Deep Visual-Semantic Alignments for Generating Image Descriptions 翻译
Abstract
摘要
We present a model that generates natural language descriptions of images and their regions.
我们提出一个模型来生成图像及其区域的自然语言描述。
Our approach leverages datasets of images and their sentence descriptions to learn about the inter-modal correspondences between language and visual data。
我们的方法可以控制图像数据集和它们的句子描述,以了解语言和视觉数据之间的模式对应关系。
Our alignment model is based on a novel combination of Convolutional Neural Networks over image regions, bidirectional Recurrent Neural Networks over sentences, and a structured objective that aligns the two modalities through a multimodal embedding.
我们的对齐模型基于图像区域上的卷积神经网络,句子上的双向递归神经网络以及通过多模式嵌入来对齐两种模态的结构化目标的新型组合。
We then describe a Multimodal Recurrent Neural Network architec- ture that uses the inferred alignments to learn to generate novel descriptions of image regions.
然后我们描述一个多模态递归神经网络结构,它使用推断的对齐来学习生成图像区域的新颖描述。
We demonstrate that our alignment model produces state of the art results in retrieval experiments on Flickr8K, Flickr30K and MSCOCO datasets.
我们证明我们的对齐模型可以在Flickr8K,Flickr30K和MSCOCO数据集上进行恢复实验。
We then show that the generated descriptions significantly outperform retrieval baselines on both full images and on a new dataset of region-level annotations.
然后,我们显示生成的描述在整幅图像和区域级注释的新数据集上均优于检索基线。
1. Introduction
1.介绍
A quick glance at an image is sufficient for a human to point out and describe an immense amount of details about the visual scene [14].
快速浏览一幅图像足以让人指出并描述关于视觉场景的大量细节[14]。
However, this remarkable ability has proven to be an elusive task for our visual recognition models.
然而,这种卓越的能力已被证明是我们的视觉识别模型难以捉摸的任务。
The majority of previous work in visual recognition has focused on labeling images with a fixed set of visual categories and great progress has been achieved in these endeavors [45, 11].
以前的大多数视觉识别工作都集中在用一组固定的视觉类别来标记图像,并且在这些工作中取得了很大的进展[45,11]。
However, while closed vocabularies of visual concepts constitute a convenient modeling assumption, they are vastly restrictive when compared to the enormous amount of rich descriptions that a human can compose.
然而,虽然关于视觉概念的封闭词汇构成了一个方便的建模假设,但与人类可以构成的大量丰富的描述相比,它们是极其严格的限制性的。Some pioneering approaches that address the challenge of generating image descriptions have been developed [29, 13].
已经发明了一些开创性的方法来解决生成图像描述的挑战[29,13]。
However, these models often rely on hard-coded visual concepts and sentence templates, which imposes limits on their variety.
然而,这些模型通常依赖于硬编码的视觉概念和句子模板,这就对其种类施加了限制。
Moreover, the focus of these works has been on reducing complex visual scenes into a single sentence, which we consider to be an unnecessary restriction.
而且,这些作品的重点在于将复杂的视觉场景缩减为单个句子,我们认为这是一个不必要的限制。
Figure 1. Motivation/Concept Figure: Our model treats language as a rich label space and generates descriptions of image regions.
图1.动机/概念图:我们的模型将语言视为丰富的标签空间,并生成图像区域的描述。
In this work, we strive to take a step towards the goal of
generating dense descriptions of images (Figure 1).
在这项工作中,我们努力朝着生成图像的密集描述的目标迈进(图1)。
The primary challenge towards this goal is in the design of a model that is rich enough to simultaneously reason about contents of images and their representation in the domain of natural language.
实现这一目标的主要挑战是设计一个足够丰富的模型,以同时推理图像的内容及其在自然语言领域的表现。
Additionally, the model should be free of assumptions about specific hard-coded templates, rules or categories and instead rely on learning from the training data.
此外,该模型应该没有关于具体的硬编码模板,规则或类别的假设,而是依赖于从训练数据中学习。
The second, practical challenge is that datasets of image captions are available in large quantities on the internet [21, 58, 37], but these descriptions multiplex mentions of several entities whose locations in the images are unknown.
第二个实际的挑战是图像标题的数据集可以在互联网上大量使用[21,58,37],但是这些描述复合了几个图像中位置未知的实体的提及。Our core insight is that we can leverage these large image- sentence datasets by treating the sentences as weak labels, in which contiguous segments of words correspond to some particular, but unknown location in the image.
