「TensorFlow 2.3.1」学习他人程序——通过自己的数据集训练模型
文章目录
- Chapter 1 简介
- Chapter 2 环境配置
- Chapter 3 程序解释
-
- Part 1 *A_format_conversion.py*
- Part 2 *B_data_splite.py*
- Part 3 *C_train_cnn.py*
- Part 4 *D_train_mobilenet.py*
- Part 5 *E_test.py*
- Part 6 *F_windows.py*
- Chapter 4 小结
通过这个文档、程序你可以做些什么?
- 可以通过自己的数据集来训练模型
- 可以了解到TensorFlow以及Keras的基本使用方法
- 可以了解到TensorFlow以及Keras的Python程序编写方法(相当于一个案例)
- 了解到一些基本原理
- 规范代码书写格式
这篇是我根据我的理解对于原程序进行的一个非常浅的解释或者是标注。同时根据个人经历补充了一些关于环境配置方面的浅显的心得。
本文仅代表我的学习记录。原视频原程序还请访问哔哩哔哩UP主:肆十二- UID:821429104
在这里再次感谢UP主提供了优质的程序案例供我们学习。
Chapter 1 简介
这段程序是我从Bilibili上的一个UP主那里找到的,名字叫做:肆十二- UID:821429104(PS:顺道也关注我一下呗 UID:291463255)
具体的视频链接如下: 手把手教你用tensorflow2训练自己的数据集
我根据原UP主的程序进行了一些小小的增添修改,便于使用
Chapter 2 环境配置
首先电脑上需要安装Python 3.8 以及 conda 环境,可以通过 anaconda 进行安装
并创建一个新的conda环境。yourEnvName代表着你的新conda环境的名字。
conda create --name yourEnvName python=3.8
激活刚才创建的conda环境
windows ==> activate yourEnvName
linux/mac ==> source activate yourEnvName
常用的conda指令
conda info --envs:输出中带有【*】号的的就是当前所处的环境
conda list: 看这个环境下安装的包和版本
conda install numpy scikit-learn: 安装numpy sklearn包
conda env remove -n yourEnv: 删除你的环境
conda env list: 查看所有的环境
至于如何安装conda环境,可以单独安装也可以通过anaconda一起安装。
Windows上的开发环境比较特殊,需要先从Python官网下载Python安装包来安装Python,具体的安装版本为3.8,但实际测试3.7和3.9版本貌似也没什么太大问题,但我还是推荐安装3.8版本的。
Mac用户和Ubuntu用户则按照正常的方式安装就行,有啥问题可以自行百度或者Google。
至于说TensorFlow是安装CPU版本的还是GPU版本的,这个貌似是在2.0版本之后都整合到一个安装包里去了,程序会先检测你的电脑有无正确安装显卡以及对应的CUDA和CUDNN,如果能行就会使用GPU进行训练,没有的话就会使用CPU进行训练。
为了保证训练的速度,你的CPU最好支持AVX-2指令集或者AVX指令集。这样程序能正常运行,如果没有AVX指令集的话,要么换个电脑跑要么从TensorFlow官网下载一个支持不包含AVX指令集处理器的TensorFlow安装包进行安装。我要是没记错的话,貌似本次使用的TensorFlow2.3.1没有这个特殊的安装包。如果你说要换一个版本的TensorFlow呢?也不行,这个程序就支持2.3.1版本的TensorFlow,因为要使用到当中的一些特殊的API,高一个或者低一个版本都没有这个API,程序就没有办法跑,所以只能这样。
当时配这个环境配了差不多有一周才成功地让TensorFlow跑起来,又花了一周时间让TensorFlow在GPU上跑起来。安装过程简直痛苦至极。就像是被某个人强行按到床上一样难受。

至于说CUDA还有CUDNN的装法,这个还请自行百度、CSDN或者阅读NVIDIA和TensorFlow的官方文档,每一个组件的版本必须都要对应上,这就非常非常地难受,就算是全部都按照文档进行操作,也未必能跑起来,跟你的显卡驱动什么的都有关系,我上次就是因为驱动版本太高了,不行,降了驱动版本才运行起来的。每次看到报错我的心情能用下图进行解释:

扯远了,总之,跟NVIDIA扯上关系就会变得不幸,无论是安装过程,使用体验还是钱包。回归正题。
需要使用到的库文件列表已经制作到 requirement.txt 中,方便在换电脑之后进行安装。
这里需要强调一下,这个文件中的 TensorFlow 版本和 Panda 以及 Numpy 版本在树莓派上存在冲突,安装不上,需要手动先安装 TensorFlow ,这个时候会对另外两个库进行降级,等安装完之后再手动将那两个库升级回去,否则 Keras 就用不了。实测也没发生什么错误。
安装库文件的时候,在所创建的conda环境下,可以通过如下的命令进行安装
pip install -r requirement.txt

安装完成之后会出现如上的提示。这个时候使用
pip list
检查一下库文件是否都安装成功。
如果requirement.txt丢失,可以通过下面的代码重建requirement.txt文件
absl-py==0.11.0
aliyun-iot-linkkit==1.2.3
astunparse==1.6.3
cachetools==4.1.1
certifi==2021.10.8
charset-normalizer==2.0.4
crcmod==1.7
cycler==0.10.0
docopt==0.6.2
gast==0.3.3
google-auth==1.23.0
google-auth-oauthlib==0.4.2
google-pasta==0.2.0
grpcio==1.34.0
h2==2.6.2
h5py==2.10.0
hpack==3.0.0
hyper==0.7.0
hyperframe==3.2.0
idna==3.2
imutils==0.5.4
keras==2.7.0
Keras-Preprocessing==1.1.2
kiwisolver==1.3.2
labelImg==1.8.6
lxml==4.6.4
Markdown==3.3.3
matplotlib==3.4.3
numpy==1.18.5
oauthlib==3.1.0
opencv-python==4.5.3.56
opt-einsum==3.3.0
paho-mqtt==1.5.1
pandas==1.3.2
Pillow==8.3.2
protobuf==3.14.0
pyasn1==0.4.8
pyasn1-modules==0.2.8
pyparsing==2.4.7
PyQt5==5.15.4
PyQt5-Qt5==5.15.2
PyQt5-sip==12.9.0
python-dateutil==2.8.2
pytz==2021.1
requests==2.26.0
requests-oauthlib==1.3.0
rsa==4.6
schedule==1.1.0
scipy==1.7.1
seaborn==0.11.2
six==1.16.0
stomp.py==7.0.0
tensorboard==2.4.0
