【原创】强化学习笔记|从零开始学习PPO算法编程(pytorch版本)
从零开始学习PPO算法编程(pytorch版本)_melody_cjw的博客-CSDN博客_ppo算法 pytorch
从零开始学习PPO算法编程(pytorch版本)(二)_melody_cjw的博客-CSDN博客_ppo pytorch
从零开始学习PPO算法编程(pytorch版本)(三)_melody_cjw的博客-CSDN博客_ppo pytorch
上面3篇已经删除
PyTorch PPO 源码解读 (pytorch-a2c-ppo-acktr-gail)-老唐笔记
从零开始学习PPO算法编程(pytorch版本)(二)
从零开始学习PPO算法编程(pytorch版本)
PPO2代码 pytorch框架_方土成亮的博客-CSDN博客_ppo pytorch
https://blog.csdn.net/weixin_43145941/category_10613430.html?spm=1001.2014.3001.5482
PPO算法实战_johnjim0816的博客-CSDN博客_ppo算法
强化学习之 PPO 算法_红龙96的博客-CSDN博客_ppo算法
---------------
公式解释的好
【强化学习PPO算法】_喜欢库里的强化小白的博客-CSDN博客_ppo算法
输入输出
强化学习之图解PPO算法和TD3算法 - 知乎
评论区指出评价网格的根本功能
-
博主你好,在policy gradient中,损失函数loss = mean(cross_entropy(actions_prob, actions_label) * R),是计算的actions_prob和actions_label的交叉熵,但是在actor-critic中,计算actor的loss = mean(td_error * (log(第一步action对应的那个概率action_prob))),这里怎么没有交叉熵计算了呢,仅仅是log(action_prob)*td_error,,那这样的话在pg算法中能不能也只是log(action_prob)*R呢?
抱歉,我是初学者,不是很明白
-
博主你好,在第三步中,将s输入到网络中,得到的状态的v_值,这个状态的v_值通常怎么计算的?状态的v_值是一个平均值吗还是一系列数字
- 计算td_error = r + gamma * v_ - v,你说的是这个吧,v是critic网络的输出,就是一个确定的值,用于评价动作的好坏,至于怎么计算,其实就是输入state(针对于PPO等算法)或者输入state+action(DDPG等算法)到critic网络(BPNet或者CNN)中获得,通过不断更新优化网络参数来最终获得v值(作用:评价动作,相当于监督学习中的标签)
DQN——PPO流程总结_小葡萄co的博客-CSDN博客_ppo算法流程图
世界冠军带你从零实践强化学习心得(一)_东南坼的博客-CSDN博客
- 监督式学习:数据已有标记,运用已标记数据来做训练。
- 非监督式学习:数据没有标记,从中找出拥有相同特征的数据群。
- 强化式学习:可能手上没有任何数据,直接让模型执行,再将执行结果反馈回去做训练。
【科普】一文弄懂监督式学习、非监督式学习以及强化式学习_赵卓不凡的博客-CSDN博客_非监督学习应用
强化学习的分类和方法
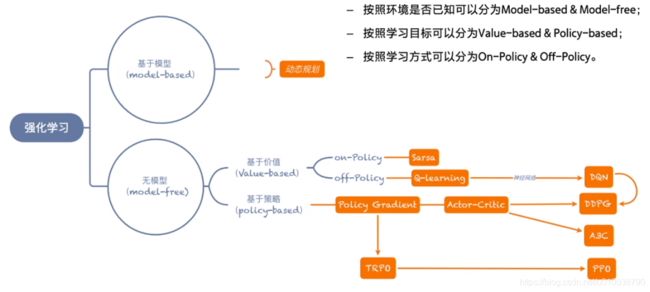
强化学习主要关注的是无模型的问题,在未知的环境中进行探索学习,在生活中有广泛的应用。

其探索方案有二:
基于价值的方法(Q表格)
