Win10自定义路径位置安装WSL2 (Ubuntu 20.04) 并配置CUDA
目录
C盘默认位置安装Ubuntu
自定义位置安装Ubuntu
确保安装程序已经下载
打开微软商店应用默认安装目录
找到Ubuntu安装包的默认下载位置
复制安装包和相关文件到想要的安装位置
运行安装包,安装Ubuntu
删除原始安装包和相关文件
让Ubuntu快捷启动
其它黑科技
WSL运行状态、开/关机
WSL已安装发行版信息查询
开机/关机
Windows下快速访问WSL的文件系统
WSL2运行GUI图形界面应用
wslg图形应用内容显示太小的解决方法
WSL2 Ubuntu 20.04使用NVIDIA CUDA
CUDA基础知识
确定要安装的版本
安装Windows上的NVIDIA GPU驱动
WSL2 Ubuntu安装NVIDIA CUDA工具包
WSL2 Ubuntu安装NVIDIA cuDNN深度学习库
WSL2 Ubuntu安装PyTorch机器学习框架
Linux字符终端基础设施
几个基本概念
Terminal 终端
Console 控制台
Command Line 命令行
Shell
程序与用户交互的几种方式
CLI 命令行接口
TUI 基于文字的用户接口
GUI 图形用户接口
WebUI 网络用户接口
文本编辑器:Vim/Neovim
Vim是什么
Vim的优势
博主的Vim/Neovim配置
图片展示器:TerminalImageViewer
基于gdb的代码调试器
准备待调试的代码
CLI式代码调试器:gdb
TUI式代码调试器:gdb --tui 与 cgdb
WebUI式代码调试器:gdbgui
命令行Markdown渲染器

⚠️⚠️⚠️注意⚠️⚠️⚠️
现在微软推出了Ubuntu22.04的WSL2发行版,22.04和之前的版本有较大变化,目前博主测试了好几种办法,发现只能安装在默认位置。如果安装在其他地方,或者是安装好再移动过去,运行ubuntu.exe时都会报错“文件被加密”。因此本教程不适用于最新的Ubuntu22.04,小伙伴们敬请周知~
如果有自定义位置安装22.04的方法,欢迎大家分享!
C盘默认位置安装Ubuntu
✅请参考该教程,非常详细:Windows 10安装 WSL2 (Ubuntu 20.04) https://blog.csdn.net/weixin_45579994/article/details/113896240?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242
https://blog.csdn.net/weixin_45579994/article/details/113896240?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242
✅以下链接是微软官方文档给出的手动安装方法,步骤和上面的教程一致:
旧版 WSL 的手动安装步骤 | Microsoft Docs https://docs.microsoft.com/zh-cn/windows/wsl/install-manual
https://docs.microsoft.com/zh-cn/windows/wsl/install-manual
⚠️注意:如果装在C盘,在应用商店进行launch操作可能会报错如下:
WslRegisterDistribution failed with error: 0xc03a001a原因是安装包所在的文件夹被压缩处理了,解决方案请见这里。
自定义位置安装Ubuntu
⚠️⚠️⚠️注意⚠️⚠️⚠️
请在微软应用商店搜索时务必输入全名Ubuntu20.04。
现在微软推出了新的Ubuntu 22.04的WSL2发行版,应用商店默认的Ubuntu版本号已经更新至22.04。目前发现,改变22.04的安装位置可能导致虚拟机无法启动。
因此,请确保下载的版本是Ubuntu 20.04。
自定义位置安装过程与C盘安装教程相似。最大区别在于,我们按照教程或官方文档从微软商店下载Ubuntu之后,不要点击“启动”,而是要将安装包复制到我们想要的位置,之后Ubuntu就会被安装到该位置。具体步骤如下。
确保安装程序已经下载
在从微软商店下载好Ubuntu之后(但不要点“启动”),在开始菜单会出现类似下图的图标,这就是刚刚下载的Ubuntu安装程序。
在按照教程复制完安装程序,并且完成Ubuntu安装后,我们可以右键图标,将这个原始安装包卸载。
⚠️注意:现在请不要卸载!

打开微软商店应用默认安装目录
使用微软商店下载的应用安装包会默认保存在C:\Program Files\WindowsApps目录下。
如果发现没有权限打开C:\Program Files\WindowsApps文件夹,可以用PowerShell(管理员权限运行)的命令打开,对应的操作为:
cd "C:\Program Files\WindowsApps"
找到Ubuntu安装包的默认下载位置
Ubuntu安装包默认保存在WindowsApps目录下的某个文件夹里。文件夹名称的开头应该类似于CanonicalGroupLimited。
寻找当前目录下以CanonicalGroupLimited开头的文件夹:
dir CanonicalGroupLimited*
可能会有多个类似的文件夹,依次查看这些文件夹:
dir CanonicalGroupLimited(不要回车执行)然后按多次tab键,可以在这些类似的文件夹名之间切换。切换到你想要查看的文件夹,回车执行命令。如果文件夹里面有ubuntu<版本号>.exe文件,这就是我们要找的文件夹。
ubuntu<版本号>.exe就是Ubuntu的安装程序;安装完成后,该程序还可用来启动或访问Ubuntu。

复制安装包和相关文件到想要的安装位置
⚠️注意:你想要安装Ubuntu的位置必须存在,否则接下来的复制操作会报错:
Copy-Item: Container cannot be copied onto existing leaf item.
如果我们想把Ubuntu安装在F盘的“ubuntu2004”文件夹下,就得确保这个文件夹存在。如果不存在,就要手动创建:
mkdir F:\ubuntu2004接着,把安装包所在文件夹下的所有文件复制到你想要安装Ubuntu的文件夹。对应的命令行操作为:
cp <安装包所在的文件夹名>\* <你想要安装ubuntu文件夹的路径>举个例子,这里我们将安装包和相关文件复制到了F盘的“ubuntu2004”文件夹下:
![]()
运行安装包,安装Ubuntu
打开复制到的文件夹,双击运行ubuntu<版本号>.exe即可,等待ubuntu系统初始化。
初始化完毕后,按照C盘安装教程第8步配置好用户名和密码,完成安装。最终,目录下会多出一个vhdx虚拟硬盘文件,它就是Ubuntu WSL2虚拟机挂载的“硬盘”。在WSL2 Ubuntu虚拟机中下载资源、安装软件,都会让这个虚拟硬盘文件变大。

安装结束后,安装目录中的ubuntu<版本号>.exe就是Ubuntu的启动/访问程序。

删除原始安装包和相关文件
正如教程开篇提到的,在开始菜单中可以找到原始安装包的应用图标,右键将其卸载。卸载后Ubuntu从微软商店的已安装列表中消失。
让Ubuntu快捷启动
从此,安装目录中的ubuntu<版本号>.exe就是Ubuntu的启动程序,我们把它添加到开始菜单。

以后可以直接从开始菜单打开Ubuntu,也可以通过Windows键+S键直接搜索ubuntu打开:


对于那些安装了Windows Terminal的小伙伴,Ubuntu会自动添加至其中:

