基于深度学习的视觉目标检测技术综述
基于深度学习的视觉目标检测技术综述——阅读
曹家乐,李亚利,孙汉卿,谢今,黄凯奇,庞彦伟(天津大学, 天津 300072;清华大学, 北京 100084;重庆大学, 重庆 400044;中国科学院自动化研究所, 北京 100190)
视觉目标检测用于定位和识别图像中存在的物体,是许多计算机视觉任务的基础,
本文总结了深度学习目标检测在训练和测试过程中的基本流程。
1.训练阶段包括数据预处理、检测网络、标签分配与损失函数计算等过程,
2.测试阶段使用经过训练的检测器生成检测结果并对检测结果进行后处理,
3.回顾基于单目标相机的视觉目标检测方法,包括基于锚点框的方法,无锚点框的方法和端到端的方法、
4.总结了目标检测中常见的子模块设计方法。
5.在基于单目相机的视觉目标检测方法后,介绍基于双目标相机的视觉目标检测方法。在此基础上,分别对比了单目目标检测和双目标检测的国内外研究进展,分析了视觉目标检测技术发展趋势。
6.通过总计和分析,提供视觉目标检测相关研究提供参考。
0引言
视觉目标检测用于定位图像中存在物体的位置并识别物体的具体类别。
1.本文首先介绍目标检测的基本流程,包括训练和检测过程。
2.总结和分析视觉目标检测。
3.介绍双目标视觉目标检测。
4.对比国内外发展现状。
5.并对发展趋势进行展望。
1基于深度学习的目标检测基本流程
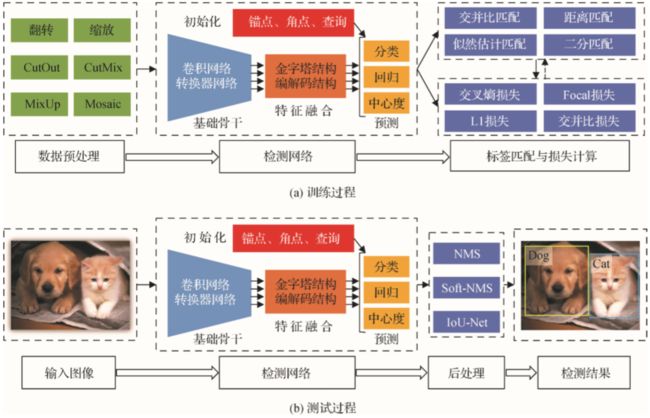
深度学习目标检测主要包括训练过程和测试过程。
训练的目标利用训练数据集进行网络的参数学习。训练数据集包含大量视觉图像及标注信息。
1)数据预处理。
用于增强训练数据多样性,提出检测网络的检测能力,
常用方法:翻转、缩放、均值归一化、色调变化等。
CutOut:提出从图像中擦除部 分子区域
MixUP:通过不同图像和标签进行差值表示提升分类性能。
CutMix:提出将其他训练图像粘贴到擦除的子区域。
Mosaic:将多个图像拼接在一起进行训练,提升检测器应对尺度变化的鲁棒性
2)检测网络。
检测网络包括:基础骨干、特征融合及预测网络。
基础骨干:
目标检测器的基础骨干采用图像分类的深度卷积网络(AlexNet、VGGNet、ResNet、DenseNet、Transformer、Vit、Swin、PVT)
将大规模图像分类数据库ImageNet上的预测试权重作为检测器骨干网络的初始权重。
特征融合:
主要是对基础骨干提取的特征进行融合,用于后续分类和回归。
常见特征融合方式:特征金字塔结构、基于Transformer编解码
预测网络:
预测网络包括进行分类和回归。
在两阶段目标检测方法中,分类和回归通常采用全连接方式,
