PPO代码实现
PPO代码实现
文章目录
-
-
PPO代码实现 -
- 代码及解释
-
- 0.运行环境
- 1.包引入与参数设定
- 2.class PPO(object)
-
- 2.1.\__init__
-
- 创建state-value network
- 创建policy network
- \__init__
- 2.2.update_old_pi
- 2.3.store_transition
- 2.4.finish_path
- 2.5.choose_action
- 2.6.train_actor
- 2.7.train_critic
- 2.8.update
- 2.9.saveModel
- 2.10.loadModel
- 3.主程序
-
- 3.1.帧画面转化为gif函数
- 3.2.main函数
- 训练结果
-
- 2000次
- 遇到的坑
-
代码及解释
0.运行环境
| 设备/包 | 版本 |
|---|---|
| python | 3.7.11 |
| 显卡 | GTX 1050 |
| CUDA | 10.2 |
| cudnn | 7.6.5 |
| cudatoolkit | 10.0.130 |
| tensorflow-gpu | 2.2.0 |
| tensorlayer | 2.2.3 |
| tensorflow-probability | 0.9.0 |
1.包引入与参数设定
import argparse
import os
import time
import gym
import numpy as np
import tensorflow as tf
import tensorflow_probability as tfp
import tensorlayer as tl
from matplotlib import animation
import matplotlib.pyplot as plt
parser = argparse.ArgumentParser()
parser.add_argument('--train', dest='train', default=False)
parser.add_argument('--render', type=bool, default=False)
parser.add_argument('--save_gif', type=bool, default=True)
parser.add_argument('--train_episodes', type=int, default=2000)
parser.add_argument('--test_episodes', type=int, default=10)
# 训练时,一盘游戏最多进行max_steps步
parser.add_argument('--max_steps', type=int, default=200)
parser.add_argument('--batch_size', type=int, default=128)
# 价值折扣率
parser.add_argument('--gamma', type=float, default=0.95)
parser.add_argument('--actor_lr', type=float, default=0.0002)
parser.add_argument('--critic_lr', type=float, default=0.0004)
# epsilon是一个接近0的数,在本代码中为了避免数值错误,通常要给除数加一个epsilon
parser.add_argument('--eps', type=float, default=1e-8)
# 一次更新多少次actor和critic
parser.add_argument('--actor_update_steps', type=int, default=10)
parser.add_argument('--critic_update_steps', type=int, default=10)
args = parser.parse_args()
# 注意:这里是PPO1和PPO2的相关的参数。
METHODS = [
# dict(name='kl_pen', kl_target=0.01, lam=1.5), # KL penalty PPO1
dict(name='kl_pen', kl_target=0.005, lam=0.5), # KL penalty PPO1
dict(name='clip', epsilon=0.2), # Clipped surrogate objective, find this is better PPO2
]
ENV_ID = 'Pendulum-v0' # environment name
ALG_NAME = 'PPO'
RANDOMSEED = 1 # random seed
2.class PPO(object)
- PPO类需要实现10个方法。
-
_init_:神经网络网络初始化。
-
update_old_pi:把actor的参数复制给actor_old以更新actor_old。
-
store_transition:保存transition到buffer中。
-
finish_path:使用reward计算对应t时刻的回报Ut。
-
choose_action:选择动作。
-
train_actor:更新policy network的参数。
-
train_critic:更新state-value network的参数。
-
update:更新整个网络的参数。
-
saveModel:保存模型。
-
loadModel:加载模型。
-
2.1._init_
创建state-value network
# 状态价值网络,输入状态,输出折扣回报Ut
def build_critic(input_state_dim):
input_layer = tl.layers.Input(input_state_dim, tf.float32)
l1 = tl.layers.Dense(100, tf.nn.relu)(input_layer)
output_layer = tl.layers.Dense(1)(l1)
return tl.models.Model(input_layer, output_layer)
创建policy network
# actor 网络,输出均值mu和方差sigma
def build_actor(input_state_dim, action_dim):
input_layer = tl.layers.Input(input_state_dim, tf.float32)
l1 = tl.layers.Dense(100, tf.nn.relu)(input_layer)
a = tl.layers.Dense(action_dim, tf.nn.tanh)(l1)
mu = tl.layers.Lambda(lambda x: x * action_range)(a)
sigma = tl.layers.Dense(action_dim, tf.nn.softplus)(l1)
model = tl.models.Model(input_layer, [mu, sigma])
return model
- mu就是正态分布的均值,也就是最有可能取的action的地方,因此可以将预测的a作为mu。
- 为什么计算方差sigma使用的激活函数是softplus( l n ( 1 + e x ) ln(1+e^x) ln(1+ex) )而不是relu( m a x ( 0 , x ) max(0, x) max(0,x) )?