tensorboard-plugin-wit==1.7.0
tensorflow==2.3.1
tensorflow-estimator==2.3.0
termcolor==1.1.0
tqdm==4.62.2
urllib3==1.26.6
Werkzeug==2.0.1
wrapt==1.12.1
Chapter 3 程序解释
完整的目录结构:
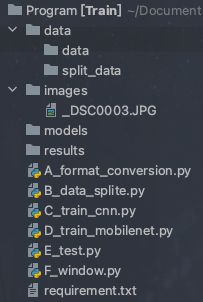
我在每一部分结尾都会附上完整的程序,当程序附件丢失或收到时只有本文档的时候,可以通过本文档重建项目。并顺利跑通。
其中images文件夹内的_DSC0003.JPG照片,可以自行替换成相同命名的图片。
Part 1 A_format_conversion.py
首先我们应该了解到,图片在进行解码的时候,有 progressive 和 baseline 两种格式,而本程序使用的 TensorFlow 并不认识 progressive 格式的照片,因此会导致程序在运行时出现如下报错:
Invalid *** data or crop window, data size ***
因此需要将图片全部转换为 baseline 格式。这里推荐Detect progressive JPEGs 这个网站,拖动图片到虚线位置即可识别。
之后,需要将图片格式进行转换,利用OpenCV即可完成这样的操作:
img1 = cv2.imread(cls) # 读取图像
cv2.imwrite(cls, img1) # 保存图像
之后便不会再次遇到这样的问题。
下面这段程序是用于获取data/data目录下的所有图片的路径。
for root, dirs, files in os.walk(r"data/data/"):
for file in files:
# 获取文件所属目录
print(root)
# 获取文件路径
print(os.path.join(root, file))
classes.append(os.path.join(root, file))
将所有的路径写入到一个classes的数组里。完整程序:
# skimage.io.imread()
# skimage.color.rgb2gray()
import os
import cv2
classes=[]
for root, dirs, files in os.walk(r"data/data/"):
for file in files:
# 获取文件所属目录
print(root)
# 获取文件路径
print(os.path.join(root, file))
classes.append(os.path.join(root, file))
print(classes)
data = []
for cls in classes:
try:
print(cls)
img1 = cv2.imread(cls) # 读取图像
cv2.imwrite(cls, img1) # 保存图像
except:
print("wrong")
Part 2 B_data_splite.py
通过这个程序,可以将我们准备的数据集划分为==训练集、验证集和测试集。==
本程序的数据集的源数据应当分类存放于data/data目录下。什么叫做分好类呢,就是像下图这样:
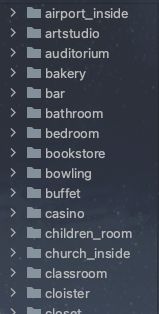
这是一个室内场景的数据集,分为了机场内部,艺术工作室等等场景,按照分类分好之后放入到上述的路径之下即可
程序部分,首先我们看到的是函数data_set_split
'''
读取源数据文件夹,生成划分好的文件夹,分为trian、val、test三个文件夹进行
:param src_data_folder: 源文件夹
:param target_data_folder: 目标文件夹
:param train_scale: 训练集比例
:param val_scale: 验证集比例
:param test_scale: 测试集比例
:return:
'''
函数有五个参数,其中我们只需要设定后三个参数:train_scale, val_scale, test_scale 分别对应着训练集比例,验证集比例和测试集比例。我常用的比例有如下几种:
| 比例设置 | 照片数量 |
|---|---|
| train_scale=0.3, val_scale=0.7, test_scale=0.0 | 大于7000张 |
| train_scale=0.4, val_scale=0.6, test_scale=0.0 | 1000张到7000张之间 |
| train_scale=0.5, val_scale=0.5, test_scale=0.0 | 500张到1000张之间 |
| train_scale=0.7, val_scale=0.3, test_scale=0.0 | 500张以下 |
这些都是我实际测试过效果比较好的几种比例设置。完整程序
# -*- coding: utf-8 -*-
# @Time : 2021/6/17 20:29
# @Author : dejahu
# @Email : [email protected]
# @File : data_split.py
# @Software: PyCharm
# @Brief : 将数据集划分为训练集、验证集和测试集
import os
import random
from shutil import copy2
def data_set_split(src_data_folder, target_data_folder, train_scale=0.4, val_scale=0.6, test_scale=0.0):
'''
读取源数据文件夹,生成划分好的文件夹,分为trian、val、test三个文件夹进行
:param src_data_folder: 源文件夹
:param target_data_folder: 目标文件夹
:param train_scale: 训练集比例
:param val_scale: 验证集比例
:param test_scale: 测试集比例
:return:
'''
print("开始数据集划分")
class_names = os.listdir(src_data_folder)
# 在目标目录下创建文件夹
split_names = ['train', 'val', 'test']
for split_name in split_names:
split_path = os.path.join(target_data_folder, split_name)
if os.path.isdir(split_path):
pass
else:
os.mkdir(split_path)
# 然后在split_path的目录下创建类别文件夹
for class_name in class_names:
class_split_path = os.path.join(split_path, class_name)
if os.path.isdir(class_split_path):
pass
else:
os.mkdir(class_split_path)
# 按照比例划分数据集,并进行数据图片的复制
# 首先进行分类遍历
for class_name in class_names:
print(class_name)
try:
current_class_data_path = os.path.join(src_data_folder, class_name)