我们的核心观点是,我们可以通过将句子视为弱标签来利用这些大型的图像 - 句子数据集,其中连续的单词片段对应于图像中的某个特定但未知的位置。
Our approach is to infer these alignments and use them to learn a generative model of descriptions. Concretely, our contributions are twofold:
我们的方法是推断这些对齐,并使用它们来学习描述的生成模型。 具体来说,我们的贡献是双重的:We develop a deep neural network model that infers the latent alignment between segments of sentences and the region of the image that they describe.
我们开发了一个深层的神经网络模型,该模型提供了句子之间的部分和他们描述的图像区域之间的潜在对齐。
Our model associates the two modalities through a common, multimodal embedding space and a structured objective.
我们的模型通过一个共同的多模式嵌入空间和一个结构化的目标将这两种模式联系起来。
We validate the effectiveness of this approach on image-sentence retrieval experiments in which we surpass the state-of-the-art.
我们验证了这种方法在图像句子检索实验中的有效性,其中我们超越了现有技术。
We introduce a multimodal Recurrent Neural Network architecture that takes an input image and generates its description in text.
我们引入了一种多模态递归神经网络架构,它采用输入图像并在文本中生成其描述。
Our experiments show that the generated sentences significantly outperform retrieval-based baselines, and produce sensible qualitative predictions.
我们的实验表明,生成的句子明显优于基于检索的基线,并产生明智的定性预测。
We then train the model on the inferred correspondences and evaluate its performance on a new dataset of region-level annotations.
然后,我们根据推断的对应关系对模型进行训练,并在一个新的地区级注释数据集上评估其性能。
We make code, data and annotations publicly available.
我们公开提供代码,数据和注释。2. Related Work
2.相关工作
Dense image annotations.
密集的图像注释。
Our work shares the high-level goal of densely annotating the contents of images with many works before us.
我们的作品与我们面前的许多作品都有对图像内容进行密集注释的高级目标。
Barnard et al. [2] and Socher et al. [48] studied the multimodal correspondence between words and images to annotate segments of images.
巴纳德等[2]和Socher等[48]研究了单词和图像之间的多模态对应以注释图像的分段。
Several works [34, 18, 15, 33] studied the problem of holistic scene understanding in which the scene type, objects and their spatial support in the image is inferred.
一些作品[34,18,15,33]研究了整体场景理解的问题,在这个问题中,图像中的场景类型,对象及其空间支持被推断出来。
However, the focus of these works is on correctly labeling scenes, objects and regions with a fixed set of categories, while our focus is on richer and higher-level descriptions of regions.
但是,这些作品的重点在于正确地标注具有固定类别的场景,对象和区域,而我们的重点是对区域的更丰富和更高级的描述。Generating descriptions.
生成描述。
The task of describing images with sentences has also been explored。
用句子描述图像的任务也被探索。
A number of approaches pose the task as a retrieval problem, where the most compatible annotation in the training set is transferred to a test image [21, 49, 13, 43, 23], or where training annotations are broken up and stitched together [30, 35, 31].
许多方法将任务视为一个检索问题,其中训练集中最兼容的注释转移到测试图像上[21,49,13,43,23],或者训练注释被分解的地方并缝合在一起[30,35,31]。
Several approaches generate image captions based on fixed templates that are filled based on the content of the image [19, 29, 13, 55, 56, 9, 1] or generative grammars [42, 57], but this approach limits the variety of possible outputs.
有几种方法基于基于图像内容填充的固定模板[19,29,13,55,56,9,1]或生成语法[42,57]生成图像标题,但是这种方法限制了图像标题可能的产出。
Most closely related to us, Kiros et al. [26] developed a logbilinear model that can generate full sentence descriptions for images, but their model uses a fixed window context while our Recurrent Neural Network (RNN) model conditions the probability distribution over the next word in a sentence on all previously generated words.
Kiros等人与我们关系最为密切。[26]开发了一个对数线性模型,可以为图像生成完整的句子描述,但是他们的模型使用了一个固定的窗口上下文,而我们的循环神经网络(RNN)模型对已经生成的一个句子中的下一个单词中可能性分布进行了调整。
Multiple closely related preprints appeared on Arxiv during the submission of this work, some of which also use RNNs to generate image descriptions [38, 54, 8, 25, 12, 5].
Arxiv在提交这项工作时出现了多个密切相关的预印本,其中一些还使用RNN生成图像描述[38,54,8,25,12,5]。
Our RNN is simpler than most of these approaches but also suffers in performance. We quantify this comparison in our experiments.
我们的RNN比大多数这些方法更简单,但也有性能受损。我们在我们的实验中量化这个比较。Grounding natural language in images.
在图像中引入自然语言。
A number of approaches have been developed for grounding text in the visual domain [27, 39, 60, 36].