- softplus和relu长得非常像,并且他们的作用是一样的,但relu有时候会导致神经元的“死亡”问题,而softplus不会。
_init_
def __init__(self, state_dim, action_dim, action_range, method_name='kl_pen'):
# 构建critic网络, 输入state,输出V值
self.critic = build_critic([None, state_dim])
self.critic.train()
# actor有两个actor 和 actor_old, actor_old的主要功能是记录行为策略的版本。
# 输入时state,输出是描述动作分布的mu和sigma
self.actor = build_actor([None, state_dim], action_dim)
self.actor_old = build_actor([None, state_dim], action_dim)
self.actor.train()
self.actor_old.eval()
self.actor_opt = tf.optimizers.Adam(args.actor_lr)
self.critic_opt = tf.optimizers.Adam(args.critic_lr)
if method_name == 'kl_pen':
self.method = METHODS[0]
self.kl_target = self.method['kl_target']
self.lam = self.method['lam']
elif method_name == 'clip':
self.method = METHODS[1]
self.epsilon = self.method['epsilon']
self.state_buffer, self.action_buffer = [], []
# reward_buffer存放奖励rt,而cumulative_reward_buffer存放回报Ut
self.reward_buffer, self.cumulative_reward_buffer = [], []
self.action_range = action_range
2.2.update_old_pi
def update_old_pi(self):
# 更新actor_old参数。
for pi, oldpi in zip(self.actor.trainable_weights, self.actor_old.trainable_weights):
oldpi.assign(pi)
2.3.store_transition
def store_transition(self, state, action, reward):
self.state_buffer.append(state)
self.action_buffer.append(action)
self.reward_buffer.append(reward)
2.4.finish_path
def finish_path(self, next_state, done):
"""
Calculate cumulative reward
:param next_state:
:return: None
"""
if done:
v_s_ = 0
else:
v_s_ = self.critic(np.array([next_state], dtype=np.float32))[0, 0]
discounted_r = []
for r in self.reward_buffer[::-1]:
v_s_ = r + args.gamma * v_s_
discounted_r.append(v_s_)
discounted_r.reverse()
discounted_r = np.array(discounted_r)[:, np.newaxis]
self.cumulative_reward_buffer.extend(discounted_r)
self.reward_buffer.clear()
-
v_s_的形状为[batch_size, 1],如[[1],[2],[3],[4],[5]]。数组里的每一个子数组代表一个state的value。
- 一般来说,数组里的每一个子数组就代表了那个state对应的输出。
- 对critic的输出取[0,0]是想取第一个state(输入只有一个state)的value。
-
discounted_r求出来只是一个一维数组[batch_size],因此给它添加一个新的维度让他变成形状为[batch_size, 1]的二维数组。
- 如果原本形状是[batch_size],使用[:, np.newaxis]后形状就变成了[batch_size, 1];使用[np.newaxis,: ]后,形状就变成了[1,batch_size]。也就是np.newaxis放在哪个位置就增加哪个位置的维度。
-
for r in self.reward_buffer[::-1]的作用是逆序遍历列表reward_buffer。 -
extend的作用是在列表末尾一次性追加另一个序列中的多个值。
a = [1,2,3]
b = [4,5,6,7]
b.extend(a)
print(b)
#输出:[4, 5, 6, 7, 1, 2, 3]
2.5.choose_action
def choose_action(self, s):
s = s[np.newaxis, :].astype(np.float32)
mu, sigma = self.actor(s)
pi = tfp.distributions.Normal(mu, sigma) # 用mu和sigma构建正态分布
a = tf.squeeze(pi.sample(1), axis=0)[0] # 根据概率分布随机出动作