current_all_data = os.listdir(current_class_data_path)
current_data_length = len(current_all_data)
current_data_index_list = list(range(current_data_length))
random.shuffle(current_data_index_list)
train_folder = os.path.join(os.path.join(target_data_folder, 'train'), class_name)
val_folder = os.path.join(os.path.join(target_data_folder, 'val'), class_name)
test_folder = os.path.join(os.path.join(target_data_folder, 'test'), class_name)
train_stop_flag = current_data_length * train_scale
val_stop_flag = current_data_length * (train_scale + val_scale)
current_idx = 0
train_num = 0
val_num = 0
test_num = 0
for i in current_data_index_list:
src_img_path = os.path.join(current_class_data_path, current_all_data[i])
if current_idx <= train_stop_flag:
copy2(src_img_path, train_folder)
# print("{}复制到了{}".format(src_img_path, train_folder))
train_num = train_num + 1
elif (current_idx > train_stop_flag) and (current_idx <= val_stop_flag):
copy2(src_img_path, val_folder)
# print("{}复制到了{}".format(src_img_path, val_folder))
val_num = val_num + 1
else:
copy2(src_img_path, test_folder)
# print("{}复制到了{}".format(src_img_path, test_folder))
test_num = test_num + 1
current_idx = current_idx + 1
print("*********************************{}*************************************".format(class_name))
print(
"{}类按照{}:{}:{}的比例划分完成,一共{}张图片".format(class_name, train_scale, val_scale, test_scale, current_data_length))
print("训练集{}:{}张".format(train_folder, train_num))
print("验证集{}:{}张".format(val_folder, val_num))
print("测试集{}:{}张".format(test_folder, test_num))
except:
print("Wrong")
if __name__ == '__main__':
src_data_folder = "data/data" # todo 修改你的原始数据集路径
target_data_folder = "data/split_data/" # todo 修改为你要存放的路径
data_set_split(src_data_folder, target_data_folder)
Part 3 C_train_cnn.py
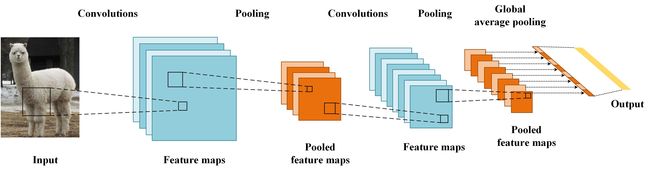
这个程序是cnn模型训练代码,训练的代码会保存在models目录下,折线图会保存在results目录下。
程序里的其他参数不需要再次设置,只需要注意这个地方:
def train(epochs):
# 开始训练,记录开始时间
begin_time = time()
# todo 加载数据集, 修改为你的数据集的路径
train_ds, val_ds, class_names = data_load("data/split_data/train",
"data/split_data/val", 224, 224, 7)
print(class_names)
# 加载模型
model = model_load(class_num=len(class_names))
# 指明训练的轮数epoch,开始训练
history = model.fit(train_ds, validation_data=val_ds, epochs=epochs)
# todo 保存模型, 修改为你要保存的模型的名称
model.save("models/cnn_fv.h5")
# 记录结束时间
end_time = time()
run_time = end_time - begin_time
print('该循环程序运行时间:', run_time, "s") # 该循环程序运行时间: 1.4201874732
# 绘制模型训练过程图
show_loss_acc(history)
其中的结尾数字“7”,这个需要根据你的显卡显存或者电脑内存来进行设置。
train_ds, val_ds, class_names = data_load("data/split_data/train","data/split_data/val", 224, 224, 7)
比方说6GB VRAM或16GB RAM就可以设置到"7",而16GB VRAM或32GB RAM就可以狂放到“20”,更大的24GB VRAM或64GB RAM就可以设置到“32”甚至”128“。这个就需要根据实际情况来进行调整了。我只尝试过前两种,也就是”7“和”20“,其他的没尝试过。
model.save("models/cnn_fv.h5")
这里的cnn_fv.h5就是模型名称。
train(epochs=10)
其中的epochs代表着要训练多少次,这里给一个参考:1.2万张的非常复杂的数据集需要至少1200次以上才能将准确率提高到勉强可用的水平,推荐在8000次或者更多。6千张的数字数据集需要至少800次才能达到可用的水平。
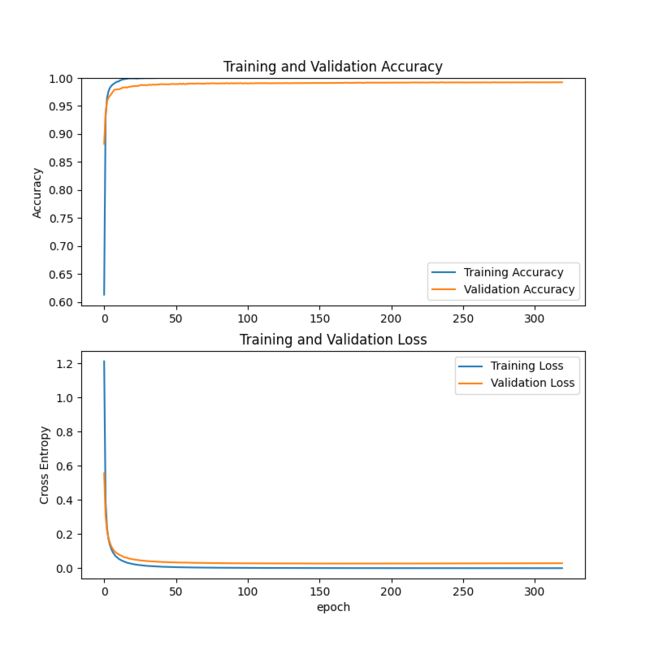
具体需要训练多少次这个得要根据数据集的复杂程度来进行设定。不能一概而论。训练完成之后,训练折线图会保存在results里面。类似如下这种图片:
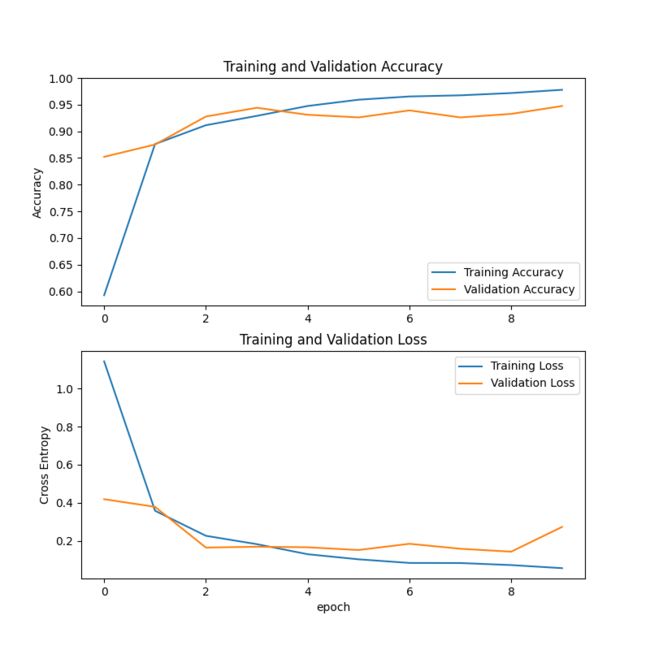
完整程序
# -*- coding: utf-8 -*-
# @Time : 2021/6/17 20:29
# @Author : dejahu
# @Email : [email protected]
# @File : train_cnn.py
# @Software: PyCharm
# @Brief : cnn模型训练代码,训练的代码会保存在models目录下,折线图会保存在results目录下
import tensorflow as tf