在单阶段目标检测方法中,分类和回归通常采用全卷积方式。
标签分配与损失计算:
标签分配主要是为了检测器预测提供真实值。
标签分配的准则:交并比准则(通常用于基于锚点框的目标检测方法,根据锚点框与物体真实框之间的交并比将锚点框分配到对应的物体)、距离准则(通常用于无锚点框的目标检测方法,根据点到物体中心的距离将其分配到对应的 物体)、似然估计准则(通常基于分类和回归的联合损失进行最优标签分配)和二分分配(通常基于分类和回归的联合损失进行最优标签分配)。
基于标签分类的结果,采用损失函数计算分类和回归等任务的损失,并利用反向传播算法更新检测网络的权重。
常用分类损失函数:交叉熵损失函数,聚焦损失函数,回归损失函数(L1损失函数、平滑损失函数、并交比IoU损失函数、GIoU损失函数,GIoU损失函数,CIoU损失函数)
基于训练阶段学习的检测网:
在检测阶段输出给定图像中存在的类别以及位置信息。
包括:输入图像、检测网络、后处理(为每个物体保留一个检测结果并去除其他冗余的检测结果,常用方法:非极大值抑制方法NMS,soft-NMS,IoUNet)。
2单目视觉目标检测
2.1基于锚点框的目标检测方法
基于锚点框的目标检测方法为空间每一个位置设定多个矩形框,尽可能地覆盖图像中的所有存在物体。
基于锚点框的目标检测方法:两阶段目标检测方法,单阶段目标检测方法。

两阶段:首先提出k个类别不具体的候选检测窗口,然后进一步对候选检测窗口进行分类和回归,生成最终的检测结果。具有较高的检测精度。
单阶段:直接对锚点框进行分类和回归。具有较快的推理速度。
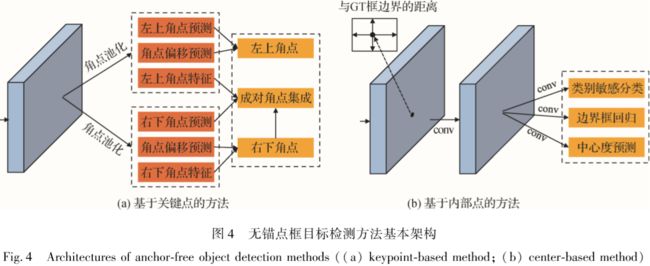
2.2无锚点框目标检测方法
无锚点框目标检测方法:基于关键点的目标检测,基于内部点的目标检测
基于关键点的目标检测:通常通过预测物体的多个关键点,并将关键点集成实现对物体的检测。
基于内部点的目标检测:预测物体内部点到物体边界的上下左右偏移量及内部点所属的类别信息等。
2.3端对端预测的目标检测方法
端对端预测的目标检测方法:直接端对端地为每个物体预测一个检测框。
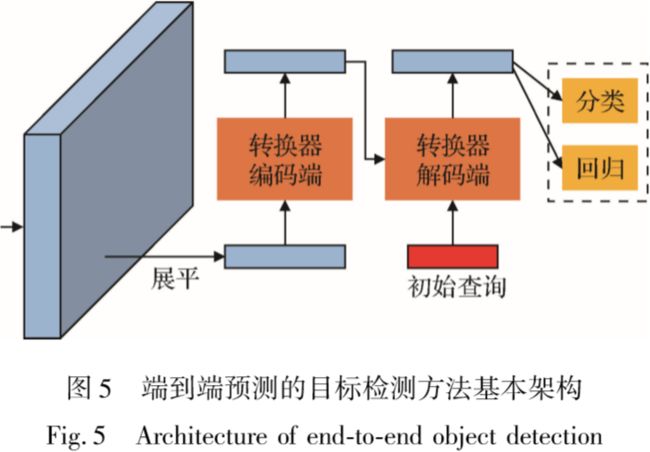
DETR利用卷积神经网络提取特征,基于Transformer编解码网络直接预测物体的位置以及分类得分。
Deformable DETR提出了基于局部稀疏 的可形变注意力模块,克服了DETR收敛速度较慢、小尺度目标检测性能相对较差的缺点。
2.4检测子模块设计
检测子模块设计包括:特征金字塔结构设计,预测头网络设计,标签匹配与损失函数设计,知识蒸馏
特征金字塔结构设计:用于目标检测应对物体尺度变化。