已经开发了许多方法来处理视域中的文字[27,39,60,36]。
Our approach is inspired by Frome et al. [16] who associate words and images through a semantic embedding.
我们的方法受Frome等人的启发。
[16]通过语义嵌入关联词和图像。
More closely related is the work of Karpathy et al.[24], who decompose images and sentences into fragments and infer their inter-modal alignment using a ranking objective.
更密切相关的是Karpathy等人的工作。[24],他们将图像和句子分解成片段,并使用排名目标来推断它们的模式间对齐。
In contrast to their model which is based on grounding dependency tree relations, our model aligns contiguous segments of sentences which are more meaningful, interpretable, and not fixed in length.
与他们的基于地面依赖树关系的模型相比,我们的模型对齐连续的句子段更有意义,而且是可解释的并且长度是不固定的。
Neural networks in visual and language domains.
视觉和语言领域的神经网络。
Multiple approaches have been developed for representing images and words in higher-level representations.
已经开发了多种方法来表示更高级别表示中的图像和文字。
On the image side, Convolutional Neural Networks (CNNs) [32, 28] have recently emerged as a powerful class of models for image classification and object detection [45].
在图像方面,卷积神经网络(CNNs)[32,28]最近已经成为一个强大的图像分类和目标检测模型[45]。
On the sentence side, our work takes advantage of pretrained word vectors [41, 22, 3] to obtain low-dimensional representations of words.
在公共方面,我们的工作利用预训练词向量[41,22,3]来获得词的低维表示。
Finally, Recurrent Neural Networks have been previously used in language modeling [40, 50], but we additionally condition these models on images.
最后,递归神经网络已经被用于语言建模[40,50],但是我们在图像上另外调整这些模型。3. Our Model
3.我们的模型
Overview. The ultimate goal of our model is to generate descriptions of image regions.
概述。我们模型的最终目标是生成图像区域的描述。
During training, the input to our model is a set of images and their corresponding sentence descriptions (Figure 2).
在训练期间,我们模型的输入是一组图像及其相应的句子描述(图2)。
We first present a model that aligns sentence snippets to the visual regions that they describe through a multimodal embedding.
我们首先提出一个模型,将句子片段与通过多模式嵌入描述的视觉区域对齐。
We then treat these correspondences as training data for a second, multimodal Recurrent Neural Network model that learns to generate the snippets.
然后,我们把这些对应关系作为第二个多模态递归神经网络模型的训练数据,学习生成片段。
3.1. Learning to align visual and language data
3.1 学习调整视觉和语言数据
Our alignment model assumes an input dataset of images and their sentence descriptions.
我们的对齐模型假定了图像的输入数据集和它们的句子描述
Our key insight is that sentences written by people make frequent references to some particular, but unknown location in the image.
我们的主要观点是,人们写的句子经常提到一些特定但未知的图像位置。
For example, in Figure 2, the words “Tabby cat is leaning” refer to the cat, the words “wooden table” refer to the table, etc.
例如,在图2中,“虎斑猫正在倾斜”一词指的是猫,“木桌”这个词是指桌子等
We would like to infer these latent correspondences, with the eventual goal of later learning to generate these snippets from image regions.
我们想要推断这些潜在的对应关系,最终的目标是后面的学习从图像区域生成这些片段。
We build on the approach of Karpathy et al. [24], who learn to ground dependency tree relations to image regions with a ranking objective.
我们建立在Karpathy等人的方法上。他们学习将依赖树关系映射到具有排名目标的图像区域。
Our contribution is in the use of bidirectional recurrent neural network to compute word representations in the sentence, dispens- ing of the need to compute dependency trees and allowing unbounded interactions of words and their context in the sentence.
我们的贡献在于使用双向递归神经网络来计算句子中的单词表示,因为需要计算依赖性树,并且允许单词和它们在句子中的上下文无限的相互作用。
We also substantially simplify their objective and show that both modifications improve ranking performance.
我们也大大简化了他们的目标,并显示这两个修改提高排名表现。We first describe neural networks that map words and image regions into a common, multimodal embedding.
我们首先描述将单词和图像区域映射成共同的多模式嵌入的神经网络。
Then we introduce our novel objective, which learns the embedding representations so that semantically similar concepts across the two modalities occupy nearby regions of the space.
然后,我们介绍我们的创新目标,它学习嵌入表示,使两个模式中的语义相似的概念占据空间的附近区域。
3.1.1 Representing images
3.1.1 代表图像
Following prior work [29, 24], we observe that sentence de- scriptions make frequent references to objects and their at- tributes.