import matplotlib.pyplot as plt
from time import *
# 数据集加载函数,指明数据集的位置并统一处理为imgheight*imgwidth的大小,同时设置batch
def data_load(data_dir, test_data_dir, img_height, img_width, batch_size):
# 加载训练集
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
label_mode='categorical',
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
# 加载测试集
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
test_data_dir,
label_mode='categorical',
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
# 返回处理之后的训练集、验证集和类名
return train_ds, val_ds, class_names
# 构建CNN模型
def model_load(IMG_SHAPE=(224, 224, 3), class_num=12):
# 搭建模型
model = tf.keras.models.Sequential([
# 对模型做归一化的处理,将0-255之间的数字统一处理到0到1之间
tf.keras.layers.experimental.preprocessing.Rescaling(1. / 255, input_shape=IMG_SHAPE),
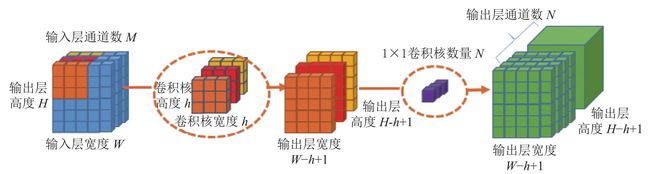
# 卷积层,该卷积层的输出为32个通道,卷积核的大小是3*3,激活函数为relu
tf.keras.layers.Conv2D(32, (3, 3), activation='relu'),
# 添加池化层,池化的kernel大小是2*2
tf.keras.layers.MaxPooling2D(2, 2),
# Add another convolution
# 卷积层,输出为64个通道,卷积核大小为3*3,激活函数为relu
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
# 池化层,最大池化,对2*2的区域进行池化操作
tf.keras.layers.MaxPooling2D(2, 2),
# 将二维的输出转化为一维
tf.keras.layers.Flatten(),
# The same 128 dense layers, and 10 output layers as in the pre-convolution example:
tf.keras.layers.Dense(128, activation='relu'),
# 通过softmax函数将模型输出为类名长度的神经元上,激活函数采用softmax对应概率值
tf.keras.layers.Dense(class_num, activation='softmax')
])
# 输出模型信息
model.summary()
# 指明模型的训练参数,优化器为sgd优化器,损失函数为交叉熵损失函数
model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy'])
# 返回模型
return model
# 展示训练过程的曲线
def show_loss_acc(history):
# 从history中提取模型训练集和验证集准确率信息和误差信息
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
# 按照上下结构将图画输出
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()), 1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.savefig('results/results_cnn.png', dpi=100)
def train(epochs):
# 开始训练,记录开始时间
begin_time = time()
# todo 加载数据集, 修改为你的数据集的路径
train_ds, val_ds, class_names = data_load("data/split_data/train",
"data/split_data/val", 224, 224, 7)
print(class_names)
# 加载模型
model = model_load(class_num=len(class_names))
# 指明训练的轮数epoch,开始训练
history = model.fit(train_ds, validation_data=val_ds, epochs=epochs)
# todo 保存模型, 修改为你要保存的模型的名称
model.save("models/cnn_fv.h5")
# 记录结束时间
end_time = time()
run_time = end_time - begin_time
print('该循环程序运行时间:', run_time, "s") # 该循环程序运行时间: 1.4201874732
# 绘制模型训练过程图
show_loss_acc(history)
if __name__ == '__main__':
train(epochs=10)
Part 4 D_train_mobilenet.py
程序里的其他参数不需要再次设置,只需要注意这个地方:
def train(epochs):
# 开始训练,记录开始时间
begin_time = time()
# todo 加载数据集, 修改为你的数据集的路径
train_ds, val_ds, class_names = data_load("data/split_data/train",
"data/split_data/val", 224, 224, 7)
print(class_names)
# 加载模型
model = model_load(class_num=len(class_names))
# 指明训练的轮数epoch,开始训练
history = model.fit(train_ds, validation_data=val_ds, epochs=epochs)
# todo 保存模型, 修改为你要保存的模型的名称
model.save("models/mobilenet_fv.h5")
# 记录结束时间
end_time = time()
run_time = end_time - begin_time
print('该循环程序运行时间:', run_time, "s") # 该循环程序运行时间: 1.4201874732
# 绘制模型训练过程图
show_loss_acc(history)
其中的结尾数字“16”,这个需要根据你的显卡显存或者电脑内存来进行设置。
train_ds, val_ds, class_names = data_load("data/split_data/train","data/split_data/val", 224, 224, 7)