return np.clip(a, -self.action_range, self.action_range)
- squeeze的作用是去掉从tensor中删除所有大小(szie)是1的维度。
- 如t是一个形状为[1, 2, 1, 3, 1, 1]的tensor,则
tf.squeeze(t)的形状为[2,3]。 - 可以通过axis参数来指定作用于哪个维度。如
tf.squeeze(t, [2, 4])的形状为[1,2,3,1],只删除了第2和第4维的1。 - 在本代码中,pi.sample(1)的返回值是一个shape=(1,1,1)的数组(如[[[1.21515]]]),通过
tf.squeeze(pi.sample(1), axis=0)后,就将第一维删掉了,变成了shape=(1,1)的数组([[1.21515]]),再取第一个元素,就是一个一维数组。- 至于为什么pi.sample(1)是一个三维向量,且shape=(1,1,1),这是因为pi.sample(1)的第0维表示sample的个数,如果写成pi.sample(2),则生成的向量是shape=(2,1,1),后面两个维度是由mu和sigma决定的。mu和sigma都是shape=(1,1)的向量,第0维表示了输入给critic network的transition的个数,每一个transition都对应一个mu和sigma输出,mu和sigma的第1维则表示了真正的数据,它的大小是由动作空间的维度决定的。
- 如果看了以上说明还不明白,推荐自己调试一下,看看每步的变量的shape是怎样变化的,分别代表什么意思。
- 如t是一个形状为[1, 2, 1, 3, 1, 1]的tensor,则
2.6.train_actor
def train_actor(self, state, action, adv):
'''
更新策略网络(policy network)
'''
# 输入时s,a,td-error。这个和AC是类似的。
state = np.array(state, np.float32) # state
action = np.array(action, np.float32) # action
adv = np.array(adv, np.float32) # td-error
with tf.GradientTape() as tape:
# 【敲黑板】这里是重点!!!!
# 我们需要从两个不同网络,构建两个正态分布pi,oldpi。
mu, sigma = self.actor(state)
pi = tfp.distributions.Normal(mu, sigma)
mu_old, sigma_old = self.actor_old(state)
oldpi = tfp.distributions.Normal(mu_old, sigma_old)
# ratio = tf.exp(pi.log_prob(self.tfa) - oldpi.log_prob(self.tfa))
# 在新旧两个分布下,同样输出a的概率的比值
# 除以(oldpi.prob(tfa) + EPS),其实就是做了import-sampling。怎么解释这里好呢
# 本来我们是可以直接用pi.prob(tfa)去跟新的,但为了能够更新多次,我们需要除以(oldpi.prob(tfa) + EPS)。
# 在AC或者PG,我们是以1,0作为更新目标,缩小动作概率到1or0的差距
# 而PPO可以想作是,以oldpi.prob(tfa)出发,不断远离(增大or缩小)的过程。
ratio = pi.prob(action) / (oldpi.prob(action) + args.eps)
# 这个的意义和带参数更新是一样的。
surr = ratio * adv
# 我们还不能让两个分布差异太大。
# PPO1
if self.method['name'] == 'kl_pen':
tflam = self.method['lam']
kl = tfp.distributions.kl_divergence(oldpi, pi)
kl_mean = tf.reduce_mean(kl)
aloss = -(tf.reduce_mean(surr - tflam * kl))
else: # clipping method, find this is better
aloss = -tf.reduce_mean(
tf.minimum(surr, tf.clip_by_value(
ratio, 1. - self.method['epsilon'], 1. + self.method['epsilon']) * adv)
)
a_gard = tape.gradient(aloss, self.actor.trainable_weights)
self.actor_opt.apply_gradients(zip(a_gard, self.actor.trainable_weights))
if self.method['name'] == 'kl_pen':
return kl_mean
- prob是某个分布的概率密度函数。在连续性随机分布中,取到某一个点的概率都是0,因此只能用概率密度函数代替。
2.7.train_critic
def train_critic(self, cumulative_reward, state):
''' 更新Critic网络 '''
# reward 是我们预估的 能获得的奖励
cumulative_reward = np.array(cumulative_reward, dtype=np.float32)
with tf.GradientTape() as tape:
# TD-Error,Ut-qt
td_error = cumulative_reward - self.critic(state)
loss = tf.reduce_mean(tf.square(td_error))