继之前的工作[29,24],我们观察到,句子描述经常提及物体及其属性。
Thus, we follow the method of Girshick et al.
因此,我们遵循Girshick等人的方法。
[17] to detect objects in every image with a Region Convolu- tional Neural Network (RCNN).
[17]用区域卷积神经网络(RCNN)检测每个图像中的物体。
The CNN is pretrained on ImageNet [6] and finetuned on the 200 classes of the ImageNet Detection Challenge [45].
CNN在ImageNet上进行了预先训练[6],并对ImagNet Detection Challenge [200]的200个类进行了调整。
Following Karpathy et al. [24], we use the top 19 detected locations in addition to the whole image and compute the representations based on the pixels Ib inside each bounding box as follows:
继Karpathy等人 [24],除了整个图像,我们使用前19个检测位置,并计算基于每个边界框内的像素Ib的表示如下: 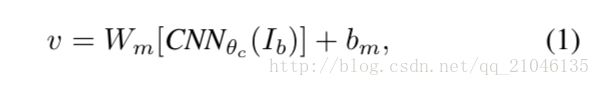
where CNN(Ib) transforms the pixels inside bounding box Ib into 4096-dimensional activations of the fully connected layer immediately before the classifier.
其中CNN(Ib)在分类器之前立即将边界框Ib内的像素转换成完全连接层的4096维激活。
The CNN parameters ✓c contain approximately 60 million parameters. The matrix Wm has dimensions h * 4096, where h is the size of the multimodal embedding space (h ranges from 1000-1600 in our experiments).
CNN参数✓c包含大约6000万参数。 矩阵Wm的尺寸 h⇥4096,其中 h 是多峰嵌入空间的大小(h在我们的实验中在1000-1600之间)。
Every image is thus represented as a set of h-dimensional vectors {vi | i = 1...20}.
因此,每个图像被表示为一组h维向量{vi | i = 1 ... 20}。
3.1.2 Representing sentences
3.1.2代表句子
To establish the inter-modal relationships, we would like to represent the words in the sentence in the same h-dimensional embedding space that the image regions occupy.
为了建立模式间的关系,我们希望在句子中用相同的h维嵌入空间表示图像区域。
The simplest approach might be to project every individual word directly into this embedding.
最简单的方法可能是将每个单词直接投影到这个嵌入中。
However, this approach does not consider any ordering and word context information in the sentence.
但是,这种方法不考虑句子中的任何排序和词语环境信息。
An extension to this idea is to use word bigrams, or dependency tree relations as pre- viously proposed [24].
这个思想的扩展是使用前面提出的词“bigrams”或依赖关系树关系[24]。
However, this still imposes an arbitrary maximum size of the context window and requires the use of Dependency Tree Parsers that might be trained on unrelated text corpora.
然而,这仍然强加上下文窗口的任意最大大小,并且需要使用可能在不相关的文本语料库上训练的依赖树解析器。
To address these concerns, we propose to use a Bidirec- tional Recurrent Neural Network (BRNN) [46] to compute the word representations.
为了解决这些问题,我们建议使用双向递归神经网络(BRNN)[46]来计算词语表示。
The BRNN takes a sequence of
N words (encoded in a 1-of-k representation) and transforms each one into an h-dimensional vector.
BRNN需要一系列的N个词(以1的k表示编码)并将每个词转换成h维向量。
However, the representation of each word is enriched by a variably-sized context around that word.
然而,每个单词的表示都是围绕这个单词的变化大小来加以丰富的。
Using the index t = 1 . . . N to denote the position of a word in a sentence, the precise form of the BRNN is as follows:
使用索引t = 1。 。 。 N表示一个单词在句子中的位置,BRNN的确切形式如下: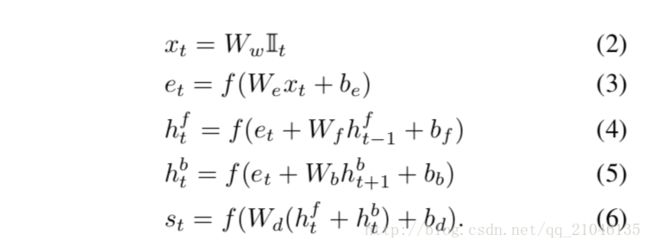
Here, t is an indicator column vector that has a single one at the index of the t-th word in a word vocabulary.
这里,t是在单词词汇表中第t个单词的索引处具有唯一一个的指标列向量。
The weights Ww specify a word embedding matrix that we ini- tialize with 300-dimensional word2vec [41] weights and keep fixed due to overfitting concerns.