比方说6GB VRAM或16GB RAM就可以设置到"7",而16GB VRAM或32GB RAM就可以狂放到“20”,更大的24GB VRAM或64GB RAM就可以设置到“32”甚至”128“。这个就需要根据实际情况来进行调整了。我只尝试过前两种,也就是”7“和”20“,其他的没尝试过。
model.save("models/mobilenet_fv.h5")
这里的mobilenet_fv.h5就是模型名称。
train(epochs=10)
其中的epochs代表着要训练多少次,这里给一个参考:1.2万张的非常复杂的数据集需要至少1200次以上才能将准确率提高到勉强可用的水平,推荐在8000次或者更多。6千张的数字数据集需要至少800次才能达到可用的水平。
具体需要训练多少次这个得要根据数据集的复杂程度来进行设定。不能一概而论。
具体需要训练多少次这个得要根据数据集的复杂程度来进行设定。不能一概而论。训练完成之后,训练折线图会保存在results里面。类似如下这种图片:
完整代码
# -*- coding: utf-8 -*-
# @Time : 2021/6/17 20:29
# @Author : dejahu
# @Email : [email protected]
# @File : train_mobilenet.py
# @Software: PyCharm
# @Brief : mobilenet模型训练代码,训练的模型会保存在models目录下,折线图会保存在results目录下
import tensorflow as tf
import matplotlib.pyplot as plt
from time import *
# 数据集加载函数,指明数据集的位置并统一处理为imgheight*imgwidth的大小,同时设置batch
def data_load(data_dir, test_data_dir, img_height, img_width, batch_size):
# 加载训练集
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
label_mode='categorical',
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
# 加载测试集
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
test_data_dir,
label_mode='categorical',
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
# 返回处理之后的训练集、验证集和类名
return train_ds, val_ds, class_names
# 构建mobilenet模型
# 模型加载,指定图片处理的大小和是否进行迁移学习
def model_load(IMG_SHAPE=(224, 224, 3), class_num=12):
# 微调的过程中不需要进行归一化的处理
# 加载预训练的mobilenet模型
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
# 将模型的主干参数进行冻结
base_model.trainable = False
model = tf.keras.models.Sequential([
# 进行归一化的处理
tf.keras.layers.experimental.preprocessing.Rescaling(1. / 127.5, offset=-1, input_shape=IMG_SHAPE),
# 设置主干模型
base_model,
# 对主干模型的输出进行全局平均池化
tf.keras.layers.GlobalAveragePooling2D(),
# 通过全连接层映射到最后的分类数目上
tf.keras.layers.Dense(class_num, activation='softmax')
])
model.summary()
# 模型训练的优化器为adam优化器,模型的损失函数为交叉熵损失函数
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
return model
# 展示训练过程的曲线
def show_loss_acc(history):
# 从history中提取模型训练集和验证集准确率信息和误差信息
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
# 按照上下结构将图画输出
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()), 1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.savefig('results/results_mobilenet.png', dpi=100)
def train(epochs):
# 开始训练,记录开始时间
begin_time = time()
# todo 加载数据集, 修改为你的数据集的路径
train_ds, val_ds, class_names = data_load("data/split_data/train",
"data/split_data/val", 224, 224, 7)
print(class_names)
# 加载模型
model = model_load(class_num=len(class_names))
# 指明训练的轮数epoch,开始训练
history = model.fit(train_ds, validation_data=val_ds, epochs=epochs)
# todo 保存模型, 修改为你要保存的模型的名称
model.save("models/mobilenet_fv.h5")
# 记录结束时间
end_time = time()
run_time = end_time - begin_time
print('该循环程序运行时间:', run_time, "s") # 该循环程序运行时间: 1.4201874732
# 绘制模型训练过程图
show_loss_acc(history)
if __name__ == '__main__':
train(epochs=10)
Part 5 E_test.py
在这一部分,需要注意的参数只有这一个
train_ds, val_ds, class_names = data_load("data/split_data/train","data/split_data/val", 224, 224, 7)
具体的操作参见上两部分的解释,这个语句分别在def test_cnn()和def test_mobilenet()函数当中。
我们根据自己的模型类型来选择测试程序。把不用的部分前面敲上#就可以了。
if __name__ == '__main__':
test_mobilenet() #测试mobilenet模型
test_cnn() #测试cnn模型
程序会将一个热力图保存在results里面。类似下面这样的图片:

完整代码
