李宏毅《机器学习》笔记:2.线性回归
# 2021.09.04
# 抱歉拖更了,最近事太多了,如果点赞超过一个,明天更新下一P
# 内容P3-P4
# 可参考以前一篇内容:https://blog.csdn.net/wistonty11/article/details/115719169
文章目录
- P3:线性回归
-
- 3.0 机器学习分类
- 3.1 什么是回归
- 3.2 线性回归
- 3.3 模型步骤
-
- 3.3.1 选择模型框架:线性模型
- 3.3.2 模型评估:损失函数
- 3.3.3 最佳模型:梯度下降
- 3.4 如何验证好坏
-
- 3.4.1 适当增加函数复杂度
- 3.4.2 加入更多影响因子
- 3.4.3 优化:加入正则化
P3:线性回归
3.0 机器学习分类
不知道是否准确。参考1、参考2
-
机器学习分类
监督学习、无监督学习、强化学习、半监督等
-
监督学习分类
回归问题、分类问题
-
模型
线性回归 逻辑回归
3.1 什么是回归
找到一个函数 f ( x ) f(x) f(x) ,通过输入特征数据x,输出一个数值 Scalar
-
【助解】类似于回归自然,回归自我。回归就是用估计值来靠近真实值
-
【和分类的区别】
分类和回归的区别不在于输入,而是输出的连续还是离散
预测房价的价格是一个回归任务;
我们数据多了,100平方的房子100万和100.5平方的房子100.5万,输出的房价是非常靠近的,分得越小输出约连续。
预测一张图片是猫还是狗的图片是分类任务。
-
回归问题也可以变成分类问题
比如我只有100.3万 超过了不买,没超过买。那么就成了分类问题。也变成了离散的
3.2 线性回归
线性回归就是要找一条线,尽可能地拟合(靠近)图中的数据点。
- 比如以下输入点大致满足线性


3.3 模型步骤
- step1:模型假设,选择模型框架(线性模型)
- step2:模型评估,如何判断众多模型的好坏(损失函数)
- step3:模型优化,如何筛选最优的模型(梯度下降)
3.3.1 选择模型框架:线性模型
线性模型 Linear model: y = b + ∑ w i x i y = b + \sum w_ix_i y=b+∑wixi
-
① 这个y是个估计值,我们确定模型后,通过数据 x i x_i xi,计算出来的,通常和真实值有误差;
-
② 这里 x i x_i xi为向量,是一个特征
比如:
x c p x_{cp} xcp为宝可梦CP(战斗点数),y理解为战斗力,它的战斗力不仅和战斗点数有关,可能还和物种(Bulbasaur)、血量(HP)、重量(Weight)、高度(Height)等特征有关 -
③ b是偏移量,是个具体数
3.3.2 模型评估:损失函数
- 我们拿到一批数据,已知: x i x_i xi, 真实值 y ^ \hat{y} y^ 未确定:w, b
- 目的是:真实值和估计值中间差最小
我们将真实值和估计值设置这个差值叫做损失函数Loss
以单个特征 x c p x_{cp} xcp为例, 我们手里有1-10级的数据
损失函数: L ( f ) = ∑ n = 1 10 ( y ^ − f ( x c p n ) ) 2 L(f) = \sum_{n=1}^{10}{({\hat{y}-f(x_{cp}^n)})^2} L(f)=∑n=110(y^−f(xcpn))2
因为估计值: f ( x c p n ) = b + w ∗ x c p n f(x_{cp}^n)=b+w*x_{cp}^n f(xcpn)=b+w∗xcpn
∴ \therefore ∴ L ( w , b ) = ∑ n = 1 10 ( y ^ − ( b + w ∗ x c p n ) ) 2 L(w,b)=\sum_{n=1}^{10}{({\hat{y}-(b+w*x_{cp}^n)})^2} L(w,b)=∑n=110(y^−(b+w∗xcpn))2
我们目的就是这个L值最小。
3.3.3 最佳模型:梯度下降
如何来确定w,b从而确定比较准确的线性函数呢?
- 步骤1:随机选取一个 w 0 , b 0 w^0,b^0 w0,b0
- 步骤2:计算微分,也就是当前的斜率,根据斜率来判定移动的方向:①大于0向右移动(增加w)②小于0向左移动(减少w)

- 步骤3:根据学习率移动
- 重复步骤2和步骤3,直到找到最低点

【举个例子】这里展示的重点是梯度下降计算方法,梯度下降详细内容,请看下章内容
https://blog.csdn.net/wistonty11/article/details/120118145