grad = tape.gradient(loss, self.critic.trainable_weights)
self.critic_opt.apply_gradients(zip(grad, self.critic.trainable_weights))
2.8.update
def update(self):
'''
Update parameter with the constraint of KL divergent
'''
s = np.array(self.state_buffer, np.float32)
a = np.array(self.action_buffer, np.float32)
u = np.array(self.cumulative_reward_buffer, np.float32)
self.update_old_pi()
adv = (u - self.critic(s)).numpy()
# adv = (adv - adv.mean())/(adv.std()+1e-6) # sometimes helpful
# update actor
if self.method['name'] == 'kl_pen':
kl = 0
for _ in range(args.actor_update_steps):
kl = self.train_actor(s, a, adv)
if kl > 4 * self.method['kl_target']: # this is in google's paper
break
if kl < self.method['kl_target'] / 1.5: # adaptive lambda, this is in OpenAI's paper
self.method['lam'] /= 2
elif kl > self.method['kl_target'] * 1.5:
self.method['lam'] *= 2
self.method['lam'] = np.clip(
self.method['lam'], 1e-4, 10
) # sometimes explode, this clipping is MorvanZhou's solution
# PPO2 clipping method, find this is better (OpenAI's paper)
else:
for _ in range(args.actor_update_steps):
self.train_actor(s, a, adv)
# update critic
for _ in range(args.critic_update_steps):
self.train_critic(u, s)
# 为了保证buffer里的数据是old_actor的,每更新完一遍参数要把transition数据清空
self.state_buffer.clear()
self.action_buffer.clear()
self.cumulative_reward_buffer.clear()
self.reward_buffer.clear()
- 重要性采样是怎么体现的?
- 在update函数中,先用actor更新old_actor,然后再调用train_actor函数更新actor。在train_actor函数中,不断更新actor,但old_actor是不会变的,buffer里的transition也是old_actor做出的,符合old_actor的分布,但在更新完actor后,在update的末尾要清楚buffer中的数据,保证buffer里的数据在下一次更新时,一定是下一次的old_actor做出的。
- 在update函数中,更新了多次actor,每个batch_size的数据都可以重复利用多次。
2.9.saveModel
def saveModel(self):
path = os.path.join('model', '_'.join([ALG_NAME, ENV_ID]))
if not os.path.exists(path):
os.makedirs(path)
tl.files.save_weights_to_hdf5(os.path.join(path, 'actor.hdf5'), self.actor)
tl.files.save_weights_to_hdf5(os.path.join(path, 'actor_old.hdf5'), self.actor_old)
tl.files.save_weights_to_hdf5(os.path.join(path, 'critic.hdf5'), self.critic)
print('Saved weights.')
2.10.loadModel
def loadModel(self):
path = os.path.join('model', '_'.join([ALG_NAME, ENV_ID]))
if os.path.exists(path):
print('Load DQN Network parametets ...')
tl.files.load_hdf5_to_weights_in_order(os.path.join(path, 'actor.hdf5'), self.actor)
tl.files.load_hdf5_to_weights_in_order(os.path.join(path, 'actor_old.hdf5'), self.actor_old)
tl.files.load_hdf5_to_weights_in_order(os.path.join(path, 'critic.hdf5'), self.critic)
print('Load weights!')
else:
print("No model file find, please train model first...")