# -*- coding: utf-8 -*-
# @Time : 2021/6/17 20:29
# @Author : dejahu
# @Email : [email protected]
# @File : test_model.py
# @Software: PyCharm
# @Brief : 模型测试代码,测试会生成热力图,热力图会保存在results目录下
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
# 数据加载,分别从训练的数据集的文件夹和测试的文件夹中加载训练集和验证集
def data_load(data_dir, test_data_dir, img_height, img_width, batch_size):
# 加载训练集
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
label_mode='categorical',
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
# 加载测试集
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
test_data_dir,
label_mode='categorical',
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
# 返回处理之后的训练集、验证集和类名
return train_ds, val_ds, class_names
# 测试mobilenet准确率
def test_mobilenet():
# todo 加载数据, 修改为你自己的数据集的路径
train_ds, test_ds, class_names = data_load("data/split_data/train",
"data/split_data/val", 224, 224, 16)
# todo 加载模型,修改为你的模型名称
model = tf.keras.models.load_model("models/mobilenet_fv_num.h5")
# model.summary()
# 测试
loss, accuracy = model.evaluate(test_ds)
# 输出结果
print('Mobilenet test accuracy :', accuracy)
test_real_labels = []
test_pre_labels = []
for test_batch_images, test_batch_labels in test_ds:
test_batch_labels = test_batch_labels.numpy()
test_batch_pres = model.predict(test_batch_images)
# print(test_batch_pres)
test_batch_labels_max = np.argmax(test_batch_labels, axis=1)
test_batch_pres_max = np.argmax(test_batch_pres, axis=1)
# print(test_batch_labels_max)
# print(test_batch_pres_max)
# 将推理对应的标签取出
for i in test_batch_labels_max:
test_real_labels.append(i)
for i in test_batch_pres_max:
test_pre_labels.append(i)
# break
# print(test_real_labels)
# print(test_pre_labels)
class_names_length = len(class_names)
heat_maps = np.zeros((class_names_length, class_names_length))
for test_real_label, test_pre_label in zip(test_real_labels, test_pre_labels):
heat_maps[test_real_label][test_pre_label] = heat_maps[test_real_label][test_pre_label] + 1
print(heat_maps)
heat_maps_sum = np.sum(heat_maps, axis=1).reshape(-1, 1)
# print(heat_maps_sum)
print()
heat_maps_float = heat_maps / heat_maps_sum
print(heat_maps_float)
# title, x_labels, y_labels, harvest
show_heatmaps(title="heatmap", x_labels=class_names, y_labels=class_names, harvest=heat_maps_float,
save_name="results/heatmap_mobilenet.png")
# 测试cnn模型准确率
def test_cnn():
# todo 加载数据, 修改为你自己的数据集的路径
train_ds, test_ds, class_names = data_load("data/split_data/train",
"data/split_data/val", 224, 224, 16)
# todo 加载模型,修改为你的模型名称
model = tf.keras.models.load_model("models/cnn_fv.h5")
# model.summary()
# 测试
loss, accuracy = model.evaluate(test_ds)
# 输出结果
print('CNN test accuracy :', accuracy)
# 对模型分开进行推理
test_real_labels = []
test_pre_labels = []
for test_batch_images, test_batch_labels in test_ds:
test_batch_labels = test_batch_labels.numpy()
test_batch_pres = model.predict(test_batch_images)
# print(test_batch_pres)
test_batch_labels_max = np.argmax(test_batch_labels, axis=1)
test_batch_pres_max = np.argmax(test_batch_pres, axis=1)
# print(test_batch_labels_max)
# print(test_batch_pres_max)
# 将推理对应的标签取出
for i in test_batch_labels_max:
test_real_labels.append(i)
for i in test_batch_pres_max:
test_pre_labels.append(i)
# break
# print(test_real_labels)
# print(test_pre_labels)
class_names_length = len(class_names)
heat_maps = np.zeros((class_names_length, class_names_length))
for test_real_label, test_pre_label in zip(test_real_labels, test_pre_labels):