如果发现Windows Terminal的下拉列表里没有这个项目 ,那代表它被自动隐藏了。我们点击“设置”后应当能在左侧边栏找到它。将其取消隐藏,然后保存设置。

其它黑科技
WSL运行状态、开/关机
WSL已安装发行版信息查询
WSL可以安装多个Linux发行版(如Ubuntu、Kali等等)。操作系统由内核+外围程序组成,Linux是操作系统内核的名字,由基于Linux内核的软件组成的操作系统叫做Linux发行版(如Ubuntu、Kali等等)。
我们可以打开powershell,通过以下命令查询机器上安装的所有发行版:
wsl --list --verbose输出一张表格,分别记录了WSL中每一个Linux发行版的名称(NAME)、状态(STATE)和版本(VERSION)。

- NAME:发行版的名称。
- VERSION:发行版所用WSL技术的版本。若VERSION一栏的值为2,代表该发行版使用了WSL2技术;若为1,则该发行版使用WSL1技术。
- STATE:发行版的运行状态。每个发行版都有两个运行状态——运行中(Running)与已停止(Stopped)。前者可以理解为“开机”状态,而后者则为“关机”状态。
开机/关机
WSL中,Linux发行版的开机/启动方法非常简单,只需要运行该发行版的安装-启动程序即可。
关机操作,在powershell中执行以下命令来关闭某一个linux发行版:
wsl --terminate <发行版名称>或者关闭所有发行版:
wsl --shutdown⚠️注意:发行版开机后,只要不手动执行关机操作,或者不关闭物理机器,它将一直保持开机。物理机器在关闭、重新启动后,发行版会关机。
更多wsl命令行操作的官方文档(包括卸载等):
Basic commands for WSL | Microsoft Docs
Windows下快速访问WSL的文件系统
在保证Linux发行版正在运行的情况下,在文件浏览器中输入以下路径,即可访问发行版的文件系统:
\\wsl$
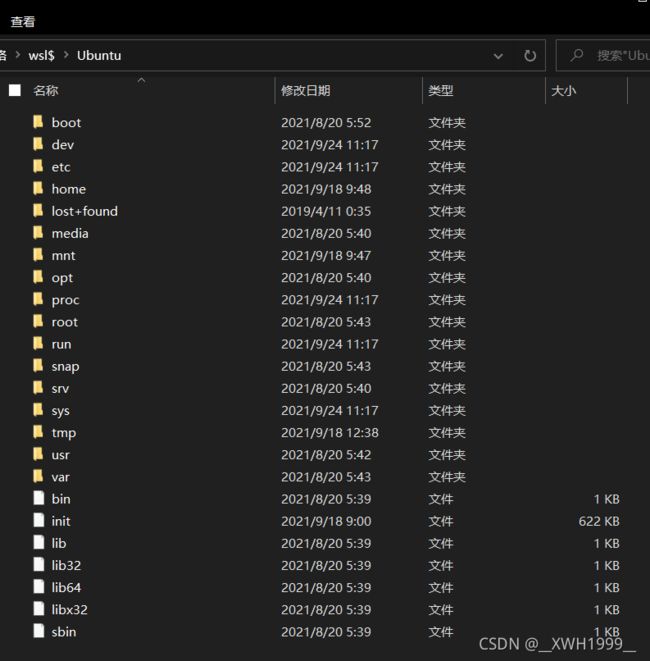
此时我们可以在左侧边栏中,将路径加入快速访问(“固定到快速访问”功能也可能是在上方的文件夹工具栏里,不同系统貌似不一样,找不到的话可以百度一下)。


WSL2运行GUI图形界面应用
微软在Github上发布了wslg项目,旨在为WSL2提供更加自然的GUI图形界面支持,并且提到wslg可以通过安装虚拟GPU驱动来得到物理GPU的加速。
⚠️注意:
该功能对windows系统版本有要求。按下Windows键+R键后,在弹出的“运行”窗口中输入winver,可以快速查询系统版本。
系统要求 Windows 10 Insider Preview build 21362+(wslg项目README描述)或 Windows 11 Build 22000+(微软官方文档描述)。大家可以通过参加Windows预览体验计划升级系统。
wslg在Github的项目地址:
GitHub - microsoft/wslg: Enabling the Windows Subsystem for Linux to include support for Wayland and X server related scenarios
微软官方文档:
Run Linux GUI apps with WSL | Microsoft Docs
博主的win11按照官方文档的描述升级了WSL2的GUI支持。使用上的效果就是,在WSL2的Linux发行版命令行中打开某个GUI图形界面应用(如xterm)后,windows系统会打开一个新的窗口,窗口中运行着该应用,可以进行图形界面的交互。

wslg图形应用内容显示太小的解决方法
当Windows系统设置了显示内容放大,并且放大倍数是整数时(如100%、200%等),wslg会按照相应的放大倍数放大GUI的内容。但若放大倍数不是整数(如125%、150%等),wslg默认不会对GUI内容进行非整数倍放大。本节第一幅图片便是没有放大的效果。

我们需要以管理员权限运行linux发行版,然后新建wslg的配置文件.wslgconfig:
touch /mnt/c/ProgramData/Microsoft/WSL/.wslgconfig然后在文件中添加如下内容,来打开非整数倍放大功能:
[system-distro-env]
WESTON_RDP_DISABLE_FRACTIONAL_HI_DPI_SCALING=false最后,对发行版进行“关机”“开机”操作,使改动生效。下图是修改配置后的效果:

参考的Github回答:
WSLg does not seem to support fractional scaling · Issue #23 · microsoft/wslg · GitHub
WSL2 Ubuntu 20.04使用NVIDIA CUDA
作为一个虚拟机,WSL2居然可以访问到物理宿主机的GPU设备,博主之前还没听说过有哪家公司的虚拟机可以做到这一点。如果WSL2当真可以做到,并且性能可以接受的话,那真是科研党的福音!
⚠️注意:
- 该功能对windows系统版本有要求。系统要求Windows 11或Windows 10, version 21H2。
- 关于支持在WSL2上运行CUDA的显卡型号,NVIDIA文档中只保证了GeForce系列和NVIDIA RTX/Quadro系列显卡支持此功能。文档并未提及其他系列和型号的显卡,可以自行尝试按教程配置,但有可能失败。
微软撰写的为WSL2启用GPU加速的官方文档。该文档记载了WSL2使用NVIDIA CUDA(需要NVIDIA品牌的GPU)和DirectML(GPU不限品牌,AMD/Intel/NVIDIA都可,但需要支持DirectX 12技术)的方法:
GPU acceleration in WSL | Microsoft Docs
在本节中我们主要介绍WSL2 Ubuntu 20.04使用Nvidia CUDA的操作方法,遵循NVIDIA公司给出的官方教程:
CUDA on WSL :: CUDA Toolkit Documentation (nvidia.com)
CUDA基础知识
CUDA(Compute Unified Device Architecture)是由NVIDIA开发的一个并行计算平台和一种并行编程模式,旨在为NVIDIA的GPU提供通用的计算能力。
具体说来,CUDA是NVIDIA为他们公司自己的GPU开发的一套“工具库和工具程序”,它将复杂的底层GPU驱动接口封装起来,只暴露出一套自己的接口给上层应用。你只需要在自己的代码(如C++、Fortran等)中按照规则调用CUDA,再经过CUDA专用编译工具(如nvcc等)的翻译,最终的可执行程序就可以使用GPU进行计算了。
| 用来解决问题的上层应用 |
科研人员或程序员使用TensoFlow、PyTorch等深度学习框架来解决某些复杂问题,并且需要GPU提供算力。 |
| TensoFlow、PyTorch等深度学习框架 |
这些深度学习框架需要调用一些基础的“获得CUDA支持、编译好的C++等程序”,并把它们包装成高级语言的接口,供上层应用调用。 |
| C++、Fortran等程序 |
深度学习框架开发人员在程序代码中嵌入cuDNN或者CUDA相关的代码(即在代码中调用cuDNN和CUDA暴露出的简单接口),然后源代码经过nvcc等编译器翻译为底层GPU驱动程序能看懂的机器码。 |
| cuDNN |
NVIDIA将一些复杂的深度学习算法和数据结构用CUDA提供的接口实现,然后暴露出简洁的接口给上层应用。 |
| CUDA |
NVIDIA将自己设计的GPU的复杂底层驱动接口封装起来,暴露出一套简洁、专用的接口给上层应用, |
| nvcc等CUDA专用编译器 |
专用编译器将程序代码中内嵌的CUDA代码翻译为底层GPU驱动程序能看懂的机器码。 |
| NVIDIA GPU驱动程序 |
底层的显卡驱动程序会根据机器码给的指令,操控显卡进行动作。 |
| NVIDIA GPU物理设备 |
显卡,手能触碰到的物理设备。显卡上的电路根据指令进行动作。 |
确定要安装的版本
从物理设备开始一直到上层应用,CUDA有一条复杂的软件版本依赖链。我们通常从自己电脑的物理GPU型号开始,确定每个环节的软件版本:
| GPU物理设备的型号 | ——决定——> | GPU驱动的版本号 | 对应关系 |
| GPU驱动的版本号 | ——决定——> | CUDA的版本号 | 对应关系 |
| CUDA的版本号 | ——决定——> | cuDNN的版本号 | 对应关系 |
| CUDA的版本号,同上 | ——决定——> | PyTorch等深度学习框架的版本号 | 对应关系 |
举个例子(这一步只是先确定版本,还没到安装环节。后面有具体的安装教程,别着急哟~)
- 确定要安装的显卡驱动版本——博主的笔记本电脑是2018年购买的联想拯救者R720,显卡型号是NVIDIA GeForce GTX 1050 Ti,在官方下载地址可以查询并下载显卡驱动。博主是2021年配置的CUDA,因此使用的是当时最新的470.14版本显卡驱动。大家可以选择更新的版本。

- 确定要安装的CUDA版本——在2022年8月3日查表可知,470.14的NVIDIA显卡驱动应当兼容CUDA 11.0到CUDA 11.7的所有版本。但是在470.14驱动发布的当年,最新的CUDA版本也只开发到了CUDA 11.3,2021年的博主只能安装CUDA 11.3。大家可以选择表格中记录的更新的版本。⚠️注意:安装最新的CUDA并不一定是个好主意,因为有可能其他上层应用还未来得及对其进行适配。比如在2022年8月3日,CUDA已经发布到了11.7版本,但PyTorch最高仍然只支持CUDA 11.6。
 安装完显卡驱动,在命令行执行nvidia-smi.exe,可以查看驱动支持的 最高CUDA版本。上图中显示的是 CUDA Version: 11.3,表示该驱动开发出来时最高支持CUDA 11.3
安装完显卡驱动,在命令行执行nvidia-smi.exe,可以查看驱动支持的 最高CUDA版本。上图中显示的是 CUDA Version: 11.3,表示该驱动开发出来时最高支持CUDA 11.3
 但在NVIDIA最新公布的兼容表中,470.14可以最高兼容到CUDA 11.7。可能的原因是当驱动470.14发布时,CUDA最高版本只开发到11.3,所以nvidia-smi里面显示的最高兼容版本只到11.3
但在NVIDIA最新公布的兼容表中,470.14可以最高兼容到CUDA 11.7。可能的原因是当驱动470.14发布时,CUDA最高版本只开发到11.3,所以nvidia-smi里面显示的最高兼容版本只到11.3
- 确定要安装的cuDNN版本——在2022年8月3日查表可知,cuDNN 8.4.1可以兼容所有CUDA 11的版本(GPU型号的算力要不低于3.5)。2021年博主配置环境的时候,cuDNN最新才发布到8.2.1,因此当时博主使用了cuDNN 8.2.1。大家可以选择表格中写的更新的版本。

- 确定要安装的PyTorch版本——(不需要PyTorch的话可以不看)在2022年8月3日查表可知,PyTorch1.12.0有三种支持CUDA的版本,分别最高支持到CUDA 10.2 / CUDA 11.3 / CUDA 11.6。由于博主的CUDA版本是11.3,我使用更接近的最高支持CUDA 11.3的PyTorch。大家可以选择更新的版本。

总结下来,博主的CUDA配置清单如下,大家也可以整理一下自己要安装的软件清单:
| 物理显卡型号 | NVIDIA GeForce GTX 1050 Ti |
| 显卡驱动版本号 | 470.14 |
| CUDA版本号 | 11.3 |
| cuDNN版本号 | 8.2.1 |
| PyTorch版本号 (不用的话可以不装) |
1.12.0-gpu-cuda113 |
明确了要安装软件的版本,接下来就可以正式进入下载安装环节啦~
安装Windows上的NVIDIA GPU驱动
按照NVIDIA给出的教程,首先需要安装Windows平台上的NVIDIA显卡驱动。
⚠️注意:
- 如果Windows系统已经安装了NVIDIA显卡驱动,据不可靠消息来源报道,显卡驱动版本在455.41以上的话,应当可以支持此功能(如果后面运行CUDA失败,还请卸载CUDA,然后更新显卡驱动到最新)。
- 如果已经有NVIDIA显卡驱动,可以按Windows键+S键,搜索系统里安装的NVIDIA的显卡管理程序(如GeForce Experience,它在任务栏也会显示图标),通过它升级显卡驱动。
如果系统里没有装过NVIDIA显卡驱动,或想要手动更新的话,请在官方下载地址下载安装最新的、符合自己显卡型号的WIndows显卡驱动(“操作系统”一定要选择Windows,而不是Linux)。举个例子,假如电脑显卡是GTX1050ti(笔记本版),操作系统是Windows 11,下图是应该选择的显卡驱动配置:

配置完毕后,点击“搜索”,查找最新的显卡驱动。搜索出结果后,点击“下载”,会弹出文件下载窗口。

如果觉得浏览器下载太慢,可以复制下载链接到迅雷或者其他下载器:

下载完毕后,运行安装程序。一般来说,按照推荐选项安装即可。 安装完毕后,重启电脑。
 安装过程,图片来源于网络
安装过程,图片来源于网络
安装完毕后,可以在命令行执行nvidia-smi.exe检查显卡驱动信息,正常输出则安装正确。如果无法直接找到这个可执行文件,可以在命令行输入它的(默认)安装位置。
'C:\Program Files\NVIDIA Corporation\NVSMI\nvidia-smi.exe'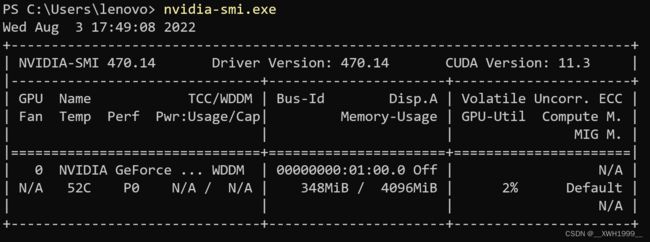
WSL2 Ubuntu安装NVIDIA CUDA工具包
当我们在Windows上安装完NVIDIA显卡驱动后,下一步就是安装CUDA的核心本体——CUDA工具包。CUDA工具包囊括了CUDA的相关工具库文件和工具程序,如nvcc编译器等。拥有了CUDA工具包,我们就可以在程序代码中嵌入CUDA语句来方便地使用GPU,然后通过CUDA的编译器将代码翻译成可执行文件。本节主要参考来源:CUDA on WSL :: CUDA Toolkit Documentation
⚠️注意:鉴于平台限制,WSL2下的CUDA工具包目前仍有少数功能没有得到完全支持,如CUDA代码的调试器等,详细请见文档。
当你进行到这一步时,应该已经清楚自己需要安装的CUDA版本了,我们把要安装的CUDA版本号记作:
. CUDA_MAJOR是CUDA的大版本号,CUDA_MINOR是CUDA的小版本号
假如说我们要安装CUDA 11.6,那么CUDA_MAJOR=11,CUDA_MINOR=6
打开WSL2 Ubuntu 20.04,执行如下语句来获取NVIDIA CUDA的官方本地安装包仓库。首先,我们根据自己要装的CUDA版本号,依次定义这两个临时环境变量:
export CUDA_MAJOR=大版本号,如11
export CUDA_MINOR=小版本号,如6由于最近几个月NVIDIA更新了自己apt源的GPG密钥,我们需要先删除它原来过时的密钥:
sudo apt-key del 7fa2af80接着,下载并安装NVIDIA CUDA的本地安装包仓库:
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/${CUDA_MAJOR}.${CUDA_MINOR}.0/local_installers/cuda-repo-wsl-ubuntu-${CUDA_MAJOR}-${CUDA_MINOR}-local_${CUDA_MAJOR}.${CUDA_MINOR}.0-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-${CUDA_MAJOR}-${CUDA_MINOR}-local_${CUDA_MAJOR}.${CUDA_MINOR}.0-1_amd64.deb建议:其中第三行命令用来下载安装包仓库本体,如果觉得下载太慢,可以不用wget而用axel命令进行多线程下载(需要先sudo apt install axel)。或是执行以下命令获取下载链接,然后复制链接到Windows中用迅雷等下载器下载:
echo "https://developer.download.nvidia.com/compute/cuda/${CUDA_MAJOR}.${CUDA_MINOR}.0/local_installers/cuda-repo-wsl-ubuntu-${CUDA_MAJOR}-${CUDA_MINOR}-local_${CUDA_MAJOR}.${CUDA_MINOR}.0-1_amd64.deb"
此时,包管理器会输出很多安装时的日志信息。当安装包仓库安装成功时,输出文字的最后几行应当会有类似下面的语句(也可能和下面不同,但一定里面涉及到“key”这些关键词)。这是包管理器建议你执行的命令,用于添加NVIDIA apt源的新密钥,我们复制并执行它。
sudo apt-key add 一些路径信息/7fa2af80.pub成功执行后,更新apt源,让apt能找到我们刚刚安装的CUDA本地安装包仓库。最后我们从本地安装包仓库里获取并安装CUDA工具包:
sudo apt update
sudo apt install cuda-${CUDA_MAJOR}-${CUDA_MINOR}安装完成后,CUDA应该已经安装在/usr/local/cuda/目录下了,我们可以查看:
ls /usr/local/cuda
⚠️注意:
- /usr/local/cuda/bin/目录下存放着CUDA相关的二进制工具程序,如CUDA编译器nvcc。下面我们会将这个目录加入系统PATH变量中。
- /usr/local/cuda/include/目录下存放着CUDA库的头文件。如果将来在编译CUDA相关代码时报错找不到头文件,那需要手动指定在该目录下搜索头文件。
- /usr/local/cuda/lib64/目录下存放着CUDA的工具库,下面我们会将其加入GCC库搜寻目录变量LD_LIBRARY_PATH中。
- 此外,/usr/lib/wsl/lib/目录下还存放着libcuda.so等库,下面我们会将其加入GCC库搜寻目录变量LD_LIBRARY_PATH中。
我们把该目录下的bin/目录、lib64/目录以及/usr/lib/wsl/lib/目录添加到相应的系统环境变量中去 (如果你是从WSL2安装多个CUDA版本过来的,并且之前已经做过这一步的话,这一步就不用再做一遍了):
sudo touch /etc/profile.d/cuda.sh
echo 'export PATH=/usr/local/cuda/bin/:$PATH' | sudo tee -a /etc/profile.d/cuda.sh
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64/:/usr/lib/wsl/lib/:$LD_LIBRARY_PATH' | sudo tee -a /etc/profile.d/cuda.sh
关闭当前WSL2命令行,打开一个新的WSL2命令行。查询nvcc编译器版本以检查CUDA工具包是否正常安装:
nvcc -V
我们还可以运行一个使用GPU加速的向量加法例程:
/usr/local/cuda/extras/demo_suite/vectorAdd
至此,CUDA软件栈的大部分安装工作已经完成,你可以将安装过程中下载的本地安装包仓库cuda-repo-wsl-ubuntu-*.deb文件删除或移走了。如果你不需要安装cuDNN,那么恭喜你,安装过程到此就圆满结束了。如果需要安装cuDNN,请继续下一步~
附:
- 如果需要卸载CUDA工具包,依次执行:
# 卸载CUDA工具包,版本号请手动输入,最终的包名形如cuda-11-3 sudo apt remove cuda-<想要卸载的CUDA的大版本号>-<想要卸载的CUDA的小版本号> # 删除CUDA相关环境变量 sudo rm -f /etc/profile.d/cuda.sh- 如果需要安装多个不同版本的CUDA工具包,然后切换当前系统使用的CUDA工具包版本,可以进行如下操作(参考来源):
# 从头过一遍本节CUDA工具包的安装流程,不过这次CUDA版本号得变成你想要的另一个版本号 ... # 查找当前系统所有的CUDA包 sudo update-alternatives --query cuda # 设置当前系统默认使用的CUDA包 sudo update-alternatives --config cuda
WSL2 Ubuntu安装NVIDIA cuDNN深度学习库
cuDNN是NVIDIA公司推出的、基于CUDA的深度神经网络库。cuDNN内置有很多包装好的、嵌入了CUDA代码的深度学习算法,可以方便地让我们享受带有GPU加速的深度学习过程。 cuDNN的安装和CUDA类似,我们基于NVIDIA的官方文档进行讲解:Installation Guide :: NVIDIA Deep Learning cuDNN Documentation
我们已经装好了CUDA,并且明确了cuDNN要安装的版本号,这里我们以8.4.1为例。首先访问NVIDIA cuDNN的下载网站,找到你要安装的版本,点进去。