3.主程序
3.1.帧画面转化为gif函数
def display_frames_as_gif(frames, path):
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames), interval=5)
anim.save(path, writer='pillow', fps=30)
3.2.main函数
if __name__ == '__main__':
env = gym.make(ENV_ID)
# reproducible
env.seed(RANDOMSEED)
np.random.seed(RANDOMSEED)
tf.random.set_seed(RANDOMSEED)
ppo = PPO(
state_dim=env.observation_space.shape[0],
action_dim=env.action_space.shape[0],
action_range=env.action_space.high,
)
ppo.loadModel()
if args.train:
all_ep_r = []
# 更新流程:
for episode in range(args.train_episodes):
state = env.reset()
episode_reward = 0
t0 = time.time()
for t in range(args.max_steps):
if args.render:
env.render()
action = ppo.choose_action(state)
next_state, reward, done, _ = env.step(action)
# 对reward进行标准化,已经被证明有时候是有用的
ppo.store_transition(state, action, (reward + 8) / 8)
state = next_state
episode_reward += reward
# N步更新的方法,每BATCH步了就可以进行一次更新
if (t + 1) % args.batch_size == 0 or t == args.max_steps - 1:
ppo.finish_path(next_state, done)
ppo.update()
if episode == 0:
all_ep_r.append(episode_reward)
else:
all_ep_r.append(all_ep_r[-1] * 0.9 + episode_reward * 0.1)
print(
'Episode: {}/{} | Episode Reward: {:.4f} | Running Time: {:.4f}'.format(
episode, args.train_episodes, episode_reward,
time.time() - t0
)
)
# 一百轮保存一遍模型
if episode % 100 == 0:
ppo.saveModel()
# 保存散点图
plt.plot(all_ep_r)
if not os.path.exists('image'):
os.makedirs('image')
plt.savefig(os.path.join('image', '_'.join([ALG_NAME, ENV_ID])))
else:
for episode in range(args.test_episodes):
state = env.reset()
episode_reward = 0
frames = []
for i in range(args.max_steps):
env.render()
frames.append(env.render(mode='rgb_array'))
next_state, reward, done, _ = env.step(ppo.choose_action(state))
episode_reward += reward
state = next_state
if done:
break
print('Testing | Episode: {}/{} | Episode Reward: {:.4f}'.format(
episode, args.test_episodes, episode_reward))
# 将本场游戏保存为gif
if args.save_gif:
dir_path = os.path.join('testVideo', '_'.join([ALG_NAME, ENV_ID]))
if not os.path.exists(dir_path):
os.makedirs(dir_path)
display_frames_as_gif(frames, dir_path + '\\' + str(episode) + ".gif")
env.close()
训练结果
2000次



遇到的坑
- question1(未解决):内存泄漏,导致程序越执行占用的内存越多,跑到一万多轮后几乎把内存都占满了。
- 怀疑是buffer用完后,使用clear方法清除数据,没有释放内存。但是在使用
del action_buffer[:]语句手动删除buffer并调用垃圾回收后,仍然未能解决问题。
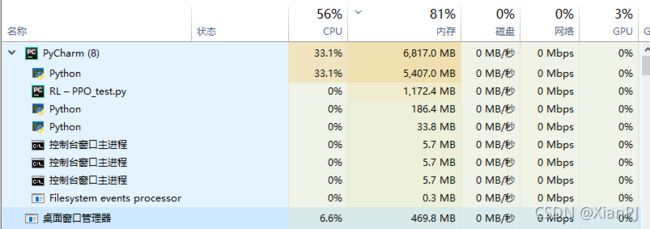
- 怀疑是buffer用完后,使用clear方法清除数据,没有释放内存。但是在使用
DQN with Target代码实现