heat_maps[test_real_label][test_pre_label] = heat_maps[test_real_label][test_pre_label] + 1
print(heat_maps)
heat_maps_sum = np.sum(heat_maps, axis=1).reshape(-1, 1)
# print(heat_maps_sum)
print()
heat_maps_float = heat_maps / heat_maps_sum
print(heat_maps_float)
# title, x_labels, y_labels, harvest
show_heatmaps(title="heatmap", x_labels=class_names, y_labels=class_names, harvest=heat_maps_float,
save_name="results/heatmap_cnn.png")
def show_heatmaps(title, x_labels, y_labels, harvest, save_name):
# 这里是创建一个画布
fig, ax = plt.subplots(figsize = (50,50))
# cmap https://blog.csdn.net/ztf312/article/details/102474190
im = ax.imshow(harvest, cmap="OrRd")
# 这里是修改标签
# We want to show all ticks...
ax.set_xticks(np.arange(len(y_labels)))
ax.set_yticks(np.arange(len(x_labels)))
# ... and label them with the respective list entries
ax.set_xticklabels(y_labels)
ax.set_yticklabels(x_labels)
# 因为x轴的标签太长了,需要旋转一下,更加好看
# Rotate the tick labels and set their alignment.
plt.setp(ax.get_xticklabels(), rotation=90, ha="right",
rotation_mode="anchor")
# 添加每个热力块的具体数值
# Loop over data dimensions and create text annotations.
for i in range(len(x_labels)):
for j in range(len(y_labels)):
text = ax.text(j, i, round(harvest[i, j], 2),
ha="center", va="center", color="black")
ax.set_xlabel("Predict label")
ax.set_ylabel("Actual label")
ax.set_title(title)
fig.tight_layout()
plt.colorbar(im)
plt.savefig(save_name, dpi=200)
# plt.show()
if __name__ == '__main__':
test_mobilenet()
test_cnn()
Part 6 F_windows.py
在第29行附近,有这样一段程序:
self.class_names = ['.DS_Store','1','2','3','4','5','6','7','8']
这个数组,需要根据你的数据集来进行修改,这个数组在模型训练的开始会输出,你需要提前复制保存下来。
self.model = tf.keras.models.load_model("models/mobilenet_fv.h5")
通过这个可以选择要使用的数据模型。
完整代码
# -*- coding: utf-8 -*-
# @Time : 2021/6/17 20:29
# @Author : dejahu
# @Email : [email protected]
# @File : window.py
# @Software: PyCharm
# @Brief : 图形化界面
import tensorflow as tf
from PyQt5.QtGui import *
from PyQt5.QtCore import *
from PyQt5.QtWidgets import *
import sys
import cv2
from PIL import Image
import numpy as np
import shutil
class MainWindow(QTabWidget):
# 初始化
def __init__(self):
super().__init__()
self.setWindowIcon(QIcon('images/_DSC0003.JPG'))
self.setWindowTitle('学习系统') # todo 修改系统名称
# 模型初始化
self.model = tf.keras.models.load_model("models/mobilenet_fv.h5") # todo 修改模型名称
self.to_predict_name = "images/_DSC0003.JPG" # todo 修改初始图片,这个图片要放在images目录下
self.class_names = ['.DS_Store','1','2','3','4','5','6','7','8'] # todo 修改类名,这个数组在模型训练的开始会输出
self.resize(900, 700)
self.initUI()
# 界面初始化,设置界面布局
def initUI(self):
main_widget = QWidget()
main_layout = QHBoxLayout()
font = QFont('楷体', 15)
# 主页面,设置组件并在组件放在布局上
left_widget = QWidget()
left_layout = QVBoxLayout()
img_title = QLabel("样本")
img_title.setFont(font)
img_title.setAlignment(Qt.AlignCenter)
self.img_label = QLabel()
img_init = cv2.imread(self.to_predict_name)
h, w, c = img_init.shape
scale = 400 / h
img_show = cv2.resize(img_init, (0, 0), fx=scale, fy=scale)
cv2.imwrite("images/show.png", img_show)
img_init = cv2.resize(img_init, (224, 224))
cv2.imwrite('images/target.png', img_init)
self.img_label.setPixmap(QPixmap("images/show.png"))
left_layout.addWidget(img_title)
left_layout.addWidget(self.img_label, 1, Qt.AlignCenter)
