关于Yolov5引入SEnet,CA,CBAM,SKA等注意力模块的方法
1.本文是基于5.0版本的yolov5,其他版本大同小异。(ps:本文仅作为经验总结,方便我日后复习回顾)
以CoordAtt(CA)为例:下载好v5.0版本后,首先在主目录models文件下创建一个yolov5m_CA的yaml文件,文件代码如下:
# parameters
nc: 80 # number of classes
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[ -1, 1, CoordAtt, [ 1024 ] ],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
然后在models文件目录下的common.py文件末尾增加CA相应的代码段,代码如下:
#CA
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
# c*1*W
x_h = self.pool_h(x)
# c*H*1
# C*1*h
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
# C*1*(h+w)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
最后更改一下models目录下yolo.py中的代码,在其中找到函数parse_model,在如图红框中插入自己定义的注意力类名(和common.py中添加的保持一致):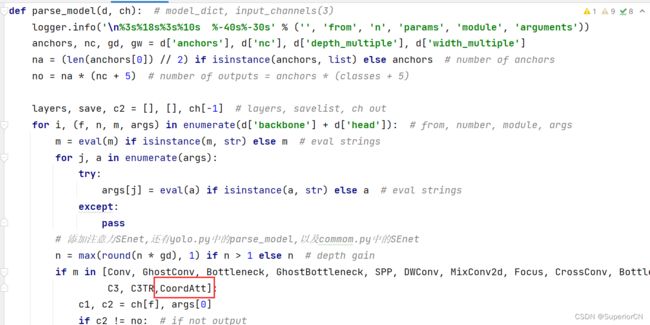
配置就基本完成了。
最后来到主目录下的train.py文件,找到主程序中的--cfg语句,将default改为如下:
运行,可以看到CA已经被添加进入了。
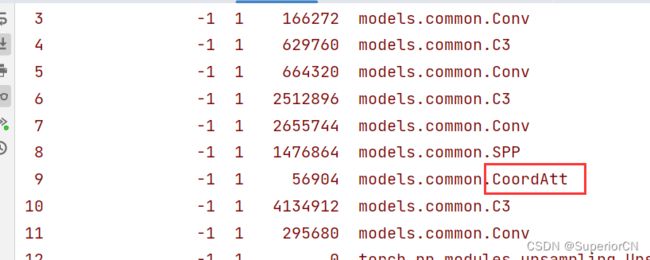
2.其他的操作都一样,在common.py加入注意力机制代码,将上文所发yolov5m_CA.yaml文件中注意力类名更改一下要替换的注意力类名,再在yolo.py中相同位置更换类名,最后在训练的cfg代码处添加相应yaml文件运行就可以。我把我自己收纳的注意力模块代码放在下方。
CBAM
#Cbam
import torch
from torch import nn
from torch.nn.modules.activation import ReLU
class channel_attention(nn.Module):
def __init__(self,channel,ratio=16):
super(channel_attention,self).__init__()
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.avg_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel,channel//ratio,False),
nn.ReLU(),
nn.Linear(channel//ratio,channel,False)
)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
b,c,h,w = x.size()
max_pool_out = self.max_pool(x).view([b,c])
avg_pool_out = self.avg_pool(x).view([b,c])
max_fc_out = self.fc(max_pool_out)
avg_fc_out = self.fc(avg_pool_out)
out = max_fc_out + avg_fc_out
out = self.sigmoid(out).view([b,c,1,1])
return out * x
class spacial_attention(nn.Module):
def __init__(self,kernel_size=7):
super(spacial_attention,self).__init__()
padding = 7//2
self.conv = nn.Conv2d(2,1,kernel_size,1,padding,bias = False)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
max_pool_out,_ = torch.max(x,dim = 1,keepdim=True)
mean_pool_out,_ = torch.mean(x,dim = 1,keepdim=True)
pool_out = torch.cat([max_pool_out,mean_pool_out],dim=1)
out = self.conv(pool_out)
out = self.sigmoid(out)
return out * x
class Cbam(nn.Module):
def __init__(self,channel,ratio = 16, kernel_size=7):
super(Cbam, self).__init__()
self.channel_attention = channel_attention(channel,ratio)
self.spacial_attention = spacial_attention(kernel_size)
def forward(self, x):
x = self.channel_attention(x)
x = self.spacial_attention(x)
return x
#代表输入有512个channel
model = Cbam(512)
print(model)
#2代表的是batchsize
inputs = torch.ones([2,512,26,26])
outputs = model(inputs)CrissCrissAttention
'''
This code is borrowed from Serge-weihao/CCNet-Pure-Pytorch
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Softmax
def INF(B, H, W):
return -torch.diag(torch.tensor(float("inf")).repeat(H), 0).unsqueeze(0).repeat(B * W, 1, 1)
class CrissCrossAttention(nn.Module):
""" Criss-Cross Attention Module"""
def __init__(self, in_dim):
super(CrissCrossAttention, self).__init__()
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.softmax = Softmax(dim=3)
self.INF = INF
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
m_batchsize, _, height, width = x.size()
proj_query = self.query_conv(x)
proj_query_H = proj_query.permute(0, 3, 1, 2).contiguous().view(m_batchsize * width, -1, height).permute(0, 2,
1)
proj_query_W = proj_query.permute(0, 2, 1, 3).contiguous().view(m_batchsize * height, -1, width).permute(0, 2,
1)
proj_key = self.key_conv(x)
proj_key_H = proj_key.permute(0, 3, 1, 2).contiguous().view(m_batchsize * width, -1, height)
proj_key_W = proj_key.permute(0, 2, 1, 3).contiguous().view(m_batchsize * height, -1, width)
proj_value = self.value_conv(x)
proj_value_H = proj_value.permute(0, 3, 1, 2).contiguous().view(m_batchsize * width, -1, height)
proj_value_W = proj_value.permute(0, 2, 1, 3).contiguous().view(m_batchsize * height, -1, width)
energy_H = (torch.bmm(proj_query_H, proj_key_H) + self.INF(m_batchsize, height, width)).view(m_batchsize, width,
height,
height).permute(0,
2,
1,
3)
energy_W = torch.bmm(proj_query_W, proj_key_W).view(m_batchsize, height, width, width)
