correspondence while avoiding dimensionality reduction is more important than consideration of nonlinear channel dependencies. Additionally, SE-Var3 employing one single FC layer performs better than two FC layers with dimensionality reduction in SE block. All of above results clearly demonstrate avoiding dimensionality reduction is helpful to learn effective channel attention. Therefore, we develop our ECA module without channel dimensionality reduction.
这小节给出了重要实验观察,即:
SE-Var1:没有参数的 SE-Var1 仍优于原网络(这句是不是写错了?),说明信道注意有能力提高深度CNNs的性能。
SE-Var2:SE- var2 独立学习每个通道的权值(depth-wise 卷积吗?),在参数较少的情况下略优于 SE 块。
SE-Var3:使用单个 FC 层的 SE- var3 要比使用两个降维的 FC 层的 SE 块性能更好。
以上结果清楚地表明,避免降维有助于学习有效的渠道注意。因此,我们开发的ECA模块没有降低通道维数。
Table 2. Comparison of various channel attention modules using ResNet-50 as backbone model on ImageNet. #.Param. indicates number of parameters of the channel attention module;
indicates element-wise product; GC and C1D indicate group convolutions and 1D convolution, respectively; k is kernel size of C1D.
Local Cross-Channel Interaction
Given the aggregated feature
without dimensionality reduction, channel attention can be learned by
, where
parameter matrix. In particular, for SE-Var2 and SE-Var3 we have
where
for SE-Var2 is a diagonal matrix, involving
for SE-Var3 is a full matrix, involving
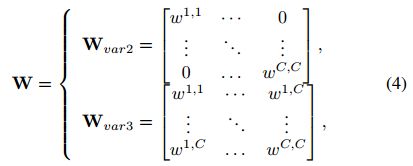
上一小节说明了无缩放的 SE-Var2 和 SE-Var3 效果最好。这一段呢,就解释一下,为啥 SE-Var3 优于 SE-Var2:SE-Var3考虑跨通道交互,而SE-Var2不考虑,因此SE-Var3获得了更好的性能。
进一步推理,那把 SE-Var2 和 SE-Var3 结合一下,会好吗?
A possible compromise between SE-Var2 and SE-Var3 is extension of
where Eq. (5) divides channel into
groups each of which includes
channels, and learns channel attention in each group independently, which captures cross-channel interaction in a local manner. Accordingly, it involves
parameters. From perspective of convolution, SE-Var2, SEVar3 and Eq. (5) can be regarded as a depth-wise separable convolution, a FC layer and group convolutions, respectively. Here, SE block with group convolutions (SE-GC) is indicated by
. However, as shown in [24], excessive group convolutions will increase memory access cost and so decrease computational efficiency. Furthermore, as shown in Table 2, SE-GC with varying groups bring no gain over SE-Var2, indicating it is not an effective scheme to capture local cross-channel interaction. The reason may be that SE-GC completely discards dependences among different groups.
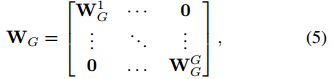
SE-Var2 和 SE-Var3 结合的方法,就是用组卷积方法 --- SE-GC。
虽然很巧妙,但效果不好。原因可能是SE-GC完全抛弃了不同组之间的依赖性。
In this paper, we explore another method to capture local cross-channel interaction, aiming at guaranteeing both efficiency and effectiveness. Specifically, we employ a band matrix
to learn channel attention, and
Clearly,
parameters, which is usually less than those of Eq. (5). Furthermore, Eq. (6) avoids complete independence among different groups in Eq. (5). As compared in Table 2, the method in Eq. (6) (namely ECA-NS) outperforms SE-GC of Eq. (5). As for Eq. (6), the weight of
is calculated by only considering interaction between
where
indicates the set of
A more efficient way is to make all channels share the same learning parameters, i.e.,

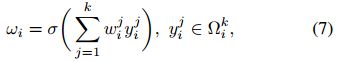
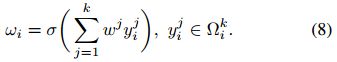
SE-GC 效果不好的原因是交互性不好,那就提一个交互性好的方法,就是公式(6)。
我分析觉得这是一个分成 个的 ![]() 的卷积,且相邻卷积的中心位置步进为 1。
的卷积,且相邻卷积的中心位置步进为 1。
进一步为了减少参数,所有的卷积共享参数,即,这是一个 ![]() 、步进为 1 的卷积。
、步进为 1 的卷积。
Note that such strategy can be readily implemented by a fast 1D convolution with kernel size of
, (9)
where
indicates 1D convolution. Here, the method in Eq. (9) is called by efficient channel attention (ECA) module, which only involves
achieves similar results with SE-var3 while having much lower model complexity, which guarantees both efficiency and effectiveness by appropriately capturing local cross-channel interaction.
