Python语言中 reshape排序参数order详解
前言
使用Pyton时发现网上关于reshape方法的文章一般都比较简单,尤其是关于排序的问题很少涉及或讲解的不清楚,所以特整理了reshape的用法,供大家参考。
1.reshape的语法
reshape在不更改数组数据的情况下为数组提供新形状,即先将数组拉伸成一维数组,再按order的顺序重组数组维度。
在Python的ndarray和NumPy中都有reshape方法,使用方法类似,仅引用方式不同。其语法格式如下:
numpy.reshape(a, newshape, order='C')
ndarray.reshape( newshape, order='C')
两种语法的不同仅是一个以函数的方式将数组作为一个参数传入,而另一个则是以数组函数的方式调用。
注意:newshape是新数组的形状,必须是整数或整数元组,如(2,3)。
2.NumPy中reshape的经典用法
np.reshape(a, (x, y))
代码如下:
import numpy as np
a = np.arange(1,13) #生成一个12个元素一维数组
b = np.reshape(a,(6,2)) #将12个元素一维数组转换为6x2的二维数组
print(a)
print()运行结果如下:

注意:重组后的数组元素数量必须保证与重组前的元素数量完全相等,否则报错。
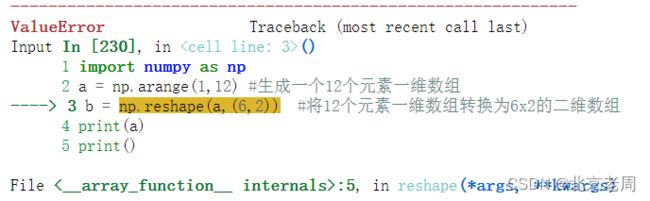
例如以下代码将生成的元素改为11个:
import numpy as np
a = np.arange(1,12) #生成一个11个元素一维数组
b = np.reshape(a,(6,2)) #将12个元素一维数组转换为6x2的二维数组
print(a)
print()运行结果如下(报错):
3.ndarray中reshape的经典用法
a.reshape(x, y)
代码如下:
a = np.arange(1,13) #生成一个12个元素一维数组
b = a.reshape(6,2) #将12个元素一维数组转换为6x2的二维数组
print(a)
print()
print(b)运行结果如下:
对比NumPy中reshape方法的使用可以发现,在ndarray中使用reshape实际上是省略了一层括号,应当是a.reshape((x, y)),在后面可以看到,当使用order参数时必须按照完整格式书写,这种现象在Python中能够经常看到,这也充分说明了Python的灵活性。
4.reshape方法对多维数组的重组方法
由于NumPy和ndarray的语法完全相同,下面将不再分别举例。而且在Python文档中ndarray.reshape也仅是一个简单的文档,连例子都没有,而是让你去参照numpy.reshape的文档(有兴趣可以参见后附的ndarray.reshape原始说明文档)。
当源数组是多维数组的时候,reshape方法先将数组拉伸成为一维数组,然后再按照newshape参数重组为新的多维数组(特殊的情况是newshape=数组元素数量,这时就相当于将多维数组变成了一维数组)。注意:在这里一直强调的是多维数组,虽然我们举的例子都是二维数组,但是一定要清楚,Python是有能力并且可以处理多维数组,ndarray中的nd就是n维的意思。
代码如下:
a = np.arange(1,13) #生成一个12个元素一维数组
b = a.reshape(6,2) #将12个元素一维数组转换为6x2的二维数组
c = b.reshape(3,4) #将6x2的二维数组转换为3x4的二维数组
print(b)
print()
print(c)运行结果如下:

5.newshape参数的特殊用法-1
newshape允许使用-1的特殊参数,表示将剩余元素都分配到那个轴,如(-1,5),在这种情况下,值是根据数组长度和剩余维度推断。
如将上面的代码中c = b.reshape(3,4)改为c = b.reshape(-1,4)或者改为c = b.reshape(3,-1):
b = a.reshape(6,2) #将12个元素一维数组转换为6x2的二维数组
c = b.reshape(-1,4) #将6x2的二维数组转换为3x4的二维数组
print(b)
print()
print(c)运行结果与上面的结果相同。但是,万万不能改成c = b.reshape(-1,5),这时由于3*4的数组是12个元素,不能被5整除,元素数量不匹配,会造成运行错误。-1参数对于我们正常操作一般意义不大,实际上只有数组重组前后的元素数必须相等才能够正确重组数组。
6.order参数
也许order参数本身就是Python的一个Bug,或者是一个程序狂人给广大程序员挖下的一个陷阱,幸亏这个参数用途并不大。
order参数允许选择使用‘C’或者‘F’或者‘A’,其中省略order参数时默认使用‘C’排序。关键是一段晦涩的英文解释让大家不知道三个参数的区别(参见《附1:numpy.reshape原始说明文档》中关于order参数选择的描述)。
我们先用例子来测试一下各参数的运行结果:
x = np.arange(6).reshape((3, 2))
c = np.reshape(x, (2, 3), order='C') # C-like index ordering 这是原始文档中的注释
f = np.reshape(x, (2, 3), order='F') # Fortran-like index ordering 这是原始文档中的注释
a = np.reshape(x, (2, 3), order='A') # A没有举例也没有注释
print('x=',x)
print()
print('c=',c)
print()
print('f=',f)
print()
print('a=',a)我们看一下运行结果

当order='C'时,与省略order时相同,是将源数组拉伸成一维数组(0到5的6个自然数)后再重组成(2,3)的数组。
当order='A'时与order='C'时排列的完全相同。
当order='F'时是怎么排列的?Fortran-like index ordering又是什么鬼?
实际上C-lik index ordering是像C索引那样排序,Fortran-like index ordering是像Fortran索引那样排序,在这里省掉了computer language的描述,是造成大部分人难以理解这里说的是什么。
上述描述确切的翻译过来是像C语言的数组顺序那样排序;像Fortran语言的数组顺序那样排序,这样就很接近答案了。可是又有多少人知道Fortran语言呢?Fortran语言与C语言的数组顺序有什么区别呢?
Fortran语言是一个很古老的编程语言,是IBM公司的约翰·贝克斯(John Backus)于1951年针对汇编语言的缺点研究开发的高级语言,也是世界上第一个计算机高级语言,用于科学和工程计算领域,至今仍然有一些程序员在使用Fortran语言编程,实际上他就像梵文一样是古老而又不可或缺的语言,只是现在已经被边缘化了,连计算机教学中都很少被提到。
Fortran语言的数组与C语言等现在编程语言的排列方式不同,它老人家是按列的顺序排列,而且数组下标是从1开始(C语言的数组下标从0开始,但这与现在讨论的问题无关,在此举例时为了尊敬这个古老的语言才提到此问题),例如一个(3,2)的数组:
在C语言中的索引顺序是从左到右,从上到下: A[0][0], A[0][1], A[1][0], A[1][1], A[2][0], A[2][1]
而在Fortran语言中则是 从上到下,从左到右 : A[1][1], A[2][1], A[3][1], A[1][2], A[2][2], A[3][2]
再次强调:我们在这里看的只是排列顺序,与起始下标无关。
实际上这里的C与F按照Python的惯例应当写成index和columns或者写成axis=0和axis=1。
我们观察一下上面例子中order=‘F’行,可以理解为什么结果是[0 4 3],[2,1,5]了吗?我开始也没有理解,经观察发现,当使用F参数时在拉伸和重组时都要按列进行。
源数组是(3,2)的数组,样式如下:

首先把数组按列拉伸成如下形式:
![]()
然后再按列重组成(2,3)的数组
最后是选项‘A’,原文说的很啰嗦,它的意思就是按照数据在内存中存储的顺序进行排序。我使用的是windows系统,本身就是使用C语言编写的,肯定会按照C选项排序的,也许其它计算机的A排序会有所不同。
7.完整的例子
x = np.arange(6).reshape((3, 2))
c1 = np.reshape(x, (2, 3), order='C') # C-按行的顺序读取数组,拉伸成一维数组后,再按行的顺序重新分配
c2 = np.reshape(np.ravel(x, order='C'), (2, 3)) # 相当于先拉伸成一维数组,再重组成3x2的数组
f1 = np.reshape(x, (2, 3), order='F') # F-按列的顺序读取数组,拉伸成一维数组后,再按列的顺序重新分配
f2 = np.reshape(np.ravel(x, order='F'), (2, 3), order='F')
a = np.reshape(x, (2, 3), order='A') # A-按内存的顺序读取数组,拉伸成一维数组后,再按内存的顺序重新分配(在此同C)
print('x=',x)
print()
print(np.ravel(x, order='C'))
print('c1=',c1)
print('c2=',c2)
print()
print(np.ravel(x, order='F'))
print('f1=',d)
print('f2=',e)
print()
print('a=',a)以下是运行结果

8.总结
ndarray.reshape( newshape, order='C')
numpy.reshape(a, newshape, order='C')
newshape:整数或整数元组,如(2,3)。
- 新形状应与原始形状兼容(元素数相同)。如果新形状的第一维是元素的总数,则结果将是该长度的一维数组。
- 有一个特殊的newshape 是-1,表示将剩余元素都分配到那个轴,如(-1,5),在这种情况下,值是根据数组长度和剩余维度推断。
- 注意:重组后的数组元素数必须保证与重组前完全相等,否则报错。
order : 可选值{'C', 'F', 'A'}。
- 'C'-使用C语言数组的顺序读取元素(按行的顺序读取数组A[0][0], A[0][1], A[0][2]…. ,C语言数组下标从0开始,但与本话题无关),拉伸成一维数组后再重新按行分配;
- 'F'-使用Fortran语言数组的顺序读取元素(按列的顺序读取数组A[1][1], A[2][1], A[3][1]….,Fortran语言数组下标从1开始,但与本话题无关),拉伸成一维数组后再重新按列分配;
- “C”和“F”选项不考虑内存的存储顺序,仅以引用索引顺序为准。
- ‘A’-按照数据在内存中存储的顺序来拉伸成一维数组后再按内存的顺序重新分配。
附1:numpy.reshape原始说明文档
Help on function reshape in module numpy:
reshape(a, newshape, order='C')
Gives a new shape to an array without changing its data.
Parameters
----------
a : array_like
Array to be reshaped.
newshape : int or tuple of ints
The new shape should be compatible with the original shape. If
an integer, then the result will be a 1-D array of that length.
One shape dimension can be -1. In this case, the value is
inferred from the length of the array and remaining dimensions.
order : {'C', 'F', 'A'}, optional
Read the elements of `a` using this index order, and place the
elements into the reshaped array using this index order. 'C'
means to read / write the elements using C-like index order,
with the last axis index changing fastest, back to the first
axis index changing slowest. 'F' means to read / write the
elements using Fortran-like index order, with the first index
changing fastest, and the last index changing slowest. Note that
the 'C' and 'F' options take no account of the memory layout of
the underlying array, and only refer to the order of indexing.
'A' means to read / write the elements in Fortran-like index
order if `a` is Fortran *contiguous* in memory, C-like order
otherwise.
Returns
-------
reshaped_array : ndarray
This will be a new view object if possible; otherwise, it will
be a copy. Note there is no guarantee of the *memory layout* (C- or
Fortran- contiguous) of the returned array.
See Also
--------
ndarray.reshape : Equivalent method.
Notes
-----
It is not always possible to change the shape of an array without
copying the data. If you want an error to be raised when the data is copied,
you should assign the new shape to the shape attribute of the array::
附2:ndarray.reshape原始说明文档
Docstring: a.reshape(shape, order='C') Returns an array containing the same data with a new shape. Refer to `numpy.reshape` for full documentation. See Also -------- numpy.reshape : equivalent function Notes ----- Unlike the free function `numpy.reshape`, this method on `ndarray` allows the elements of the shape parameter to be passed in as separate arguments. For example, ``a.reshape(10, 11)`` is equivalent to ``a.reshape((10, 11))``. Type: builtin_function_or_method