ShiftViT用Swin Transformer的精度跑赢ResNet的速度,论述ViT的成功不在注意力!
点击上方“计算机视觉工坊”,选择“星标”
干货第一时间送达
![]()
作者丨 ChaucerG
来源丨集智书童

注意力机制被广泛认为是Vision Transformer(ViT)成功的关键,因为它提供了一种灵活和强大的方法来建模空间关系。然而,注意力机制真的是ViT不可或缺的组成部分吗?它能被一些其他的替代品所取代吗?为了揭开注意力机制的作用,作者将其简化为一个非常简单的情况:ZERO FLOP和ZERO parameter。
具体地说,作者重新审视了Shift操作。它不包含任何参数或算术计算。唯一的操作是在相邻的特征之间交换一小部分通道。基于这个简单的操作,作者构建了一个新的Backbone,即ShiftViT,其中ViT中的注意力层被shift操作所取代。
令人惊讶的是,ShiftViT在几个主流任务中工作得很好,比如分类、检测和分割。性能甚至比Swin Transformer更好。这些结果表明,注意力机制可能不是使ViT成功的关键因素。它甚至可以被一个为零参数的操作所取代。在今后的工作中,应该更加重视ViT的其余部分。
1简介
Backbone的设计在计算机视觉中起着至关重要的作用。自从AlexNet的革命性进步以来,卷积神经网络(CNNs)已经主导了这个邻域近10年。然而,最近的ViTs已经显示出了挑战这个宝座的潜力。ViT的优势首先在图像分类任务中得到了证明,在该任务中,ViT的Backbone显著优于CNN的Backbone。由于ViT优秀的性能使得,ViT的变体蓬勃发展迅速应用到许多其他计算机视觉任务,如目标检测、语义分割和动作识别。
尽管最近ViT变体的表现令人印象深刻,但依旧不清楚是什么使ViT有利于视觉任务。一些工作倾向于将成功归功于注意力机制,因为它提供了一种灵活而强大的方式来建模空间关系。具体来说,注意力机制利用自注意力矩阵来聚集来自任意位置的特征。与CNN中的卷积运算相比,它有两个显著的优点。首先,这种机制提供了同时捕获短期和长期依赖的可能性,并摆脱了卷积的局部限制。其次,两个空间位置之间的相互作用动态地依赖于各自的特征,而不是一个固定的卷积核。由于这些优良的特性,一些作品认为是注意力机制促成了ViT强大的表达能力。
然而,这两个优势真的是成功的关键吗?答案可能不是。一些现有的工作证明,即使没有这些属性,ViT变体仍然可以很好地工作。对于第一个,全局的依赖可能并非不可避免。越来越多的ViT引入了一种局部注意力机制,将其注意力范围限制在一个小的局部区域内,如Swin-Transformer和Local ViT。实验结果表明,该系统的性能并没有由于局部限制而下降。此外,另一条研究探讨了动态聚合的必要性。MLP-Mixer提出用线性投影层代替注意力层,其中线性权值不是动态生成的。在这种情况下,它仍然可以在ImageNet数据集上达到领先的性能。
既然全局特性和动态特性可能对ViT框架都不重要,那么ViT成功的根本原因是什么呢?为了解决清楚,作者进一步将注意力层进一步简化为一个非常简单的情况:没有全局范围,没有动态,甚至没有参数,没有算术计算。作者想知道ViT在这种极端情况下是否能保持良好的性能。
 图1
图1
从概念上讲,这种零参数的替代方案必须依赖于手工制作的规则来建模空间关系。在这项工作中,重新讨论了Shift操作,作者认为这是最简单的空间建模模块之一。如图1所示,标准的ViT构建块包括2个部分:注意力层和前馈网络(FFN)。
