机器学习实验:主成分分析法PCA实现手写数字数据集的降维
实现PCA算法实例2,要求:
1、实现手写数字数据集的降维;
2、比较两个模型(64维和10维)的准确率;
3、对两个模型分别进行10次10折交叉验证,绘制评分对比曲线。

代码实现:
- 导入相关包
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
- 导入数据集
# 导入数据集
digits = load_digits()
train = digits.data
target = digits.target
x_train,x_test,y_train,y_true = train_test_split(train,target,test_size=0.2,random_state=33)
- 对数据进行处理,去均值和方差归一化。
StandardScale的用法可以看这篇博客:sklearn中StandardScaler()
# 去均值和方差归一化
ss = StandardScaler()
x_train = ss.fit_transform(x_train)
x_test = ss.transform(x_test)
- 对未降维的数据进行分类,输出各项指标
#对未降维的数据进行分类
svc = SVC(kernel='rbf') #使用支持向量机进行分类,核函数采用径向基核函数
svc.fit(x_train,y_train)
y_predict = svc.predict(x_test)
print("The Accuraracy of SVC is:",svc.score(x_test,y_true))
print("classification report of SVC\n",classification_report(y_true,y_predict,target_names=digits.target_names.astype(str)))
输出结果:
The Accuraracy of SVC is: 0.9888888888888889
classification report of SVC
precision recall f1-score support
0 1.00 1.00 1.00 29
1 0.98 1.00 0.99 46
2 1.00 0.97 0.99 37
3 1.00 1.00 1.00 39
4 0.96 1.00 0.98 25
5 0.97 0.97 0.97 37
6 0.98 1.00 0.99 41
7 1.00 1.00 1.00 29
8 1.00 0.98 0.99 44
9 1.00 0.97 0.98 33
accuracy 0.99 360
macro avg 0.99 0.99 0.99 360
weighted avg 0.99 0.99 0.99 360
- 进行十折交叉验证
#十折交叉验证
epochs = 10
x = [i for i in range(10)]
scores = []
cv = KFold(n_splits=10,shuffle=True) #定义10折交叉验证
for i in range(epochs):
score = cross_val_score(svc, train, target, cv=cv).mean() #降维前
scores.append(score)
print(scores)
plt.plot(x, scores, linewidth=1, color="orange", marker="o",label="Mean value")
plt.legend(["Mean value"],loc="upper left")#设置线条标识
plt.show()
输出结果:
[0.9883147113594042, 0.987749844816884, 0.9877591558038485, 0.9877560521415271, 0.9883116076970826, 0.9888795779019244, 0.9866511483550591, 0.9888609559279951, 0.9888640595903165, 0.9888764742396028]
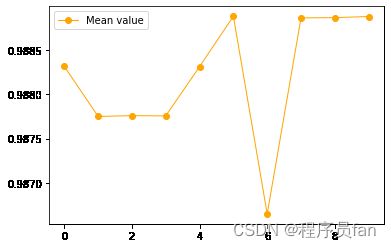
这里要说一下,为什么不直接定义cv=10,而实例一个KFold类:
- 因为cross_val_score中默认的当CV是整数时,cross_val_score默认使用KFold或StratifiedKFold策略,后者会在估计器派生ClassifierMixin时使用。
- 而cross_val_score默认使用的KFold,随机数是固定的,且每次不重新打乱数据集,这就会导致每次交叉验证的结果都是同一个值,输出的图像也是一条直线
- 所以我们可以通过传入一个自己定义的KFold交叉验证迭代器来保证每次数据集都是打乱的,从而保证每次交叉验证的结果都不同
- 用PCA降至十维后,再对数据进行分类
#PCA降维,并对数据进行分类
pca = PCA(n_components=10,whiten=True)
pca.fit(x_train,y_train)
x_train_pca = pca.transform(x_train)
x_test_pca = pca.transform(x_test)
svc = SVC(kernel='rbf')
svc.fit(x_train_pca,y_train)
y_pre_svc = svc.predict(x_test_pca)
print("The Accuraracy of PCA_SVC is:",svc.score(x_test_pca,y_true))
print("classification report of PCA_SVC\n",classification_report(y_true,y_pre_svc,target_names=digits.target_names.astype(str)))
输出结果:
The Accuraracy of PCA_SVC is: 0.95
classification report of PCA_SVC
precision recall f1-score support
0 1.00 1.00 1.00 29
1 0.98 0.98 0.98 46
2 1.00 1.00 1.00 37
3 0.91 0.82 0.86 39
4 1.00 0.96 0.98 25
5 0.92 0.95 0.93 37
6 0.98 1.00 0.99 41
7 0.97 1.00 0.98 29
8 0.89 0.91 0.90 44
9 0.88 0.91 0.90 33
accuracy 0.95 360
macro avg 0.95 0.95 0.95 360
weighted avg 0.95 0.95 0.95 360
- PCA降维后进行十折交叉验证
#十折交叉验证
epochs = 10
train_pca = pca.fit_transform(train) #用train来训练PCA模型,同时返回降维后的数据
x = [i for i in range(10)]
scores = []
cv = KFold(n_splits=10,shuffle=True) #定义10折交叉验证
for i in range(epochs):
score = cross_val_score(svc, train_pca, target, cv=cv).mean() #降维前
scores.append(score)
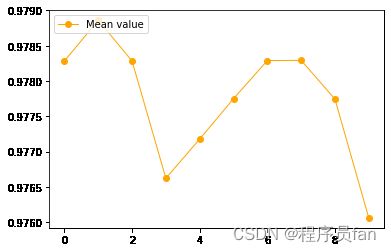
print(scores)
plt.plot(x, scores, linewidth=1, color="orange", marker="o",label="Mean value")
plt.legend(["Mean value"],loc="upper left")#设置线条标识
plt.show()
输出结果:
[0.9782836747361887, 0.9788609559279952, 0.9782836747361887, 0.9766232153941651, 0.9771787709497207, 0.977749844816884, 0.9782898820608317, 0.9782929857231533, 0.9777436374922408, 0.9760614525139666]
- 对数据集绘图
#绘图
samples = x_test[:100] #取前100个数据
y_pre = y_pre_svc[:100]
plt.figure(figsize=(12,38)) #确定图形的大小
for i in range(100):
plt.subplot(10,10,i+1)
plt.imshow(samples[i].reshape(8,8),cmap='gray')
title = str(y_pre[i])
plt.title(title)
plt.axis('off')
plt.show()