权重ww指定一个字嵌入矩阵,我们用300维的word2vec [41]权重初始化,并由于过度拟合的担忧而保持固定。
However, in practice we find little change in final performance when these vectors are trained, even from random initialization.
然而,实际上,当这些向量被训练时,即使从随机初始化,我们也发现最终性能几乎没有变化。
Note that the BRNN consists of two independent streams of pro- cessing, one moving left to right (hft ) and the other right to left (hbt ) (see Figure 3 for diagram).
注意,BRNN由两个独立的处理流组成,一个从左到右(hft),另一个从右到左(hbt)(见图3的图)。
The final h-dimensional representation st for the t-th word is a function of both the word at that location and also its surrounding context in the sentence.
第t个单词的最终h维表示st是句子中该单词和其周围上下文的函数。
Technically, every st is a function of all words in the entire sentence, but our empirical finding is that the final word representations (st) align most strongly to the visual concept of the word at that location ( t).
从技术上讲,每个st都是整个句子中所有单词的函数,但是我们的经验发现是,最终的单词表示(st)与该单词在该位置(t)的视觉概念最为一致。
We learn the parameters We , Wf , Wb , Wd and the respective biases be, bf , bb, bd.
我们学习参数We,Wf,Wb,Wd和相应的偏差为bf,bb,bd。
A typical size of the hidden rep- resentation in our experiments ranges between 300-600 dimensions. We set the activation function f to the rectified linear unit (ReLU), which computes f : x -> max(0, x).
在我们的实验中隐藏代表的典型大小在300-600维之间。我们将激活函数f设置为整流线性单元(ReLU),计算f:x 7! max(0,x)。3.1.3 Alignment objective
3.1.3 对准目标
We have described the transformations that map every image and sentence into a set of vectors in a common h-dimensional space.
我们已经描述了将每个图像和句子映射到共同的h维空间中的一组向量的转换。
Since the supervision is at the level of entire images and sentences, our strategy is to formulate an image-sentence score as a function of the individual region- word scores.
由于监督是在整个图像和句子的水平,我们的策略是制定一个图像-句子分数作为个别地区单词分数的函数。
Intuitively, a sentence-image pair should have a high matching score if its words have a confident support in the image.
直观地说,如果一个句子在图像中有一个自信的支持,那么它应该有一个高的匹配分数。
The model of Karpathy et a. [24] interprets the dot product viT st between the i-th region and t-th word as a measure of similarity and use it to define the score between image k and sentence l as:
Karpathy等人的模型[24]将第i个区域和第t个单词之间的点积viT st解释为相似性度量,并用它来定义图像k和句子l之间的分数为:
Here, gk is the set of image fragments in image k and gl is the set of sentence fragments in sentence l.
这里,gk是图像k中的图像片段集合,而gl是句子l中的句子片段集合。
The indices k, l range over the images and sentences in the training set.
指数k,l在训练集中的图像和句子的范围内。
Together with their additional Multiple Instance Learning objective, this score carries the interpretation that a sentence fragment aligns to a subset of the image regions whenever the dot product is positive.
再加上他们的多重实例学习目标,这个分数的解释就是,只要点积是正的,句子片段就与图像区域的一个子集对齐。
We found that the following reformulation simplifies the model and alleviates the need for additional objectives and their hyperparameters:
我们发现,下面的修改简化了模型,减少了对额外目标和超参数的需求: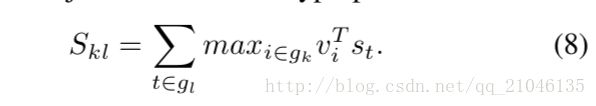
这里,每个单词st对齐到单个最佳图像区域。 正如我们在实验中所展示的,这个简化的模型也导致了最终排名表现的改善。 假设k = 1表示相应的图像和句子对,则最终的最大边缘结构损失仍然是:

这个目标鼓励对齐的图像句子对比不对齐的对有更高的分数。
3.1.4 将文本段对齐解码为图像
考虑训练集及其对应句子的图像。我们可以将数量viT st解释为描述图像中任何边界框的第t个单词的非归一化对数概率。但是,由于我们最终希望生成文本片段而不是单个单词,因此我们希望将扩展连续的单词序列与单个边界框对齐。请注意,将每个词独立分配给得分最高的区域的原始解决方案不足,因为这会导致词语不一致地分散到不同的区域。

为了解决这个问题,我们将真正的对齐作为一个马尔可夫随机场(MRF)中的潜在变量来处理,在这个马尔可夫随机场(MRF)中,相邻单词之间的二元相互作用促进了对同一个区域的对齐。具体来说,给定一个包含N个单词的句子和一个包含M个边界框的图像,我们引入潜在的对齐变量aj∈{1。 。 。 M}为j = 1 … N,并沿着句子在链式结构中形成一个MRF如下:

在这里,β是一个超参数,控制对较长的单词短语的亲和力。这个参数允许我们在单词比对(β= 0)之间进行插值,并且当β很大时,将整个句子对齐到一个单一的最大得分区域。我们通过动态编程将能量最小化以找到最佳对齐方式。这个过程的输出是一组使用文本段注释的图像区域。我们现在描述一种基于这些对应关系生成新词组的方法。
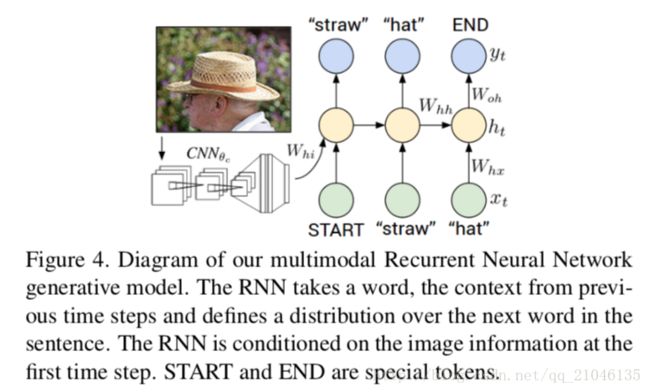
3.2用于生成描述的多模态递归神经网络
在本节中,我们假设一组输入图像及其文本描述。这些可以是完整的图像和他们的句子描述,或区域和文本片段,如前一节所述。关键的挑战是设计一个模型,可以预测给定图像的可变尺寸输出序列。在以前发展的基于递归神经网络(RNNs)的语言模型中[40,50,10],这是通过定义一个序列中下一个词的概率分布来实现的,给定当前词和前一时间步长。
我们探索一个简单而有效的扩展,它对输入图像内容的生成过程进行了调整。更一般地,在训练期间,我们的多模式RNN将图像像素I和一系列输入向量(x1,…,xT)。然后通过迭代t = 1的下列递归关系到T来计算一系列隐藏状态(h1,…,ht)和一系列输出(y1,…,yt)
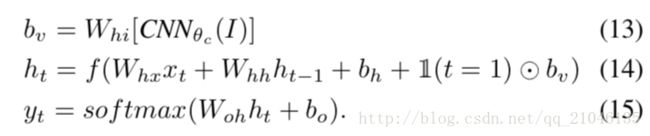
在上面的等式中,Whi,Whx,Whh,Woh,xi和bh,bo是可学习的参数,而CNN(c)是CNN的最后一层。输出向量yt保存字典中单词的(非标准化的)对数概率和特殊结束标记的一个附加维度。请注意,我们只在第一次迭代时将图像上下文向量bv提供给RNN,我们发现它比每个时间步都更好地工作。在实践中,我们也发现通过激活函数可以同时通过bv,(Whx xt)。 RNN隐藏层的典型大小是512个神经元。