作者用Shift操作取代前一个注意力层,同时保持后一个FFN部分的不变。给定一个输入特征,建议的构建块将首先沿着4个空间方向移动一小部分通道,即左、右、上和下。因此,相邻特征的信息被通道的Shift混合在一起。然后,随后的FFN进行通道混合,以进一步融合来自相邻通道的信息。
基于这个shift building block构建了一个类似ViT的Backbone,即ShiftViT。令人惊讶的是,这个Backbone也可以很好地用于主流的视觉识别任务。性能与Swin Transformer相当,甚至更好。具体地说,在与Swin-T模型相同的计算预算内,ShiftViT在ImageNet数据集上达到了81.7%(相对于Swin-T的81.3%)。对于密集预测任务,在COCO检测数据集上平均精度(mAP)为45.7%(Swin-T的43.7%),在ADE20k分割数据集上平均精度(mIoU)为46.3%(Swin-T的44.5%)。
由于Shift操作已经是最简单的空间建模模块,因此优秀的性能必须来自于剩余的组件,如FFN中的线性层和激活函数。这些组件在现有的工作中研究较少,因为它们看起来微不足道。然而,为了进一步揭开ViT工作的原因的神秘面纱,作者认为应该更多地关注这些组成部分,而不是仅仅关注注意力机制。
综上所述,本工作的贡献有两方面:
提出了一个类似ViT的Backbone,其中普通的注意力层被一个非常简单的Shift操作所取代。该模型可以获得比Swin Transformer更好的性能
分析了ViT成功背后的原因。这暗示了注意力机制可能不是使ViT工作的关键因素。在今后的ViT研究中,应该认真对待其余的组成部分
2相关工作
2.1 Attention and Vision Transformers
Transformer首次被引入到自然语言处理(NLP)领域。它仅采用注意力机制来建立不同语言Token之间的联系。由于出色的性能,Transformer已经迅速主导了NLP领域,并成为事实上的标准。
受自然语言处理成功应用的启发,注意力机制也受到了计算机视觉界越来越多的兴趣。早期的勘探大致可分为两类。一方面,一些文献认为注意力是一个即插即用的模块,它可以无缝地集成到现有的CNN架构中。具有代表性的工作包括non-local网络、Relation网络和CCNet。另一方面,一些工作的目标是用注意力机制替代所有的卷积操作,如Local Relation网络和Self-Attention。
虽然这两种工作已经显示出了很有希望的结果,但它们仍然是建立在CNN架构的基础上的。ViT是利用纯Transformer架构进行视觉识别任务的开创性工作。由于其令人印象深刻的表现,该领域最近爆发了一波不断上升的关于视觉Transformer的研究浪潮。
沿着这一研究方向,主要研究重点是改进注意力机制,使其能够满足视觉信号的内在特性。例如,MSViT构建层次注意力层以获得多尺度特征。Swin-Transformer在其注意力机制中引入了一种局部性约束。相关的工作还包括pyramid attention、local-global attention、cross attention等等。
与对注意力机制的特殊兴趣不同,ViT的其余组成部分的研究较少。DeiT为视觉Transformer建立了一个标准的训练管道。大多数后续工作都继承了它的配置,只对注意力机制做了一些修改。本文的工作也遵循了这种范式。然而,这项工作的目的并不是复杂注意力的设计。相反,本文的目的是表明,注意力机制可能不是使ViTs工作的关键部分。它甚至可以被一个非常简单的Shift操作所取代。作者希望这些结果能够激励研究者重新思考注意力机制的作用。