预测头网络设计:主要为分类与回归两类。
标签匹配与损失函数设计:根据交并比准则或者距离准则判定样本(如锚点框)的标签(属于哪个物体)。
知识蒸馏:用于让大网络去引导网络的学习,帮助小网络具有较快速度并间距大网络的检测精度。
3双目视觉目标检测
双目视觉可以根据物体投影在左右图像上的位置差异计算出视差,并在已知相机参数的情况下的位置差异计算像素的深度。其可以预测物体的二维位置和类别信息,还可以预测三维空间中的位置。
3.1基于直接视锥空间的双目目标检测方法
基于直接视锥空间的双目目标检测不需要进行额外的空间转换,只需要使用基础骨干提取的两个单目特征构造双目特征。
基于串接构造视锥空间特征的方法:其将基础骨干提取的两个单目视锥空间特征串接起来,利用卷积神经网络强大的拟合能力提取候选框或直接检测三维目标。串接操作不改变原单目特征的坐标空
间,是一种简单快速的视锥空间双目特征构造方式。
基于平面扫描构造视锥空间特征的方法:通过逐视差平面或逐深度平面地扫描一对二维特征,所得三维特征匹配代价体,能直接利用点云监督取得更好的匹配结果,进而学习到每个视锥空间像素是否被物体占据的信息。
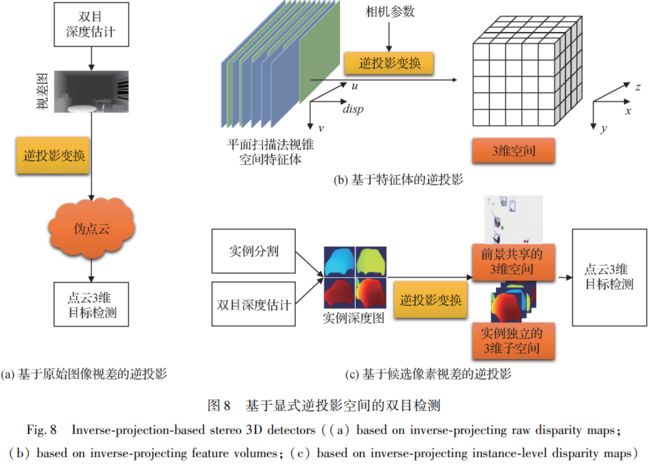
3.2基于显式逆投影空间的双目目标检测方法
基于原始图像视差的逆投影方法:先利用双目视差估计算法预测出逐像素的视差,将这些像素逆投影到三维空间生成点云形式,从而使用相对成熟的点云三维检测方法进行双目目标检测。
基于特征体的逆投影方法:通过插值和采样的方法将平面扫描得到的颜色和纹理信息,实现了端到端训练的双目目标检测
基于候选像素视差的逆投影方法:生成了全空间的点云。
4国内外研究进展比较
4.1单目视觉目标检测技术
早期国外在基于深度学习的视觉目标检测方面开展了两阶段目标检测器 R-CNN 系列、单阶段目标检测器 YOLO、端到端目标检测器 DETR等。
近些年国内开始在深度目标检测技术方面,特别是单阶段目标检测技术和端到端目标检测。
4.2双目视觉目标检测技术
双目视觉检测主要应用于无人机和自动驾驶等领域。
5发展趋势与展望
1)高效率的端到端目标检测
2)基于自监督学习的目标检测
3)长尾分布目标检测
4)小样本、零样本目标检测
5)大规模双目目标检测数据集
近些年国内开始在深度目标检测技术方面,特别是单阶段目标检测技术和端到端目标检测。
4.2双目视觉目标检测技术
双目视觉检测主要应用于无人机和自动驾驶等领域。
5发展趋势与展望
1)高效率的端到端目标检测
2)基于自监督学习的目标检测
3)长尾分布目标检测
4)小样本、零样本目标检测
5)大规模双目目标检测数据集
6)弱监督双目目标检测