我们以8.4.1为例, 一直进入到如下选择界面,选择你希望cuDNN兼容的最高CUDA版本号。我们这里选择CUDA11.6:

根据WSL2 Ubuntu的环境选择要下载的cuDNN安装包仓库。我的WSL2 Ubuntu版本是20.04,电脑架构是x86_64(即amd64)。和下载CUDA安装包仓库一样,可以点击链接直接用浏览器下载,也可以复制链接用Windows迅雷下载,或是用WSL2 Ubuntu里的wget/axel下载。

下载完毕后,安装cuDNN安装包仓库:
sudo dpkg -i <刚刚下载的安装包仓库的文件>和CUDA安装过程类似,cuDNN安装包仓库安装完毕后,最后几行会输出一个添加密钥的命令,类似下面。我们执行输出的那个命令:
sudo cp /var/cudnn-local-repo-*/cudnn-local-*-keyring.gpg /usr/share/keyrings/更新apt源,让apt包管理器能够找到刚刚安装的cuDNN安装包仓库:
sudo apt update下面准备安装cuDNN,先查找一下cuDNN安装包仓库中包含的cuDNN深度学习库有哪些版本:
sudo apt list libcudnn*
⚠️注意:
- libcudnn8包只包含cuDNN的运行时库和头文件。如果你只需要用cuDNN,这个包就够了。
- libcudnn8-dev包除了包含cuDNN的运行时库和头文件,还额外包含cuDNN的开发时库。如果你需要开发cuDNN本身,那请使用这个包。
- libcudnn8-samples包只包含cuDNN的示例代码和文档,不包含任何cuDNN库。只安装这个包是无法使用cuDNN的。
安装cuDNN库。如果你担心未来会用到cuDNN的开发时环境、示例或文档,可以安装libcudnn8-dev与libcudnn8-samples包。
sudo apt install libcudnn8-dev libcudnn8-samples⚠️注意:按照此法安装的cuDNN库相关文件存放位置如下
- /usr/include/目录:Linux系统的头文件存放地之一。cuDNN相关的头文件也存放其中,文件名以cudnn开头。
- /usr/src/cudnn_samples_v8/目录:存放cuDNN8相关的示例源代码。
- /usr/lib/x86_64-linux-gnu/目录:Linux系统存放x86_64架构下库文件的地方。x86_64 cuDNN相关的库文件也存放其中,文件名以libcudnn开头。
简单地检查一下cuDNN头文件是否安装到位,如果能输出cuDNN版本,则头文件安装成功:
cat /usr/include/cudnn_version.h | grep CUDNN_
附:如果乐意的话,还可以尝试编译一下cuDNN的示例代码。如果能成功编译并运行,代表你的CUDA工具链和cuDNN库全部正常工作。
# 复制示例代码到$HOME目录下,然后进入该目录 cp -r /usr/src/cudnn_samples_v8/ ~ cd ~/cudnn_samples_v8/ # 试着编译一份卷积运算的示例代码 cd conv_sample/ # 用apt安装的cuDNN头文件和库目录位置与Makefile中给定的默认位置不同, # 因此我们先手动指定位置后再make CUDNN_INCLUDE_PATH=/usr/include/ CUDNN_LIB_PATH=/usr/lib/x86_64-linux-gnu/ make # 编译完成后,执行编译出的二进制文件,进行卷积运算测试 ./conv_sample # 运行更多的卷积运算测试案例 source run_conv_sample.sh

至此,WSL2 Ubuntu上的CUDA和cuDNN环境都已安装完毕,可以将之前下载的安装包仓库deb文件都删除了。
快用PyTorch、TensorFlow试试看吧
WSL2 Ubuntu安装PyTorch机器学习框架
PyTorch是一个开源的机器学习框架,为用户提供机器学习算法从原型研究到生产部署的更快体验。官方网站:PyTorch
我们以安装Python的PyTorch包为例,安装Python3带CUDA 11.6支持的PyTorch包。首先,为了和系统的Python环境隔离,我们需要使用虚拟环境管理器(如conda、virtualenv、venv等),这里我们首先使用pip3安装virtualenv作为虚拟环境管理器:
pip3 install virtualenv建议:如果觉得pip3包管理器从官方源下载包速度太慢,可以添加-i参数来使用国内的镜像源,如中科大源:
pip3 install virtualenv -i https://mirrors.ustc.edu.cn/pypi/web/simple
创建一个虚拟环境,将我们要安装的包和外界环境隔离。这里我们把创建的环境取名为torch-env:
virtualenv torch-env创建完毕后,当前目录下会多出一个torch-env文件夹。我们进入文件夹,激活虚拟环境:
cd torch-env
source bin/activate虚拟环境激活成功后,命令行最前面会出现当前的虚拟环境名称,代表你接下来python、pip相关的命令都将在自动虚拟环境中执行,不会影响外界Python环境:
![]()
假设我们已经安装了CUDA 11.6和对应的cuDNN,那么我们应当在PyTorch官网准备好要安装的PyTorch版本——举个例子,博主这里使用2022年8月9号时查询到的PyTorch 1.12.0稳定版,Linux平台,使用pip包管理器安装,最高支持CUDA11.6:

在官网的配置表中选好相应的选项后,复制表格中最下面的命令到WSL2 Ubuntu命令行(已经激活虚拟环境)执行,安装带CUDA 11.6支持的PyTorch和相关Python包。按照博主的配置,应该是:
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116建议:如果觉得pip3包管理器从pytorch源下载太慢,可以手动复制pip3下载时显示的下载链接,然后使用各种下载器下载whl轮子文件。下载完毕后用pip3命令安装:
pip3 install
安装完毕后,执行以下命令,测试PyTorch能否通过CUDA访问本机的GPU设备。如果可以的话,命令行应当输出显卡的全名:
python3 -c 'import torch; print(torch.cuda.get_device_name(0))'在PyTorch能正常访问GPU的情况下,尝试让PyTorch通过CUDA生成一个1024x1024的随机数大张量:
python3 -c 'import torch; print(torch.rand(1024,1024).cuda())'如需退出当前虚拟环境,执行命令:
deactivate执行后,之前虚拟环境中安装的包将不再可被pip、python直接访问(因为你现在在虚拟环境之外了)。
附:
如果需要了解更多PyTorch相关的知识,可以访问项目的文档:
Resources | PyTorch
https://pytorch.org/resources/还有一份非常详尽的,国人制作,但适用PyTorch版本不明(博主没找到……)的文档:
PyTorch中文文档 (pytorch-cn.readthedocs.io)
Linux字符终端基础设施
虽然我们可以在Windows中以窗口的方式查看WSL2上程序的图形交互界面,但这毕竟没有原生的Linux图形界面用的舒服,因此我们大多数时候还是通过字符终端(黑底白字的那玩意儿)来使用WSL。那么,如何让只能显示字符的终端用起来有接近图形界面的体验呢?本章介绍的一些软件可以帮助实现这种效果,不仅适用于WSL,而且适用于大部分Linux设备。
几个基本概念
参考:
What is the difference between Terminal, Console, Shell, and Command Line? - Ask Ubuntu https://askubuntu.com/questions/506510/what-is-the-difference-between-terminal-console-shell-and-command-line
https://askubuntu.com/questions/506510/what-is-the-difference-between-terminal-console-shell-and-command-line
Difference between Terminal, Console, Shell, and Command Line - GeeksforGeekshttps://www.geeksforgeeks.org/difference-between-terminal-console-shell-and-command-line/
本节博主打算先厘清一些容易混淆的概念。不过在此之前,让我们先了解一些背景知识……
由于科技的发展,现在的电脑和过去的电脑差别巨大——现在的电脑轻巧又便宜,可以做到人手一台。过去的电脑昂贵而庞大,通常只有企业可以负担得起。因此过去的人使用电脑也非常“节约”,通常是许多“屏幕和键盘”连接到同一台电脑,多个用户操作同一台电脑。
显然,在设备的布置上,由多个用户操作的“过去的电脑”要更加复杂,因此也诞生了许多相关的术语来描述这些复杂的不同物品。但如今的电脑通常只由一人操作,只需要一套“显示器、键盘、鼠标”,所以过去的那些术语在现在的电脑上发生了“融合”——一些在过去指代不同东西的术语,在如今可能指代着非常相似的物品。
所以作为使用着现代电脑的现代程序员,在理解下述概念时可能发生混淆,我们必须站在当年的环境下,才能更好地理解这些术语原本的意思。
Terminal 终端
本意指一套连接着电脑的“文字输入输出设备”——终端是用来和电脑交互的物理设备,且交互的内容是纯文本字符。在过去,终端的标配是“显示器+键盘”,然后设备通过电缆连接电脑主机。电脑主机是电缆的起点,终端设备(即显示器键盘组合)是电缆的终点,所以把这些设备叫做“终端”。由于当时的电脑有很多人使用,所以一台电脑可以连出很多终端。
 过去的物理终端
过去的物理终端
但是在如今,已经几乎见不到真正的“物理意义上”的终端设备在售卖了。现在的显示器是通过VGA/HDMI等多媒体传输协议和电脑显卡交流,现在的键盘也走的是USB协议,这俩关键设备都不再使用纯文本和电脑主机交互了。
因此,如今的终端更多指的是“终端模拟器”——这是一类软件,用来模拟过去的真实终端的纯文字交互过程和显示效果。常见的终端模拟器有Windows Terminal、Command prompt、guake、gnome-terminal、terminator等。
 如今的终端模拟器,Windows自带的命令提示符就是一个典型的终端模拟器
如今的终端模拟器,Windows自带的命令提示符就是一个典型的终端模拟器
Console 控制台
控制台的本意就是它的字面意思——一个“台面”,这个“台面”上安装着很多零件,用于“控制”某台机器或电子设备。遵循这个原意,console一词出现在英语的很多地方。比如,音乐领域中”DJ控制器“的面板叫做console;带控制按钮、摇杆和屏幕的任天堂Switch等游戏掌机也可以叫做console。
 DJ控制台
DJ控制台
 Xbox、Switch、Wii这些游戏机都可以叫做console
Xbox、Switch、Wii这些游戏机都可以叫做console
在计算机领域,控制台代表一个特殊的终端,它是与计算机直接相连的主终端,用来直接控制计算机。过去的电脑会连接很多终端,但其中一定有个和计算机直接相连的,直接用来控制计算机的主终端,这个终端就叫“控制台”。
对于现代的电脑来说,已经不再配备物理的终端和控制台。但Ubuntu等系统保留了一系列所谓的“虚拟控制台”(类似于前面讲的“终端模拟器”)——当用户按下Ctrl-Alt-F1时,系统会切换到第一个虚拟控制台;用户按下Ctrl-Alt-F2时,会切换到第二个控制台……一共有六个虚拟控制台,操作方式依此类推。按下Ctrl-Alt-F7后,退出控制台模式,回到图形化的桌面。
 Ubuntu的一号虚拟控制台,控制台模式下只能用纯文本交互
Ubuntu的一号虚拟控制台,控制台模式下只能用纯文本交互
Command Line 命令行
真的没想到,命令行的本意居然是字面意思——在终端运行的某个程序中,允许你输入“命令”的那一“行”,叫做“命令行” 。在终端的命令行输入命令后,按下回车即可运行命令。
此外,“命令行”也可以引申为一种程序与用户的交互方式,即“以命令行的方式交互”——如果我设计了一个“以命令行方式交互”的程序,用户只需要在命令行按照程序说明输入命令,再按下回车,我的程序就会按照用户的命令运行,最后在终端中以文字的形式打印出结果。the-art-of-command-line/README-zh.md at master · jlevy/the-art-of-command-line (github.com)https://github.com/jlevy/the-art-of-command-line/blob/master/README-zh.md
 图片展示了一个运行着Shell程序的终端。在上图中,终端的第一行是命令行
图片展示了一个运行着Shell程序的终端。在上图中,终端的第一行是命令行
 常见的这个图标,其实描绘的就是一个命令行。>后开始输入命令,_是当前光标所在位置
常见的这个图标,其实描绘的就是一个命令行。>后开始输入命令,_是当前光标所在位置
Shell
在功能定位上,Shell是用户与操作系统之间的接口。Shell直接翻译过来是“外壳”,因此Shell的本意是操作系统内核的“外壳”——不管系统内核的内部实现有多么复杂,只要经过“外壳”的包装,用户就可以很轻松地通过“外壳”申请调用系统内核的功能。
什么是系统调用?_温逗死的博客-CSDN博客_系统调用01、 系统调用是什么系统内核通过包装一些能够实现特定功能的特殊硬件指令和硬件状态,即为内核函数,通过一组称为系统调用(system call)的接口呈现给用户,为系统调用而封装出来的API也达数百个。为了保护设备,操作系统不可能让所有的程序都能轻松地访问到任何的文件,因此进程在系统上的运行分为2个级别:(1) 用户态(user mode):用户态运行的进程可以直接读取用户程序的数据;(2) 系统态(kernel mode):系统态运行的程序可以访问计算机的任何资源,不受限制;诸如一些修改寄存器内容https://blog.csdn.net/qq_43142509/article/details/124600228操作系统是管理计算机硬件与软件资源的计算机程序。为了保护设备,操作系统不可能让所有的程序都能轻松地访问到任何的文件,因此进程在系统上的运行分为2个级别:
- 用户态(user mode):用户态运行的进程可以直接读取用户程序的数据;
- 系统态(kernel mode):系统态运行的程序可以访问计算机的任何资源,不受限制;诸如一些修改寄存器内容的命令,比如次磁盘的IO操作、访问物理页内存、访问网络上的数据包
平常我们的进程几乎都是用户态,读取用户数据,当涉及到系统级别资源的操作(例如文件管理、进程控制、内存管理等)的时候,就要用到系统调用了。
 Linux系统的结构图。Shell包围着内核(Kernel),就像是内核的“外壳”
Linux系统的结构图。Shell包围着内核(Kernel),就像是内核的“外壳”
在具体的实现上,Shell是一个解释器软件,为用户提供了一个可以交互式运行指令的“命令行”。在Shell提供的命令行中,用户可以轻松地使用“包装好的命令”(通过系统调用)来完成“操纵文件”“执行程序”等操作。
提示:
- Shell script是一种脚本编程语言(Bash script、Zsh script等是它的变种,或者叫“方言”)。Shell script语言内置了一些典型操作,如操纵文件、执行程序和打印文本等。这些操作背后隐藏着一堆复杂的系统调用,可是对于Shell script用户来说,只是写一句话的事而已——“外壳”将系统内核里面的复杂细节隐藏了。
- Shell是Shell script语言的解释器,用于解释并执行Shell script语句(Bash、Zsh等同理)。Shell解释器是一个“命令行交互”软件。就像Python解释器那样,Shell解释器既可以接受写好的脚本文件,也可以在命令行中一句一句地“交互式执行”用户输入的Shell script语句。
Shell、Bash、Python3三种解释器
通常情况下,Shell交互式解释器是我们从终端登录进Linux系统后第一个看到的程序,我们可以在Shell解释器的命令行中输入Shell script语句(这就是我们常说的“命令”),来完成想要的操作。
附:
如果想要知道当前终端中,正在运行的解释器的具体类别,可以运行以下命令:
/bin/ps -p $$
可以看出,使用默认配置访问WSL2 Ubuntu 20.04终端时,终端默认运行的其实是Bash解释器。Bash解释器是Shell解释器的加强版扩展;Bash script是Shell script语言的一个方言。
为方便起见,除非特别说明,下面我们不再区分Shell和Bash,统称为Shell。
bash-handbook/README.md at master · denysdovhan/bash-handbook (github.com)