2.2 MLP Variants
本文的工作与最近的多层感知器(MLP)变体有关。具体来说,MLP的变体提出通过一个纯的类似MLP的架构来提取图像特征。跳出了ViT中基于注意力的框架。例如,MLP-Mixer引入了一个Token混合MLP,以直接连接所有空间位置。它消除了ViT的动态特性,但不失去准确性。后续工作研究了更多的MLP设计,如空间门控单元或循环连接。
ShiftViT也可以归类为纯MLP架构,其中Shift操作被视为一个特殊的Token混合层。与现有的MLP工作相比,Shift操作更简单,因为它不包含参数,也没有FLOP。此外,由于具有固定的线性权值,普通的MLP变体不能处理可变的输入大小。Shift操作克服了这一障碍,因此使Backbone用于更多的视觉任务,如目标检测和语义分割。
2.3 Shift Operation
Shift操作在计算机视觉中并不是什么新鲜事。早在2017年,它就被认为是空间卷积操作的一种有效的替代方案。具体地说,它使用了一个类似三明治的体系结构,2个1×1卷积和一个Shift操作,来近似一个K×K卷积。在后续工作中,Shift操作进一步扩展到不同的变体,如active Shift、sparse Shift和partial Shift。
3Shift-ViT
3.1 架构概览
为了进行公平的比较,作者遵循了Swin Transformer的体系结构。体系结构概述如图2(a)。
 图2(a)
图2(a)
所示具体来说,给定一个形状为H×W×3的输入图像,它首先将图像分割成不重叠的patches。patch-size为4×4像素。因此,patch partition的输出值为H/4×W/4 token,其中每个token的通道大小为48。
接下来的模块可以分为4个阶段。每个阶段包括2个部分:嵌入生成和堆叠shift块。对于第一阶段的嵌入生成,使用一个线性投影层将每个token映射成一个通道大小为c的嵌入。对于其余的阶段,通过核大小为2×2的卷积来合并相邻的patch。patch合并后,输出的空间大小是下采样的一半,而通道大小是输入的2倍,即从C到2C。
堆叠的shift块是由一些重复的基本单元组成的。每个shift块的详细设计如图2(b)。所示它由shift操作、层标准化和MLP网络组成。这种设计几乎与标准的Transformer组块相同。唯一的区别是,使用的是一个shift操作,而不是一个注意力层。对于每个阶段,shift块的数量可以是不同的,分别记为、、、。在out实现中,仔细选择了的值,从而使整个模型与 Baseline Swin Transformer模型共享相似数量的参数。
3.2 Shift Block
Shift Block的详细体系结构如图2(b)。

所示具体来说,该块由3个顺序堆叠的组件组成:Shift操作、层归一化和MLP网络。
Shift操作在cnn中已经得到了很好的研究。它可以有许多设计选择,如active Shift和sparse Shift。在本工作中遵循TSM中的partial Shift操作。如图1(b)所示。给定一个输入张量,一小部分的通道会沿着空间的4个方向移动,即左、右、上、下,而其余的通道保持不变。在Shift之后,超出范围的像素被简单地删除,空白像素被填充为零。在本工作中,Shift步长设置为1像素。