给每个状态都赋予一个价值的概念,来代表这个状态是好还是坏,这是一个相对的概念,让智能体往价值最高的方向行进。基于价值是确定性的。
基于策略的方法(Policy)
制定出多个策略,策略里的每个动作都有一定的概率,并让每一条策略走到底,最后查看哪个策略是最优的。基于策略是随机性的。
Q学习(Q-learning)简单理解_qq_39429669的博客-CSDN博客_q学习
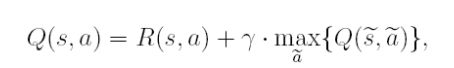
先a,再更新Q(通过sas~a~),一步一更新,但是a~下步不真的执行,具体说明如下
TD temporal difference时序差分,用下一步Q值更新上一步Q值,一步一更新,Sarsa和Qlearning都是时序差分
Sarsa和Qlearning
Sarsa全称是state-action-reward-state’-action’,目的是学习特定的state下,特定action的价值Q,最终建立和优化一个Q表格,以state为行,action为列,根据与环境交互得到的reward来更新Q表格,更新公式即为上面的迭代公式。Sarsa在训练中为了更好的探索环境,采用ε-greedy方式(如下图)来训练,有一定概率随机选择动作输出。
Q-learning也是采用Q表格的方式存储Q值,探索部分与Sarsa是一样的,采用ε-greedy方式增加探索。
Q-learning跟Sarsa不一样的地方是更新Q表格的方式,即learn()函数。
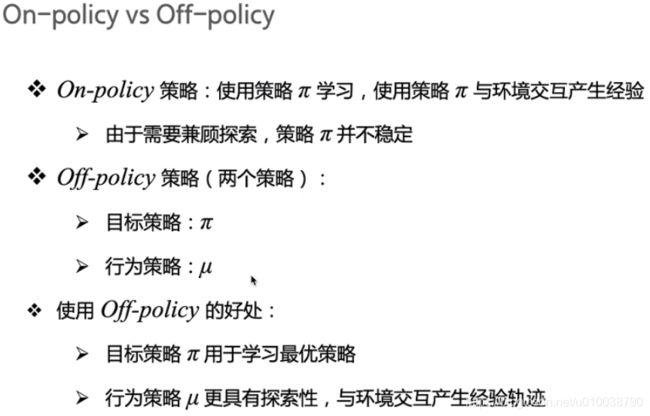
Sarsa是on-policy,先做出动作再learn,Q-learning是off-policy,learn时无需获取下一步动作
二者更新Q表格的方式分别为:

二者算法对比如下图所示,有三处不同点。

世界冠军带你从零实践强化学习心得(一)_东南坼的博客-CSDN博客
因为qlearning探索性,maxQ,而不是实际执行的Q,结果更激进
反之sarsa结果更保守 ,结果见上方链接,代码见上方链接
- 神经元:神经网络中每个节点称为神经元,由两部分组成:
- 加权和:将所有输入加权求和。
- 非线性变换(激活函数):加权和的结果经过一个非线性函数变换,让神经元计算具备非线性的能力。
- 多层连接: 大量这样的节点按照不同的层次排布,形成多层的结构连接起来,即称为神经网络。
- 前向计算: 从输入计算输出的过程,顺序从网络前至后。
![]()
由此可见,神经网络的本质是一个含有很多参数的“大公式”
DQN代码如下方链接,需要看
世界冠军带你从零实践强化学习心得 (二)_东南坼的博客-CSDN博客
(十) 深度学习笔记 | 关于优化器Adam_Viviana-0的博客-CSDN博客_adam优化器
Adam优化器简单理解和实现_pipony的博客-CSDN博客_adam优化器原理
DQN走几步,从缓存取出,批量更新
Q函数的输出维数是动作维数,用到哪个,再乘上对应的动作hot数组,这一点上方链接代码有体现,下方图片也有体现
强化学习--从DQN到PPO, 流程详解 - 知乎

【强化学习】Policy Gradient算法详解_shura_R的博客-CSDN博客
详解策略梯度算法_行者AI的博客-CSDN博客_策略梯度算法
策略梯度算法(Policy Gradient)逐行代码详解_小帅吖的博客-CSDN博客_策略梯度算法代码
强化学习--从DQN到PPO, 流程详解 - 知乎
DQN用目标Q和期望Q的差更新,Q由R产生
PG直接用R更新,1回合结束,再更新
下面这个链接讲PG更新更准确,几个例子动作都是离散的,PG也可已用于连续动作,但一般不用,效果不好