concate = self.softmax(torch.cat([energy_H, energy_W], 3))
att_H = concate[:, :, :, 0:height].permute(0, 2, 1, 3).contiguous().view(m_batchsize * width, height, height)
# print(concate)
# print(att_H)
att_W = concate[:, :, :, height:height + width].contiguous().view(m_batchsize * height, width, width)
out_H = torch.bmm(proj_value_H, att_H.permute(0, 2, 1)).view(m_batchsize, width, -1, height).permute(0, 2, 3, 1)
out_W = torch.bmm(proj_value_W, att_W.permute(0, 2, 1)).view(m_batchsize, height, -1, width).permute(0, 2, 1, 3)
# print(out_H.size(),out_W.size())
return self.gamma * (out_H + out_W) + x
ECA
import torch
from torch import nn
import math
class eca_block(nn.Module):
def __init__(self,channel,gamma = 2,b = 1):
super(eca_block, self).__init__()
kernel_size = int(abs((math.log(channel,2)+b)/gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size +1
padding = kernel_size // 2
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1,1,kernel_size,padding = padding,bias=False)
def forward(self,x):
b,c,h,w = x.size()
avg = self.avg_pool(x).view([b,1,c])
out = self.conv(avg)
out = self.sigmoid(out).view([b,c,1,1])
return out * x
model = eca_block(512)
print(model)
inputs = torch.ones([2,512,26,26])
outputs = model(inputs)ShuffleAttention
import numpy as np
import torch
from torch import nn
from torch.nn import init
from torch.nn.parameter import Parameter
# https://arxiv.org/pdf/2102.00240.pdf
class ShuffleAttention(nn.Module):
def __init__(self, channel=512, reduction=16, G=8):
super().__init__()
self.G = G
self.channel = channel
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.gn = nn.GroupNorm(channel // (2 * G), channel // (2 * G))
self.cweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.cbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.sbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sigmoid = nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
@staticmethod
def channel_shuffle(x, groups):
b, c, h, w = x.shape
x = x.reshape(b, groups, -1, h, w)
x = x.permute(0, 2, 1, 3, 4)
# flatten
x = x.reshape(b, -1, h, w)
return x
def forward(self, x):
b, c, h, w = x.size()
# group into subfeatures
x = x.view(b * self.G, -1, h, w) # bs*G,c//G,h,w
# channel_split
x_0, x_1 = x.chunk(2, dim=1) # bs*G,c//(2*G),h,w
# channel attention
x_channel = self.avg_pool(x_0) # bs*G,c//(2*G),1,1
x_channel = self.cweight * x_channel + self.cbias # bs*G,c//(2*G),1,1
x_channel = x_0 * self.sigmoid(x_channel)
# spatial attention
x_spatial = self.gn(x_1) # bs*G,c//(2*G),h,w
x_spatial = self.sweight * x_spatial + self.sbias # bs*G,c//(2*G),h,w
x_spatial = x_1 * self.sigmoid(x_spatial) # bs*G,c//(2*G),h,w
# concatenate along channel axis
out = torch.cat([x_channel, x_spatial], dim=1) # bs*G,c//G,h,w
out = out.contiguous().view(b, -1, h, w)
# channel shuffle
out = self.channel_shuffle(out, 2)
return out
SKAttention
from collections import OrderedDict
import torch
from torch import nn
class SKAttention(nn.Module):
def __init__(self, channel=512, kernels=[1, 3, 5, 7], reduction=16, group=1, L=32):
super().__init__()
self.d = max(L, channel // reduction)
self.convs = nn.ModuleList([])
for k in kernels:
self.convs.append(
nn.Sequential(OrderedDict([
('conv', nn.Conv2d(channel, channel, kernel_size=k, padding=k // 2, groups=group)),
('bn', nn.BatchNorm2d(channel)),
('relu', nn.ReLU())
]))
)
self.fc = nn.Linear(channel, self.d)
self.fcs = nn.ModuleList([])
for i in range(len(kernels)):
self.fcs.append(nn.Linear(self.d, channel))
self.softmax = nn.Softmax(dim=0)
def forward(self, x):
bs, c, _, _ = x.size()
conv_outs = []
### split
for conv in self.convs:
conv_outs.append(conv(x))
feats = torch.stack(conv_outs, 0) # k,bs,channel,h,w
### fuse
U = sum(conv_outs) # bs,c,h,w
### reduction channel
S = U.mean(-1).mean(-1) # bs,c
Z = self.fc(S) # bs,d
### calculate attention weight
weights = []
for fc in self.fcs:
weight = fc(Z)
weights.append(weight.view(bs, c, 1, 1)) # bs,channel
attention_weughts = torch.stack(weights, 0) # k,bs,channel,1,1
attention_weughts = self.softmax(attention_weughts) # k,bs,channel,1,1
### fuse
V = (attention_weughts * feats).sum(0)
return V
我学术浅薄如果这篇文章有错误的话欢迎大家指正!