形式上,假设输入特征z的形状为H×W×C,其中C为通道数,H和W分别为空间高度和宽度。输出特性z与输入特征具有相同的形状。它可以写成:

其中γ是一个比率因子来控制通道的百分比。在大多数实验中,γ的值被设置为1/12。

值得注意的是,Shift操作不包含任何参数或算术计算。唯一的实现是内存复制。因此,Shift操作效率高,易于实现。该伪代码在算法1中提出。与自注意力机制相比,Shift操作对TensorRT等深度学习推理库更干净、整洁、更友好。
Shift块的其余部分与ViT的标准构建块相同。MLP网络有2个线性层。第一个方法将输入特征的通道增加到一个更高的维度,例如,从C到τC。然后,第2个线性层将高维特征投影到c的原始通道大小中。在这两层之间,采用GELU作为非线性激活函数。
3.3 架构变体
为了与Baseline Swin Transformer进行比较,作者还构建了多个具有不同数量参数和计算复杂度的模型。具体来说,引入了Shift-T(iny)、Shift-S(mall)、Shift-B(ase)变种,分别对应于swin-t、swin-s和swin-b。Shift-T是最小的,它与Swin-T和ResNet-50的大小相似。另外两种变体,Shift-S和Shift-B,大约比shiftvit复杂2倍和4倍。基本嵌入通道C的详细配置和块数{}如下:

除了模型尺寸之外,作者还仔细观察了模型的深度。在提出的模型中,几乎所有的参数都集中在MLP部分。因此,可以控制MLP τ的扩展比来获得更深的网络深度。如果未指定,则将展开比率τ设置为2。消融分析表明,更深层次的模型获得了更好的性能。
4实现
4.1 消融实验
1、Expand ratio of MLP
之前的实验证明了本文的设计原则,即大的模型深度可以弥补每个构件的不足。通常,在模型深度和构建块的复杂性之间存在一种权衡。有了固定的计算预算,轻量级的构建块可以享受更深层次的网络工作架构。

为了进一步研究这种权衡,作者提供了一些具有不同深度的ShiftViT模型。对于ShiftViT,大多数参数存在于MLP部分。作者可以通过改变MLP τ的扩展比来控制模型深度。如表5所示,选择Shift-T作为基线模型。研究了在1到4范围内的扩张比τ。值得注意的是,不同条目的参数和FLOPs几乎是相同的。
从表5中,可以观察到一个趋势,即模型越深入,性能越好。当ShiftViT的深度增加到225时,在分类、检测和分割上分别比57层的分类、检测和分割的绝对增益提高了0.5%、1.2%和2.9%。这种趋势支持了猜想,即强大而沉重的模块,如attention,可能不是Backbone的最佳选择。
2、Percentage of shifted channels
Shift操作只有一个超参数,即移位信道的百分比。缺省情况下,设置为33%。在本节中探讨其他一些设置。具体来说,将移动通道的比例分别设置为20%、25%、33%和50%。结果如图3所示。这表明最终性能对这个超参数不是很敏感。与最佳设置相比,移动25%的通道只会导致0.3%的绝对损失。在合理的范围内(25%-50%),所有的设置都达到了比Swin-T Baseline更好的精度。
3、Shifted pixels
在Shift操作中,一小部分通道沿4个方向移动一个像素。为了进行全面的探索,还尝试了不同的移动像素。当偏移的像素为0,即没有发生偏移时,ImageNet数据集的Top-1精度仅为72.9%,明显低于本文的Baseline(81.7%)。这并不奇怪,因为没有移动意味着不同的空间位置之间没有相互作用。此外,如果在shift操作中移动两个像素,模型在ImageNet上达到80.2%的top-1精度,这也比默认设置略差。