RNN训练。 RNN训练将一个字(xt),前一个上下文(ht-1)组合起来,以预测下一个字(yt)。我们通过第一步的偏置交互来调整RNN对图像信息(bv)的预测。训练过程如下(参见图4):我们将h0 =〜0,x1设置为一个特殊的START向量,并将所需的标签y1设置为序列中的第一个字。类似地,我们将x2设置为第一个单词的单词向量,并期望网络预测第二个单词等等。最后,如果x表示最后一个单词,则目标标签被设置为特殊的END标记。成本函数是最大化分配给目标标签的对数概率(即Softmax分类器)。
RNN在测试时间。为了预测句子,我们计算图像表示bv,将h0 = 0,x1设置为START矢量,并计算第一个单词y1的分布。我们从分布中抽取一个单词(或者挑选argmax),将其嵌入向量设置为x2,然后重复这个过程,直到生成END令牌。实际上,我们发现光束搜索(例如光束尺寸7)可以改善结果。
3.3。优化
我们使用SGD以100个图像句子对的小批量和0.9的动量来优化对齐模型。我们使用交叉验证学习率和权重衰减。我们也在所有图层中使用了压缩正则化,除了在重复图层中[59]和在5(重要)下基本上剪切梯度。由于稀有词和普通词(例如“a”或END词)之间的词频差异,生成的RNN更难以优化。我们使用RMSprop [52]获得了最好的结果,这是一种自适应步长的方法,通过其梯度范数的移动平均来缩放每个权重的更新。
4.实验
数据集。我们在实验中使用Flickr8K [21],Flickr30K [58]和MSCOCO [37]数据集。这些数据集分别包含8,000,31,000和123,000个图像,每个图像都使用Amazon Mechanical Turk进行5个句子的注释。对于Flickr8K和Flickr30K,我们使用1,000个图像进行验证,1,000个用于测试,剩下的用于训练(与[21,24]一致)。对于MSCOCO,我们使用5000个图像进行验证和测试。
数据预处理。我们将所有句子转换为小写,丢弃非字母数字字符。我们对训练集中至少出现5次的单词进行过滤,分别得到Flickr8k,Flickr30K和MSCOCO数据集的2538,7414和8791个单词。
4.1。图像句子对齐评估
我们首先调查推断的文字和图像对齐排名实验的质量。我们考虑一组图像和句子,并通过基于图像 - 句子分数Skl(3.1.3节)的排序给出另一个模式的查询。我们报告列表中距离最近的地面真值结果的中间等级和Recall @ K,其测量在最高K结果中找到正确项目的次数的分数。这些实验的结果可以在表1中找到,并在图5中查找示例。现在我们重点介绍一些外观。
我们的完整模型胜过以前的工作。首先,我们的完整模型(“我们的模型:BRNN”)胜过Socher等人。 [49]谁训练出来的损失是类似的,但使用单一的图像表示和递归神经网络的句子。 Kiros等人也得到了类似的损失,他使用LSTM [20]编码句子。我们用一个相当于CNN(AlexNet [28])的方法列出了他们的表现,与这个工作中使用的CNN相似[54],但是他们使用更强大的CNN(VGGNet [47],GoogLeNet [51])。 “DeFrag”是Karpathy等人报道的结果。 [24]。由于我们使用不同的词向量,正则化的丢失和不同的交叉验证范围以及更大的嵌入尺寸,我们重新实现了公平比较的损失(“DeFrag的实现”)。与其他使用AlexNets的工作相比,我们的完整模型显示了持续改进。
我们通过简单成本提高了性能。我们努力更好地了解达到这种表现的原因。首先,我们删除了BRNN,并使用了与Karpathy等人所描述的依赖关系树关系。 [24](“我们的模型:DepTree边缘”)。这个模型与“我们重新实现DeFrag”的唯一区别是3.1.3节介绍的新的,更简单的成本函数。我们看到我们的表述显示了一致的改进。
BRNN优于依赖树关系。另外,当我们用BRNN替换依赖树关系时,我们观察到了额外的性能改进。由于依赖关系表现出比单个词和两个词更好的工作[24],这表明BRNN正在利用长于两个词的上下文。此外,我们的方法不依赖于提取依赖树,而是直接使用原始单词。
MSCOCO的结果为未来的比较。我们不知道其他公布的MSCOCO排名结果。
因此,我们报告1,000个图像的子集和5000个测试图像的全套集合,以供将来进行比较。请注意,由于Re-call @ K是测试集大小的函数,因此5000个图像数字较低。
定性。从图5的例子可以看出,该模型发现了可解释的视觉 - 语义对应,即使对于小型或相对罕见的物体,如“手风琴”,也是如此。这些可能会被那些只有完整图像的原因的模型所遗漏。
学到的区域和词矢量幅度。我们模型的一个重要特征是它学习调制区域的大小和字嵌入。由于内在的相互作用,我们观察到,像“皮划艇,南瓜”这样具有视觉辨别力的单词的表示具有较高磁性的嵌入向量,这反过来又转化为对图像句子分数的较高影响。相反,停止诸如“现在,简单地,实际上,但是”这样的词被映射到原点附近,这减少了它们的影响。请参阅补充材料中的更多分析。
4.2。生成的描述:Fulframe评估