Lesson4-2-PolicyGradeint算法_哔哩哔哩_bilibili
什么是 Actor Critic (Reinforcement Learning 强化学习)_哔哩哔哩_bilibili
强化学习--从DQN到PPO, 流程详解 - 知乎
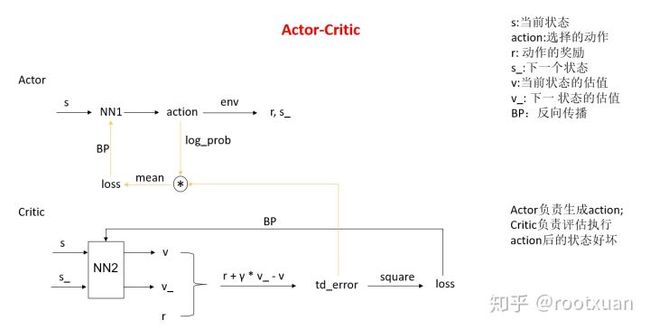
AC算法用critic网络输出的v代替PG算法中的R来更新,这样就可以单步更新,不用像PG算法一样,一回合才能更新(因为R不是r,R表示从此步开始到回合结束,所有r的加权和,所以只有回合结束才能计算)
Lesson5-1-连续动作空间与DDPG_哔哩哔哩_bilibili
Lesson5-2-DDPG代码与总结_哔哩哔哩_bilibili
PARL强化学习公开课学习笔记(五)连续动作空间求解RL(DDPG) - 知乎
DDPG 上面两个链接讲的非常好,也是AC的一种,可以单步更新,实际操作中,和DQN相同,每隔若干步更新一次 ,DDPG其实可以理解成为了DQN能在连续动作空间的一种改进
A3C和DPPO跳过,需要时可以看莫凡B站视频或百度
什么是张量(tensor)?&深度学习 - 知乎
强化学习中on policy和off policy的区别-深度理解_易烊千蝈的博客-CSDN博客_on policy和off policy的区别
A2C的Q网络更新loss,也就是说评价网络的更新loss是 ,现实Q和目标Q的差值,越来越小,这样我们的现实Q就可以越来越接近目标Q,也就是说我们的现实Q越来越能准确地评价每一个动作,因为目标Q就是可以准确地评价每一个动作,才称为目标Q.
但是目标Q确实不是已知的,如果目标Q已知,我们也不用不断更新Q网络,使得现实Q越来越接近目标Q,从而获得多次更新后的现实Q,从而拿多次更新后的现实Q当作目标Q,来评价每一个动作,目标Q永远不可知,只能不断逼近.
在更新过程中,我们每一次更新需要的目标用,现实Q和多个r(乘上不同的衰减系数,gama的1次方,2次方,3次方...n次方)组成的公式代替,当然可以这样代替,因为r就是我们定义的奖赏函数,不过是单次动作的奖赏函数,还要组成公式,使这个公式可以评价多次动作,从而可以顺利到达终点,从而可以当作目标Q完成每一次更新,从而获得多次更新后的现实Q,从而拿多次更新后的现实Q当作目标Q.
Q学习、Sarsa和DQN 的Q网络更新loss的设计思路和上边的一样
A2C的演员网络的更新loss是,动作概率×评价这次动作好坏指标,越来越大.
如果好,指标为正,总的方向(loss优化方向)乘积越来越大,动作概率越来越大方向优化
如果坏,指标为负,总的方向(loss优化方向)乘积越来越大,动作概率越来越小方向优化
动作的动作概率是已知的因为A2C的演员网络就是PG网络,输出的就是动作概率,但是评价这次动作好坏的评价指标怎么得到,有人使用Q的差,这一点说的不好,下一句精彩
loss的设计就是想明白,想让什么数小,想让什么数大
PG的loss就是想让计算的大R大,DDPG的A网络的loss就是想让此动作下Q越来越大,因为用的min优化器,所以公式Q加了一个负号
PPO的评价网络更新loss和A2C一样,演员网络更新loss和A2C类似
我的算法是PPO2,PPO2效果比PPO1更好
第一个链接和第二个链接基本一样,和我说的也基本一样,第三个链接和前两个好像不同
我的代码好像和这三个都有较大的不同,但是感觉解释的时候按官方解释最好
PPO2代码 pytorch框架_方土成亮的博客-CSDN博客_ppo pytorch
强化学习--从DQN到PPO, 流程详解 - 知乎
PPO算法实战_johnjim0816的博客-CSDN博客_ppo算法