4、ViT-style training scheme
Shift操作在cnn中已经得到了很好的研究。然而,以往的工作并没有像该工作那样令人印象深刻。Shift-ResNet-50在ImageNet上的准确率仅为75.6%,远低于81.7%的准确率。这一差距引发了一种自然的担忧,即什么对ViT有利。
作者怀疑原因可能在于虚拟现实式的训练计划。具体来说,大多数现有的ViT变体遵循DeiT中的设置,这与训练cnn的标准管道有很大不同。例如,ViT-style方案采用AdamW优化器,在ImageNet上训练时长为300 epoch。相比之下,cnn风格的方案更倾向于SGD优化器,训练计划通常只有90 epoch。由于本文的模型继承了ViT-style训练方案,观察这些差异如何影响性能是很有趣的。

由于资源限制,不能完全对齐所有设置之间的ViT-style和CNN-style。因此,选择了4个认为可以带来启示的重要因素,即优化器、激活函数、规范化层和训练计划。从表6可以看出,这些因素可以显著影响准确性,尤其是训练进度。这些结果表明,ShiftViT良好的性能部分是由ViT-style训练方案带来的。同样,ViT的成功也可能与其特殊的训练计划有关。在今后的ViT研究中应该认真对待这一问题。
4.2 ImageNet and COCO
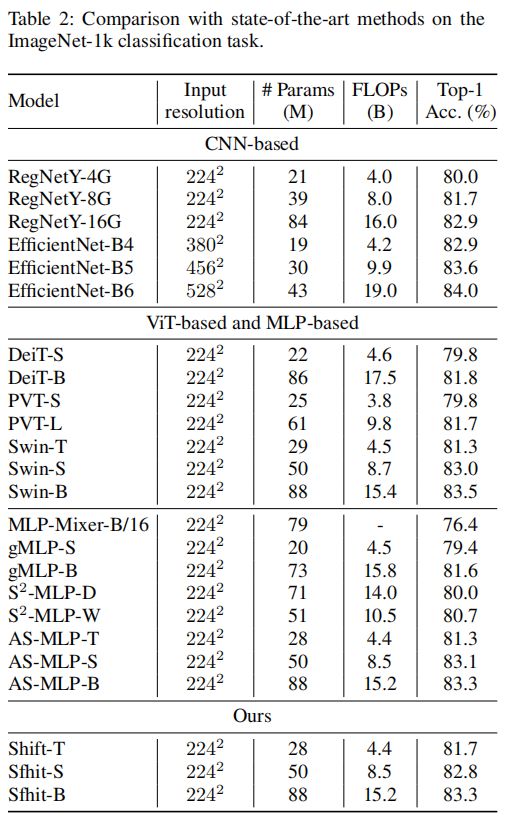
总的来说,本文的方法可以实现与最先进技术相媲美的性能。对于基于ViT和基于mlp的方法,其最佳性能约为83.5%,而本文的模型达到了83.3%的精度。对于基于CNN的方法,本文的模型略差于但是比较并不完全公平,因为EfficientNet采用更大的输入大小。
另一件有趣的事情是与2个工作S^2-MLP和AS-MLP。这两部分的工作在移Shift操作上有相似的想法,但是它们在构建块中引入了一些辅助模块,例如投影前层和投影后层。在表2中,本文的表现略好于这两项工作。这证明了设计选择,仅仅用一个简单的Shift操作就可以很好的搭建Backbone。

除了分类任务外,目标检测任务和语义分割任务也可以观察到相似的性能轨迹。值得注意的是,一些基于ViT和基于mlp的方法不容易扩展到如此密集的预测任务,因为高分辨率的输入产生了难以负担的计算负担。由于Shift操作的高效率,本文的方法不存在这种障碍。
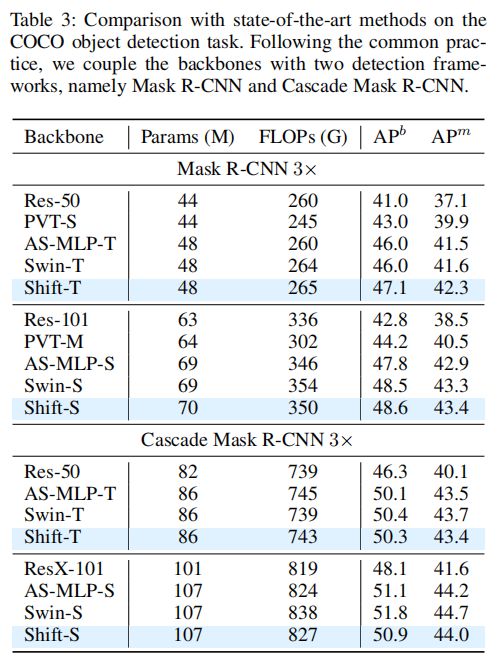
 表4
表4
如表3和表4所示,ShiftViT的优势是显而易见的。ShiftT在目标检测上的mAP得分为47.1分,在语义分割上的mIoU得分为47.8分,明显优于其他方法。
5参考
[1].When Shift Operation Meets Vision Transformer:An Extremely Simple Alternative to Attention Mechanism
本文仅做学术分享,如有侵权,请联系删文。
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有ORB-SLAM系列源码学习、3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、深度估计、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~