我们现在评估我们的RNN模型描述图像和区域的能力。我们首先训练了我们的Multimodal RNN在完整图像上生成句子,目的是验证模型足够丰富,以支持从图像数据到单词序列的映射。对于这些完整的图像实验,我们使用更强大的VGGNet图像特征[47]。我们报告用Coco-caption代码[4]计算的BLEU [44],METEOR [7]和CIDEr [53]得分。每种方法通过测量一个人类写的候选语句
定性。该模型生成图像的合理描述(见图6),尽管我们考虑了最后两个图像的失败情况。第一个预言“黑衬衫的男人在弹吉他”并没有出现在训练集中。然而,“黑衬衫男”出现20次,“吉他付费”出现60次,可能是模型用来形容第一个形象。一般而言,我们发现在训练数据中可以找到相对大部分的生成句子(60%,波束大小为7)。这个分数随着光束尺寸减小而减小;例如,光束大小1降到25%,但性能也变差(例如从0.66到0.61 CIDEr)。
多模RNN优于检索基准。我们的第一个比较是最近邻的检索基线。

在这里,我们注释每个测试图像与一个最相似的训练集图像由L2规范决定的VGGNet [47] fc7功能的句子。从表2可以看出,多重RNN的表现比这种检索方法更胜一筹。因此,即使在MSCOCO中有113,000个训练集图像,检索方法也是不足的。此外,RNN只需要几分之一秒来评估每个图像。
与其他工作比较。自从这项工作的最初提交以来,Arxiv预印本已经提出了几个相关的模型。表2还包括了这些比较。与我们的模型最相似的是Vinyals等。 [54]。与第一步通过偏倚项传递图像信息的工作不同,这些工作将它作为第一个词汇,使用更强大但更复杂的序列学习器(LSTM [20]),不同的CNN (GoogLeNet [51]),并报告模型集合的结果。 Donahue等人[8]使用2层因子LSTM(在结构上类似于毛等人的RNN [38])。这两种模式似乎比我们的工作更糟糕,但这很可能在很大程度上是由于他们使用不太强大的AlexNet [28]功能。与这些方法相比,我们的模型优先考虑简单性和速度,而且性能稍微低一些。
4.3。生成的描述:区域评估
现在我们根据对齐模型的推导,对图像区域和文本片段之间的对应关系进行多模式RNN训练。为了支持评估,我们使用Amazon Mechanical Turk(AMT)来收集我们只在测试时使用的区域级注释的新数据集。标签界面显示单个图像,并要求注释者(我们每个图像使用九个)绘制五个边界框,并用文本注释。总的来说,我们在MSCOCO测试版本中为200张图片收集了9000个文本片段(即每张图片有45个片段)。片段平均长度为2.3字。示例注释包括“跑车”,“以前坐的夫妇”,“建筑工地”,“三只狗在皮带上”,“巧克力蛋糕”。我们注意到,要求注释的文本摘要与全图像标题中的统计信息不同。我们的区域符号更全面,并且特征很少被认为足以被包含在关于整个图像的单个句子中的突出显示的元素,诸如“加热通风口”,“皮带扣”和“烟囱”。
定性。我们在图7中显示了示例区域模型预测。为了重申任务的难度,例如考虑在图7右侧的图像上生成的短语“带酒杯的桌子”。该短语仅出现在训练集中30次。每次它可能有不同的外观,每一次它可能占用我们的对象边界框中的几个(或没有)。为了生成这个区域的字符串,模型必须首先正确地学习将字符串打底,然后学习生成它。
区域模型优于全帧模型和排名基线。类似于完整的图像描述任务,我们评估这个数据作为一个预测任务从像素的二维数组(一个图像区域)到一系列单词并记录BLEU评分。排名基线检索与BRNN模型判断的每个区域最相容的训练语句子串。表3显示区域RNN模型产生与我们收集的数据最一致的描述。请注意,全帧模型仅在完整图像上进行了训练,因此向较小的图像区域馈送会降低其性能。然而,其句子也比区域模型句子更长,这可能对BLEU评分产生负面影响。句子长度对于用RNN进行控制是非平凡的,但是我们注意到区域模型在所有其他指标上也优于全帧模型:区域/全帧的CIDEr 61.6 / 20.3,METEOR 15.8 / 13.3,ROUGE 35.1 / 21.0 。

4.4 限制
虽然我们的结果令人鼓舞,但多模态RNN模型受到多重限制。首先,模型只能以固定的分辨率生成一个像素输入数组的描述。更明智的做法可能是在图像周围使用多次扫视,以在生成描述之前识别所有实体,它们的相互作用和更广泛的上下文。另外,RNN只通过加性偏差相互作用接收图像信息,这种相互作用已知比较复杂的多重相互作用表现性更差[50,20]。最后,我们的方法由两个独立的模型组成。直接从图像句子数据集到区域级注释,作为端对端培训的单一模型的一部分仍然是一个悬而未决的问题。
5 结论
我们引入了一个模型,基于图像和句子的数据集形式的弱标签生成图像区域的自然语言描述,并且硬编码假设很少。我们的方法提供了一种新颖的排名模型,通过共同的多模式嵌入来对齐视觉和语言模式的各个部分。我们发现,这个模型提供了图像 - 句子排名实验的最先进的表现。其次,我们描述了一种多模态递归神经网络架构,该架构生成可视数据的描述。我们评估了它在全帧和区域级实验的性能,并显示在这两种情况下,多模态RNN都优于检索基线。