惊讶不!做了半天实验,推导了半天,最后就是一个 ![]() 卷积代替了原来的 FC 层!!!
卷积代替了原来的 FC 层!!!
这就是 efficient channel attention (ECA) module。结论很简单,但过程比较细致。
当然了,这个 3 是实验值,下面提出了一种自适应的方法,来确定卷积核的长度。
Coverage of Local Cross-Channel Interaction
Since our ECA module (9) aims at appropriately capturing local cross-channel interaction, so the coverage of interaction (i.e., kernel size k of 1D convolution) needs to be determined. The optimized coverage of interaction could be tuned manually for convolution blocks with different channel numbers in various CNN architectures. However, manual tuning via cross-validation will cost a lot of computing resources. Group convolutions have been successfully adopted to improve CNN architectures [37, 34, 16], where high-dimensional (low-dimensional) channels involve long range (short range) convolutions given the fixed number of groups. Sharing the similar philosophy, it is reasonable that the coverage of interaction (i.e., kernel size
between
. (10)
The simplest mapping is a linear function, i.e.,
.
交互的覆盖范围应该与输入通道个数成正比,然后给出了最简单的线性形式 ![]() 。
。
[16] Deep roots: Improving cnn efficiency with hierarchical filter groups. In CVPR, 2017
[34] Aggregated residual transformations for deep neural networks. In CVPR, 2017.
[37] Interleaved group convolutions. In ICCV, 2017.
However, the relations characterized by linear function are too limited. On the other hand, it is well known that channel dimension C (i.e., number of filters) usually is set to power of 2. Therefore, we introduce a possible solution by extending the linear function ![]() to a non-linear one, i.e.,
to a non-linear one, i.e.,
. (11)
Then, given channel dimension
where
indicates the nearest odd number of
. In this paper, we set
and
to 2 and 1 throughout all the experiments, respectively. Clearly, through the mapping
, high-dimensional channels have longer range interaction while low-dimensional ones undergo shorter range interaction by using a non-linear mapping.
但是呢,线性的方式过于简单,或者说不能很好地拟合交互覆盖范围与输入通道数之间的潜在关系。
考虑到 一般都是 2 的幂次方,因此,设计了非线性关系表达式:
![]()
最后,反求 ,当然, 为奇数。
![]() 。
。
ECA Module for Deep CNNs
Figure 2 illustrates the overview of our ECA module. After aggregating convolution features using GAP without dimensionality reduction, ECA module first adaptively determines kernel size
为了将ECA应用到深度CNNs,用ECA模块替换SE块,在[14]中使用相同的配置。
[14] Densely connected convolutional networks. In CVPR, 2017.
Code
Figure 3. PyTorch code of our ECA module.
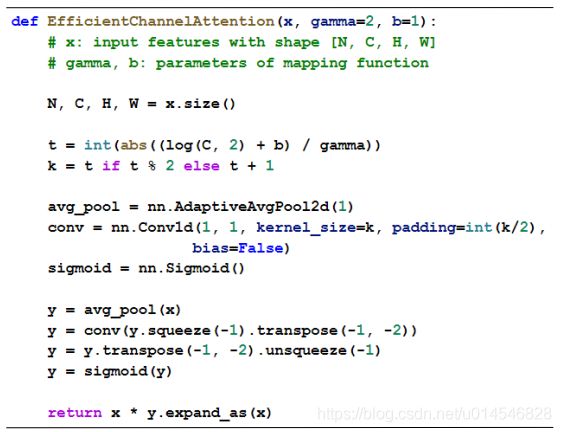
实验部分等用的时候再分析吧。。。【持续更新。。。】