left_widget.setLayout(left_layout)
right_widget = QWidget()
right_layout = QVBoxLayout()
btn_change = QPushButton(" 上传图片 ")
btn_change.clicked.connect(self.change_img)
btn_change.setFont(font)
btn_predict = QPushButton(" 开始识别 ")
btn_predict.setFont(font)
btn_predict.clicked.connect(self.predict_img)
label_result = QLabel(' 果蔬名称 ')
self.result = QLabel("等待识别")
label_result.setFont(QFont('楷体', 16))
self.result.setFont(QFont('楷体', 24))
right_layout.addStretch()
right_layout.addWidget(label_result, 0, Qt.AlignCenter)
right_layout.addStretch()
right_layout.addWidget(self.result, 0, Qt.AlignCenter)
right_layout.addStretch()
right_layout.addStretch()
right_layout.addWidget(btn_change)
right_layout.addWidget(btn_predict)
right_layout.addStretch()
right_widget.setLayout(right_layout)
main_layout.addWidget(left_widget)
main_layout.addWidget(right_widget)
main_widget.setLayout(main_layout)
# 关于页面,设置组件并把组件放在布局上
about_widget = QWidget()
about_layout = QVBoxLayout()
about_title = QLabel('欢迎使用果蔬识别系统') # todo 修改欢迎词语
about_title.setFont(QFont('楷体', 18))
about_title.setAlignment(Qt.AlignCenter)
about_img = QLabel()
about_img.setPixmap(QPixmap('images/bj.jpg'))
about_img.setAlignment(Qt.AlignCenter)
label_super = QLabel("作者:dejahu") # todo 更换作者信息
label_super.setFont(QFont('楷体', 12))
# label_super.setOpenExternalLinks(True)
label_super.setAlignment(Qt.AlignRight)
about_layout.addWidget(about_title)
about_layout.addStretch()
about_layout.addWidget(about_img)
about_layout.addStretch()
about_layout.addWidget(label_super)
about_widget.setLayout(about_layout)
# 添加注释
self.addTab(main_widget, '主页')
self.addTab(about_widget, '关于')
self.setTabIcon(0, QIcon('images/主页面.png'))
self.setTabIcon(1, QIcon('images/关于.png'))
# 上传并显示图片
def change_img(self):
openfile_name = QFileDialog.getOpenFileName(self, 'chose files', '',
'Image files(*.jpg *.png *jpeg)') # 打开文件选择框选择文件
img_name = openfile_name[0] # 获取图片名称
if img_name == '':
pass
else:
target_image_name = "images/tmp_up." + img_name.split(".")[-1] # 将图片移动到当前目录
shutil.copy(img_name, target_image_name)
self.to_predict_name = target_image_name
img_init = cv2.imread(self.to_predict_name) # 打开图片
h, w, c = img_init.shape
scale = 400 / h
img_show = cv2.resize(img_init, (0, 0), fx=scale, fy=scale) # 将图片的大小统一调整到400的高,方便界面显示
cv2.imwrite("images/shoimgw.png", img_show)
img_init = cv2.resize(img_init, (224, 224)) # 将图片大小调整到224*224用于模型推理
cv2.imwrite('images/target.png', img_init)
self.img_label.setPixmap(QPixmap("images/show.png"))
self.result.setText("等待识别")
# 预测图片
def predict_img(self):
img = Image.open('images/target.png') # 读取图片
img = np.asarray(img) # 将图片转化为numpy的数组
outputs = self.model.predict(img.reshape(1, 224, 224, 3)) # 将图片输入模型得到结果
result_index = int(np.argmax(outputs))
result = self.class_names[result_index] # 获得对应的水果名称
self.result.setText(result) # 在界面上做显示
# 界面关闭事件,询问用户是否关闭
def closeEvent(self, event):
reply = QMessageBox.question(self,
'退出',
"是否要退出程序?",
QMessageBox.Yes | QMessageBox.No,
QMessageBox.No)
if reply == QMessageBox.Yes:
self.close()
event.accept()
else:
event.ignore()
if __name__ == "__main__":
app = QApplication(sys.argv)
x = MainWindow()
x.show()
sys.exit(app.exec_())
Chapter 4 小结
这个文档仅仅只是记录了如何通过这套程序来训练我们自己的数据集。至于原理以及如何实现的具体细节我也没有明白太多,也只是一个会用的阶段,还不能自己写出来程序。
开头提到的UP主,他自己也在B站上上传了不少的教程视频,大家多去学习。