我们目标就是找F(w,b) 的最小值(F这里面就是损失函数,b,w为两个参数),想法是不断修正w,b的值
- 我们假设w=1 b=1 的初值,学习率为0.1
- 计算 F ( w , b ) = ( 1 + 1 ) 2 = 4 F(w,b)=(1+1)^2=4 F(w,b)=(1+1)2=4
- 我们修正b,对b求导,得2w+2b;修正w,对w求导,得2w+2b;因为一样,表格只写了2w+2b
- 计算 η ( 2 w 1 + 2 b 1 ) = 0.1 ∗ ( 2 ∗ 1 + 2 ∗ 1 ) = 0.4 \eta(2w_1+2b_1)=0.1*(2*1+2*1)=0.4 η(2w1+2b1)=0.1∗(2∗1+2∗1)=0.4
- 修正后: w 2 = w 1 − 0.4 ( w 0 修 正 部 分 ) = 0.6 w_2=w_1-0.4(w_0修正部分)=0.6 w2=w1−0.4(w0修正部分)=0.6,同b2=0.6
- 我们假设 w 2 = 0.6 , b 2 = 0.6 w_2=0.6,b_2=0.6 w2=0.6,b2=0.6的初值,学习率为0.1
- 目标函数 F ( w , b ) = ( 0.6 + 0.6 ) 2 = 1.44 F(w,b)=(0.6+0.6)^2=1.44 F(w,b)=(0.6+0.6)2=1.44
- 对n=2的修正部分: η ( 2 w 2 + 2 b 2 ) = 0.1 ∗ ( 2 ∗ 0.6 + 2 ∗ 0.6 ) = 0.24 \eta(2w_2+2b_2)=0.1*(2*0.6+2*0.6)=0.24 η(2w2+2b2)=0.1∗(2∗0.6+2∗0.6)=0.24
- 修正后: w 3 = w 2 − 0.24 ( w 1 修 正 部 分 ) = 0.36 w_3=w_2-0.24(w_1修正部分)=0.36 w3=w2−0.24(w1修正部分)=0.36,同b3=0.36
循环下去,直到第17轮, w 17 = 0 , b 17 = 0 w_{17}=0,b_{17}=0 w17=0,b17=0时,目标函数F为0,结束收敛。
【注意】
- 图标中n=10的时候F为0,其实是有数值的,但显示4位没显示全。
- 在计算机计算过程中,因为误差,如果你设置循环结束条件是0可能循环停不下来,一般做法是【小于一个很小的数】作为结束条件;比如 w < 1 0 − 15 w<10^{-15} w<10−15作为借书条件
【w,b,η 初始值不同,最终结果会不同】
可看链接第六部分,注意
https://blog.csdn.net/wistonty11/article/details/115719169
3.4 如何验证好坏
3.4.1 适当增加函数复杂度
我们前面做的是找到这个模型f,让模型尽可能的对已知的数据重合,但验证模型好坏,是一批新的数据(检验集)
- 使用 y = b + w ∗ x c p y=b+w*x_{cp} y=b+w∗xcp,训练集和测试集训练的平均误差为31,9

- 使用 y = b + w ∗ x c p y=b+w*x_{cp} y=b+w∗xcp,新的数据,平均误差为35.0
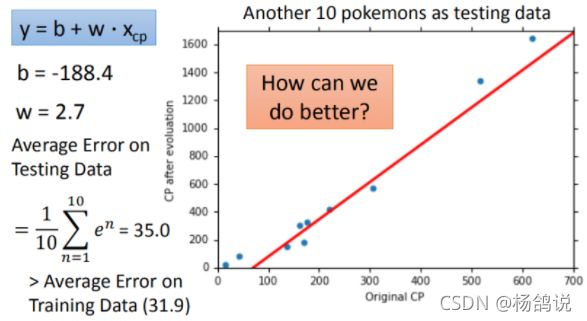
- 使用 y = b + w 1 ∗ x c p + w 2 ∗ x c p 2 y=b+w_1*x_{cp}+w_2*x_{cp}^2 y=b+w1∗xcp+w2∗xcp2,训练数据,平均误差为15.4;新的数据误差为,18.4

- 不断复杂估值函数可以么?
实验证明是不可以的。不断复杂估值函数,我们训练数据估出来的y会越来越接近训练数据的真实值,但我们手里的数据是有限的,我们的目的是估值函数普遍受用,我们发现当增加5次的时候,在新数据中,反而误差变大了,反而违反了初衷,这种现象叫做Overfitting(过拟合)

适当复杂估值函数是可以减少误差的,太复杂可能过拟合。
3.4.2 加入更多影响因子
造成宝可梦最终攻击能力,不仅要看cp值,还可能受宝可梦种类,血量等因素影响。
那我们将四个种类因素合成一个式子来进行学习。

3.4.3 优化:加入正则化
权重 w 可能会使某些特征权值过高,仍旧导致overfitting,所以加入正则化。

增加正则因子(惩罚因子regularzation)
- 参数w取值更加小,得到的结果更加准确,函数更加平滑.
因为w权重小了,当x变了一个x + △ x(很大的变化量)的时候,整体的y = w ∗ x + b 才会变化,在图上,随着x变化,越小的wi,使f变化变得缓慢,更光滑。更容易找到更好的w,b,即找到的估值函数更靠谱。
- 理论上,那么这个 λ \lambda λ越大,w权重越大,那么w可以变化可以越细微,得到的值就会更准确,是真的么?
- 如果 λ \lambda λ非常大,w权重非常大,那么w可以变化极其细微,也就使得函数非常光滑,近似于一条直线,可能效果反而会不好
λ = 100 时 \lambda=100时 λ=100时,测试结果已经达到Loss=11.1 相对于刚才得出的最好结果(选择指数为3次的函数)18.1,又进步了不少。

增加正则因子可以优化函数,其中 λ \lambda λ取值要适当, w i w_i wi越小,函数越光滑,结果更准确。