程序与用户交互的几种方式
CLI 命令行接口
这种交互方式多用于在终端运行的程序,CLI程序通过命令行与用户进行交互,全称Command Line Interface。用户只能使用键盘打字输入命令,不能使用鼠标。Linux Shell/Bash中大部分的内置命令都属于CLI程序。
TUI 基于文字的用户接口
这种交互方式多用于在终端运行的程序,TUI程序使用纯字符构建出一个粗糙的图形化用户界面,全称Text-based User Interface。用户可以用键盘和鼠标进行界面交互。著名的Vim和Emacs就属于TUI程序。
GUI 图形用户接口
GUI程序采用图形方式渲染用户操作界面,画面精美,全称Graphical User Interface。用户可以直接用鼠标点击按钮或用键盘进行交互。大部分消费级桌面应用程序都是GUI程序。
WebUI 网络用户接口
WebUI程序多运行在浏览器中,以网页的方式呈现用户界面,全称Web User Interface。此类型有时也一并归为GUI。WebUI的程序可以渲染出和GUI程序同样精美的画面,并可以跨平台使用,只要机器上安装有现代主流浏览器,就可以运行这个网页应用。微软的Office系列和Vscode都有着相应的网页应用。
文本编辑器:Vim/Neovim
Vim是什么
Vim是一款高度可定制化的文本编辑器。Vim的特点在于:
- Vim的有着自己独特的操作方式,使用手感和其他文本编辑器都不同。Vim有三种最重要的操作模式:
普通模式
该模式下键盘的输入都被认为是按下相应的键盘快捷键,而不是直接输入文本。
个人认为这是Vim和一般编辑器最不同的地方,相当于Vim把所有需要快捷键的操作都集中起来,放在了一个统一的模式下。
插入模式
该模式下键盘的输入都被认为是在文档中输入文本。
这也是一般文本编辑器的操作逻辑。
命令模式
该模式下可以键入命令脚本,然后Vim会执行你键入的命令,操作体验类似于交互式命令行。
这个模式使得Vim比一般的文本编辑器更加灵活,只要我们写好命令,Vim可以完成几乎任何想让它做的事。Vim使用自己的脚本语言Vimscript,我们也可以用它来编写自己的快捷功能函数。
- Vim是高度可定制化的。Vim有着自己的配置文件(其实这个配置文件就是Vim的启动脚本,每次Vim启动时都会自动执行脚本里的命令),我们可以私人订制自己的Vim配置。此外,和VSCode、Notepad++类似,Vim也拥有着完善的插件社区,我们可以下载别人写好的插件,或是用Vimscript糅合其他语言编写自己的插件。没有受过配置的Vim只能作为文本编辑器使用,而经过良好配置和插件加持的Vim则可以媲美IDE。
Vim的优势
就博主个人体验,比起VSCode、Notepad++等文本编辑器来说,Vim的优势在于:
- 只要你能访问Linux的字符终端,你就能使用Vim。Vim是一个在Linux上本地运行的TUI字符终端交互程序(虽然Vim也有GUI版本),只要程序员的电脑能够登录远程Linux设备的Shell/Bash(无论是通过SSH、Telnet、Mosh、串口等等来连接),程序员就可以远程使用Linux上的Vim。此外,正由于Vim是个纯字符程序,它不需要像GUI程序那样渲染界面,因此Vim的打开速度也非常快。
- Vim可以在几乎所有架构的Linux系统上运行。时下流行的一种远程开发解决方案是——在程序员电脑上使用VSCode+SSH插件远程访问Linux服务器进行代码开发与调试。但VSCode+SSH插件这套组合并不适配所有的远程Linux架构,如armv6架构。
- Vim的定位是文本编辑器,但也能做更多事。你可以在Vim的命令模式下直接运行Vimscript脚本。Vimscript是图灵完备的脚本语言,配合上Shell script,你可以用Vim做几乎任何事情。
博主的Vim/Neovim配置
下面的链接里是博主工作时摸鱼积累出来的一套Vim、Neovim配置。
这套配置中,博主对Vim的定位是增强版的文本编辑器,而非IDE;Neovim可以承担IDE的一部分功能,但也不能完全取代IDE。
NewComer00/my-vimrc: 我的Vim和Neovim配置 | My Vim & Neovim config (github.com)https://github.com/NewComer00/my-vimrc/
- 调教好的Vim:

- 调教好的Neovim:

图片展示器:TerminalImageViewer
字符终端,正如它的名字所描述的,只能显示字符文本,无法显示图片等非字符的内容。我们日常通过SSH远程连接Linux Shell的时候,如何快速浏览Linux中的图片呢?
TerminalImageViewer是一个让字符终端也能“显示”图片的神奇程序,原理是使用一系列带颜色的特殊字符来“拼接”出原始图片,程序最终输出的“图片”其实只是一长串字符而已。
项目地址:
stefanhaustein/TerminalImageViewer: Small C++ program to display images in a (modern) terminal using RGB ANSI codes and unicode block graphics characters (github.com)https://github.com/stefanhaustein/TerminalImageViewer 编译安装教程;使用方法;常见问题解决;使用效果:

基于gdb的代码调试器
gdb是GCC编译工具集合内自带的,纯命令行交互式代码调试器。gdb可以调试以下语言编写的程序:C, C++, D, Go, Objective-C, Fortran, OpenCL C, Pascal, Rust, assembly等等。
准备待调试的代码
我们以调试如下C++代码为例,为大家介绍几种基于gdb的代码调试器。 代码文件命名为hello.cpp:
#include
#include
int main(void) {
std::string welcome_words = "Hello World!";
std::cout << welcome_words << std::endl;
} 使用g++命令编译hello.cpp,生成调试符号,并将输出文件命名为hello.out:
g++ hello.cpp -g -o hello.out尝试运行当前目录下的hello.out可执行文件,终端命令行应当输出“Hello World!”字样:

CLI式代码调试器:gdb
gdb是GCC编译工具集合内自带的,纯命令行交互式代码调试器。输入以下命令即可对当前目录下的hello.out可执行文件进行调试:
gdb hello.out一些常用的gdb命令行的调试命令:
| gdb调试命令 | 命令缩写 | 命令功能 |
| help <命令名称或缩写> | h | 查询指定命令的帮助文档。 |
| list | l(小写的L) | 列举当前行附近10行的内容。多次执行时,会不断向后展示代码。 |
| break <源代码文件名:行号或函数名> break <行号或函数名> |
b | 对指定代码文件的指定代码行或函数打上断点。 若仅指定行号或函数名,则默认为list所展示的当前源代码文件。 |
| run | r | 从头开始运行代码。 |
| print <变量或表达式> | p | 打印给定变量或表达式的值。 |
| next | n | 单步跳过。 |
| step | s | 单步进入。 |
| quit | q | 退出gdb调试器。 |
| ! |
! | 运行一个Shell命令。 |

gdb调试命令行的命令参照表如下:
GDB Cheat Sheet (darkdust.net)https://darkdust.net/files/GDB%20Cheat%20Sheet.pdf
提示:
gdb是允许用户进行个性化配置的,所以Github上也有很多极客分享自己的“黑科技”配置。某些配置可以将CLI的gdb魔改成TUI的模样~
cyrus-and/gdb-dashboard: Modular visual interface for GDB in Python (github.com)
longld/peda: PEDA - Python Exploit Development Assistance for GDB (github.com)
对于搞软件安全方面的小伙伴来说,gdb-peda应该是一件趁手的工具。

TUI式代码调试器:gdb --tui 与 cgdb
觉得gdb的纯命令行式交互太麻烦、不直观?觉得gdb在调试的时候连代码都默认看不到?没事,下面两个基于gdb的改进版调试工具引入了字符交互界面,可以让我们在调试代码的同时也能看到代码源文件。
gdb --tui
这是gdb自带的TUI字符交互模式,在原始gdb命令后加上--tui参数即可进入gdb的字符交互模式:
gdb hello.out --tui此时屏幕被分为上下两部分。按回车后即可开始调试,上半屏幕显示当前源代码,下半屏幕为gdb命令行。
该模式下,键盘的方向键或鼠标滚轮用来在上半屏幕浏览代码,Ctrl+P和Ctrl+N键用于上翻/下翻gdb命令行历史记录。
⚠️注意:
gdb的TUI模式下,若调试代码打印输出大量文字,则gdb的窗口可能会出现错位。此时按下Ctrl+L可刷新窗口。

cgdb
cgdbhttps://cgdb.github.io/cgdb是一个轻量级的、基于TUI的gdb调试接口。除了标准的gdb调试命令行之外,cgdb也划分出来一个窗口,用于在调试时显示程序源代码。此外,cgdb的大部分键位设置都遵循Vim的习惯,因此对Vim使用者非常友好。
我们可以通过apt等包管理器直接安装cgdb:
sudo apt install cgdbcgdb和gdb的用法类似,输入以下命令即可对当前目录下的hello.out可执行文件进行调试:
cgdb hello.out
如上图所示,cgdb的用户界面从上到下一共由三部分组成:
- 源代码窗口(Source Window):交互界面上半部分的窗口,用于浏览程序源代码,也可以展示断点、下一步要执行的代码等信息。
- 状态栏(Status Bar):夹在上下两个窗口之间,用于展示一些提示信息,如当前文件位置、当前输入命令和错误提示等。
- GDB窗口(GDB Window):交互界面下半部分的窗口,用户通过这个窗口和gdb代码调试器交互,进行代码调试。
和Vim类似,cgdb也拥有若干个不同的模式,用户在不同的模式下可以进行不同的操作:
| 模式 | 功能介绍 | 快捷键 |
| CGDB模式 (代码浏览模式) |
CGDB模式下,用户可以在源代码窗口中浏览代码,操作手感和Vim相似,兼容Vim的hjkl方向键、/键搜索等功能。 ● CGDB模式下,按“i”可切换至GDB命令模式;按“s”可切换至GDB翻页模式;按“o”可切换至文件窗口模式。 ● 任何模式下,按Esc键都可回到CGDB模式。 |
文档 |
| GDB模式 (包含“命令模式”和“翻页模式”) |
GDB命令模式下,用户可以直接通过gdb命令行进行代码调试,使用体验和纯gdb相同。 ● GDB命令模式下,按PageUp键可进入翻页模式。 GDB翻页模式下,用户可以浏览gdb的历史命令和历史输出。该模式使用Vim系的hjkl方向键控制光标移动,并同样支持/键搜索。 ● GDB翻页模式下,按回车键或“q”可回到GDB命令模式。 |
文档 |
| File Dialog模式 (文件窗口模式) |
文件窗口模式下,用户可以从弹出的窗口中选择相关的代码文件并打开。该模式同样兼容Vim的方向键和搜索键。 ● 文件窗口模式下,按“q”或Esc键可回到CGDB模式。 |
文档 |
cgdb是个功能强大的TUI调试工具,但比较难学。如果你计算机的物理资源比较充裕,也可以尝试下面这款基于网页的gdb调试器。
WebUI式代码调试器:gdbgui
gdbguihttps://www.gdbgui.com/gdbgui是一个基于浏览器的gdb调试器前端,能够可视化地对C、C++、Go和Rust等程序进行调试。
如果你在自己的电脑上(有浏览器),需要以最方便的方式,通过图形化、可视化的界面,对远程Linux机器进行程序调试……博主个人认为,除了已经搭建好环境VSCode之外,最方便的可视化调试软件非gdbgui莫属了~
gdbgui是个Python的包,平时托管在PyPi平台上。按照官网文档的建议,我们使用pipx包管理器安装gdbgui,因为pipx可以为Python包提供原生的隔离环境(不需要手动创建和激活虚拟环境了)。首先安装pipx,并将用户安装目录添加到默认搜寻路径:
python3 -m pip install --user pipx
python3 -m userpath append ~/.local/bin建议:如果觉得第一句pip包管理器从官方源下载包速度太慢,可以添加-i参数来使用国内的镜像源,如中科大源:
python3 -m pip install --user pipx -i https://mirrors.ustc.edu.cn/pypi/web/simple
关闭当前Shell命令行,并开启一个新的Shell命令行, 使得上述改动生效。然后使用pipx包管理器下载gdbgui,如果嫌慢仍然可以在后面添加-i参数:
pipx install gdbgui下载完毕后,尝试运行gdbgui:
gdbgui此时gdbgui将开启一个网页服务器,使用浏览器来访问:


第一次运行时会有教程在页面右上角弹出,跟着教程走就行啦~

命令行Markdown渲染器
charmbracelet/glow: Render markdown on the CLI, with pizzazz! (github.com) https://github.com/charmbracelet/glow不需要任何图形界面,在终端命令行直接用字符渲染Markdown!
https://github.com/charmbracelet/glow不需要任何图形界面,在终端命令行直接用字符渲染Markdown!
